《机器学习》专题
-
机器学习
Python 有着海量的可用于数据分析、统计以及机器学习的库,这使得 Python 成为很多数据科学家所选择的语言。 下面我们列出了一些被广泛使用的机器学习及其他数据科学应用的 Python 包。 Scipy 技术栈 Scipy 技术栈由一大批在数据科学中被广泛使用的核心辅助包构成,可用于统计分析与数据可视化。由于其丰富的功能和简单易用的特性,这一技术栈已经被视作实现大多数数据科学应用的必备品了。
-
机器学习
主要内容 前言 课程列表 推荐学习路线 数学基础初级 程序语言能力 机器学习课程初级 数学基础中级 机器学习课程中级 推荐书籍列表 机器学习专项领域学习 致谢 前言 我们要求把这些课程的所有Notes,Slides以及作者强烈推荐的论文看懂看明白,并完成所有的老师布置的习题,而推荐的书籍是不做要求的,如果有些书籍是需要看完的,我们会进行额外的说明。 课程列表 课程 机构 参考书 Notes等其他资
-
机器学习
机器学习与人工智能学习笔记,包括机器学习、深度学习以及常用开源框架(Tensorflow、PyTorch)等。 机器学习算法 _图片来自scikit-learn_。 机器学习全景图 _图片来自http://www.shivonzilis.com/_。
-
 机器学习
机器学习机器学习与人工智能学习笔记,包括机器学习、深度学习以及常用开源框架(Tensorflow、PyTorch)等。
-
Azure机器学习
我已经找了几个小时了,但找不到一个能回答这个问题的东西。我已经创建并发布了一个新的Azure机器学习服务,并创建了一个endpoint。我可以使用Postman REST客户机调用服务,但是通过JavaScript网页访问它会返回一个控制台日志,说明该服务启用了CORS。现在,对于我来说,我想不出如何为Azure机器学习服务禁用CORS。如有任何帮助,不胜感激,谢谢!
-
8. 机器学习
@subpage tutorial_py_knn_index_cn 学习使用kNN分类器。 同时学习编写一个基于kNN的手写字符识别程序。 @subpage tutorial_py_svm_index_cn 理解SVM的概念。 @subpage tutorial_py_kmeans_index_cn 学习使用K-Means聚类将数据分组到多个集合中。 另外我们会学习使用K-Means聚类进行颜色量
-
 AiLearning 机器学习
AiLearning 机器学习机器学习(Machine Learning,ML) 是使用计算机来彰显数据背后的真实含义,它为了把无序的数据转换成有用的信息。是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。 源代码:https://www.wenjiangs.com/wp-content/uploads/2022/09/src.zip
-
 Python 机器学习
Python 机器学习机器学习是一门研究如何使用计算机模拟人类行为,以获取新的知识与技能的学科。它是人工智能的核心,同时也是处理大数据的关键技术之一。机器学习的主要目标是自动地从数据中发现价值的模式,亦即将原始信息自动转换为人们可以加以利用的知识。
-
机器学习:集成学习
“三个臭皮匠顶个诸葛亮”。集成学习就是利用了这样的思想,通过把多分类器组合在一起的方式,构建出一个强分类器;这些被组合的分类器被称为基分类器。事实上,随机森林就属于集成学习的范畴。通常,集成学习具有更强的泛化能力,大量弱分类器的存在降低了分类错误率,也对于数据的噪声有很好的包容性。
-
机器学习:使用Python - 简介Scikit-learn 机器学习
Scikit-learn 套件的安装 目前Scikit-learn同时支持Python 2及 3,安装的方式也非常多种。对于初学者,最建议的方式是直接下载 Anaconda Python (https://www.continuum.io/downloads)。同时支持 Windows / OSX/ Linux 等作业系统。相关数据分析套件如Scipy, Numpy, 及图形绘制库 matplot
-
 机器学习和深度学习
机器学习和深度学习主要内容:机器学习,深度学习,机器学习与深度学习的区别,机器学习和深度学习的应用人工智能是近几年来最流行的趋势之一。机器学习和深度学习构成了人工智能。下面显示的维恩图解释了机器学习和深度学习的关系 - 机器学习 机器学习是让计算机按照设计和编程的算法行事的科学艺术。许多研究人员认为机器学习是实现人类AI的最佳方式。机器学习包括以下类型的模式 - 监督学习模式 无监督学习模式 深度学习 深度学习是机器学习的一个子领域,其中有关算法的灵感来自大脑的结构和功能,称为人工神经网络。
-
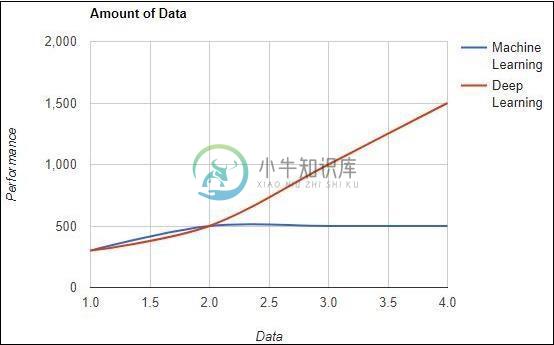 机器学习与深度学习
机器学习与深度学习主要内容:数据量,硬件依赖,特色工程在本章中,我们将讨论机器和深度学习概念之间的主要区别。 数据量 机器学习使用不同数量的数据,主要用于少量数据。另一方面,如果数据量迅速增加,深度学习可以有效地工作。下图描绘了机器学习和深度学习在数据量方面的工作 - 硬件依赖 与传统的机器学习算法相反,深度学习算法设计为在很大程度上依赖于高端机器。深度学习算法执行大量矩阵乘法运算,这需要巨大的硬件支持。 特色工程 特征工程是将领域知识放入指定特征的
-
机器学习算法
Index 基本遵从《统计学习方法》一书中的符号表示。 除特别说明,默认w为行向量,x为列向量,以避免在wx 中使用转置符号;但有些公式为了更清晰区分向量与标量,依然会使用^T的上标,注意区分。 输入实例x的特征向量记为: 注意:x_i 和 x^(i) 含义不同,前者表示训练集中第 i 个实例,后者表示特征向量中的第 i 个分量;因此,通常记训练集为: 特征向量用小n表示维数,训练集用大N表示个数
-
机器学习实践
Reference CS229 课程讲义(中文) - Kivy-CN - GitHub 超参数选择 Grid Search 网格搜索 在高维空间中对一定区域进行遍历 Random Search 在高维空间中随机选择若干超参数 相关库(未使用) Hyperopt 用于超参数优化的 Python 库,其内部使用 Parzen 估计器的树来预测哪组超参数可能会得到好的结果。 GitHub - https
-
机器学习基础
偏差与方差 《机器学习》 2.5 偏差与方差 - 周志华 偏差与方差分别是用于衡量一个模型泛化误差的两个方面; 模型的偏差,指的是模型预测的期望值与真实值之间的差; 模型的方差,指的是模型预测的期望值与预测值之间的差平方和; 在监督学习中,模型的泛化误差可分解为偏差、方差与噪声之和。 偏差用于描述模型的拟合能力; 方差用于描述模型的稳定性。 导致偏差和方差的原因 偏差通常是由于我们对学习算法做了错