《机器学习》专题
-
 23秋招 顺丰科技机器学习工程师 面经
23秋招 顺丰科技机器学习工程师 面经9.6一面 (30min) 面试官先说流程,一共考察两部分:一,简历上的项目提问+基础知识;二,个人综合素质与沟通交流能力。感觉更注重模型和特征的解释方面,说是因为要经常跟学统计的人打交道和合作。 自我介绍 项目提问,并穿插着问基础,比如讲一下特征选择的方法,特征重要性等等 问懂数理统计吗?讲一下假设检验的流程。特征选择的卡方检验。 碰到给客户解释不清的东西,或者他听不懂,怎么解决? IT领域裁员
-
 23春招 顺丰科技 机器学习工程师 面经
23春招 顺丰科技 机器学习工程师 面经一面: 自我介绍 说一下卡方检验 树的剪枝 GBDT 随机过程 ADASYN(我简历里面写了这个所以才问的) SVM常用核函数 问项目 反问 二面: 自我介绍 GBDT(问的巨细,包括为什么可以用负梯度拟合残差、如果换个loss function还可以用负梯度拟合吗) 拉格朗日插值法具体怎么算的(我简历里面写了这个所以才问的) 回归树用什么损失函数(我回答了一堆分类树的,傻杯了哈哈哈哈) 用三个词
-
 美团机器学习/数据挖掘方向一面面经
美团机器学习/数据挖掘方向一面面经#美团求职进展汇总# #你收到了团子的OC了吗# 美团履约平台技术部,配送时间策略组 自我介绍,问了我学校和清华什么关系 1、上来一道算法题:找最长的回文串。用动态规划dp秒了。然后问怎么优化空间复杂度,想到从两遍同时找最长回文串来做。 2、然后根据简历来问,没想到简历拿错了,没拿我最新更新的简历。让我讲最拿手的项目。我共享屏幕展示了我最新的简历,讲我的SCI科研项目讲了半个小时。 3、问我ten
-
 百度机器学习算法春招一二三面面经
百度机器学习算法春招一二三面面经【一面】 1. word2vec的原理,skip-gram训练的具体流程,使用的损失函数,是怎么选择正负样本的,选择样本上有哪些优化算法,负采样的原理,还有哪些优化方法 2. 贝叶斯调优,机器学习中有哪些优化参数的方法,为什么交叉熵会作为softmax结果的损失函数?梯度下降为什么有效,关于损失求一阶导数为什么有效?刚你提到了泰勒一阶展开,泰勒二阶展开有哪些相关的优化方法呢? 3. SGD的原理,
-
 阿里 高德 机器学习算法实习 一面面经
阿里 高德 机器学习算法实习 一面面经全程50分钟,这次是女面试官,人很好,不怎么拷打,开始时先介绍了面试流程 1.自我介绍 2.介绍第一个项目,我的是一个RAG的项目,吟唱完让我说一下项目的两个亮点,我就介绍了语义感知的文本切分和缓解幻觉的两个点,又提问了一些问题 3.介绍第二个项目,我的是一个论文项目,我直接共享桌面对着模型图讲了一遍,当然中间也穿插着提问,殊不知这次共享有几率让我寄掉 4.问一个基础问题,面试官问了我transf
-
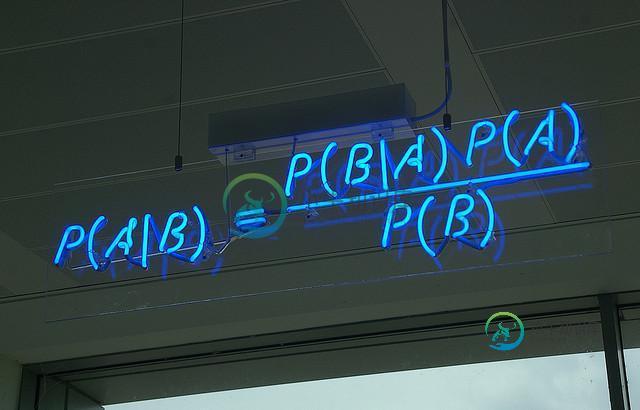 用Python从零实现贝叶斯分类器的机器学习的教程
用Python从零实现贝叶斯分类器的机器学习的教程本文向大家介绍用Python从零实现贝叶斯分类器的机器学习的教程,包括了用Python从零实现贝叶斯分类器的机器学习的教程的使用技巧和注意事项,需要的朋友参考一下 朴素贝叶斯算法简单高效,在处理分类问题上,是应该首先考虑的方法之一。 通过本教程,你将学到朴素贝叶斯算法的原理和Python版本的逐步实现。 更新:查看后续的关于朴素贝叶斯使用技巧的文章“Better Naive Bayes: 12 T
-
随机森林和 GBDT 的学习
参考文献:http://www.zilhua.com/629.html http://www.tuicool.com/articles/JvMJve http://blog.sina.com.cn/s/blog_573085f70101ivj5.html 我的数据挖掘算法:https://github.com/linyiqun/DataMiningAlgorithm 我的算法库:https://g
-
数学随机范围负
如果我做:Math.random() * 4-2 这会让我得到一个范围(-2,2),2是排他性的吗?我认为这是正确的,但我很少得到正数(是的,我知道这是一个随机算法,我们必须无限随机地生成它才能感觉到,但我只是想确保) 新问题 如果我想要所有从-1到1的随机有理数,两个边界都包括在内,那么这条线是否有效:Math.random() * 2.00000000000000001 - 1; 我查了一下,
-
机器学习中有哪些不同的梯度下降算法?
本文向大家介绍机器学习中有哪些不同的梯度下降算法?,包括了机器学习中有哪些不同的梯度下降算法?的使用技巧和注意事项,需要的朋友参考一下 使用梯度下降的背后思想是在各种机器学习算法中将损失降至最低。从数学上讲,可以获得函数的局部最小值。 为了实现这一点,定义了一组参数,并且需要将它们最小化。给参数分配系数后,就可以计算误差或损失。接下来,权重被更新以确保误差最小化。除了参数,弱学习者可以是用户,例如
-
简要说说一个完整机器学习项目的流程?
本文向大家介绍简要说说一个完整机器学习项目的流程?相关面试题,主要包含被问及简要说说一个完整机器学习项目的流程?时的应答技巧和注意事项,需要的朋友参考一下 抽象成数学问题(确定是一个分类问题、回归问题还是聚类问题,明确可以获得什么样的数据) 获取数据(数据要具有代表性,对数据的量级也要有一个评估,多少样本,多少特征,对内存的消耗,考虑内存是否能放得下,如果放不下考虑降维或者改进算法,如果数据量太大
-
哪些机器学习算法不需要做归一化处理?
本文向大家介绍哪些机器学习算法不需要做归一化处理?相关面试题,主要包含被问及哪些机器学习算法不需要做归一化处理?时的应答技巧和注意事项,需要的朋友参考一下 概率模型不需要归一化,因为他们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、RF。而像Adaboost、GBDT、SVM、LR、KNN、KMeans之类的最优化问题就需要归一化
-
在机器学习中,为何要经常对数据归一化?
本文向大家介绍在机器学习中,为何要经常对数据归一化?相关面试题,主要包含被问及在机器学习中,为何要经常对数据归一化?时的应答技巧和注意事项,需要的朋友参考一下 归一化可以: 归一化后加快了梯度下降求最优解的速度(两个特征量纲不同,差距较大时,等高线较尖,根据梯度下降可能走之字形,而归一化后比较圆走直线) 归一化有可能提高精度 (一些分类器需要计算样本之间的距离,如果一个特征值域范围非常大,那么距离
-
如何在Azure机器学习笔记本上安装Jupyter扩展?
我在Azure machine Learning上创建了一个虚拟机,我正在运行一个简单的jupyter笔记本。我想安装jupyter扩展,因为我真的需要可折叠的标题,但它似乎不起作用。我尝试了pip安装,它已经安装,但菜单没有出现。。。
-
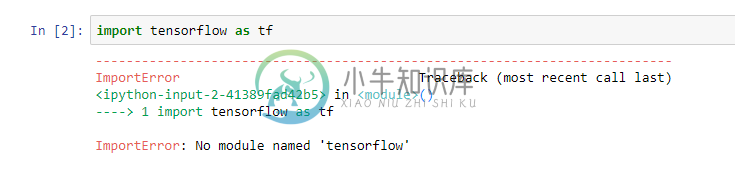 iPython Azure机器学习中缺失的模块拉伸流(经典)
iPython Azure机器学习中缺失的模块拉伸流(经典)昨天,我从Azure机器学习工作室(经典版)的iPython笔记本安装了tensorflow模块。使用(!pip install tensorflow)安装模块后,导入工作正常。但是今天,当我尝试导入这个模块时,出现了“缺少模块”错误,当我尝试重新安装模块时,它运行良好。我有什么遗漏吗?在使用之前,我是否每天都需要安装模块?有人能解释一下吗?
-
 秋招日寄——快手机器学习算法工程师-一面
秋招日寄——快手机器学习算法工程师-一面惯例:自我介绍+讲项目 考察问题: 介绍下transformer(语言组织不好,虽然知道原理但是讲的很乱) 为什么需要multi head attention 介绍下layernorm和batchnorm 为什么layernorm在NLP下有效,batchnorm则不是? pytorch的model.train()和model.eval()的区别 介绍一下集成学习 算法题:二维网格求左上到右下的最