《解释器》专题
-
Pygame碰撞解释
我是蟒蛇/蟒蛇游戏的新手。我已经能够在小型测试程序中拼凑出一些东西,但试图掌握碰撞并没有发生。我尝试过学习多个教程,但我觉得我需要它完全分解,然后才能很好地理解它。 有人能解释一下像CollidRect(Rect)这样的东西是如何工作的吗?我需要一个碰撞函数的类,还是只需要两个矩形就可以得到结果? 我尝试使用的代码如下。我能够制作两个图像,每个图像都由一个矩形包围,我假设碰撞仅适用于精灵而不是图像
-
Drools属性解释
我有一个关于2个Drools属性的问题-显著性和无循环 我理解这个属性阻止了一个规则被执行到相同的事实,这将导致无限循环。我的问题是关于一个我不太明白的关于这个属性的例子: 如果没有“无循环”,为什么会导致无限循环?
-
13、名词解释
名词解释 点击次数:投放广告被点击的次数; 点击设备数:投放广告被点击的排重数(依据设备信息); 激活次数:应用首次联网打开的次数; 激活设备数:应用首次联网打开的排重数(依据设备信息); 注册次数:发生注册行为的次数; 注册设备数:注册成功事件的设备数; 登录次数:发生登录行为的次数; 登录设备数:登录成功事件的设备数; DAU:打开应用的设备数; MAU:最近30天内(含当天)启动应用的设备数
-
AST 解释执行
语法和语义分析的结果是抽象语法树AST,再往后编译原理还有代码生成及优化的很大一部分,但如果只是做一个执行器,到AST为止就可以解释执行了,当然就算不生成AST,解析执行也可以,只是基于之前说过的原因,极少采用解析执行的方式 目前的大多数解释执行的语言,都是在虚拟机解释字节码执行,这个后面再说,它只是把AST的解释串行化了而已,事实上ruby在1.9版本之前是解释AST执行的,到1.9整合了YAR
-
WEB SERVICE名词解释,JSWDL开发包的介绍,JAXP、JAXM的解释。SOAP、UDDI,WSDL解释。
本文向大家介绍WEB SERVICE名词解释,JSWDL开发包的介绍,JAXP、JAXM的解释。SOAP、UDDI,WSDL解释。相关面试题,主要包含被问及WEB SERVICE名词解释,JSWDL开发包的介绍,JAXP、JAXM的解释。SOAP、UDDI,WSDL解释。时的应答技巧和注意事项,需要的朋友参考一下 考察点:web service 参考回答: Web ServiceWeb Servi
-
静态编译Python解释器?
问题内容: 我正在构建一个专用的嵌入式Python解释器,并希望避免依赖于动态库,因此我想改用静态库来编译解释器(例如,不编译)。 我还想静态链接Python标准库中所有的动态库。我知道可以使用来完成此操作,但是有没有一种替代方法可以一步完成呢? 问题答案: 我发现了这一点(主要是关于Python模块的静态编译): http://bytes.com/groups/python/23235-buil
-
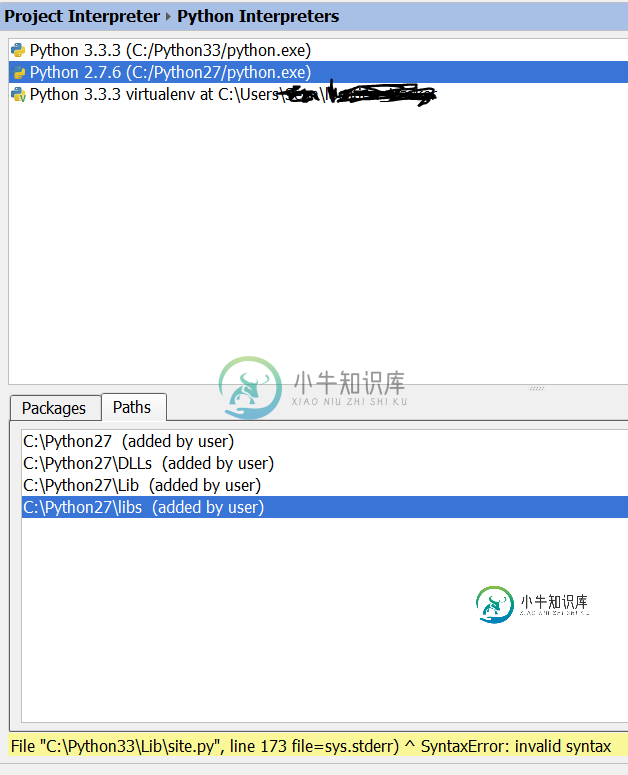 Multilpe python版本和解释器
Multilpe python版本和解释器问题内容: 我试图在Windows 7计算机上设置python 2.7.6(首先安装了python 3.3.3)。将项目解释器添加到settings- project解释器后,选择项目解释器时,出现此错误 文件“ C:\ Python33 \ Lib \ site.py”,行173 file = sys.stderr)^ SyntaxError:语法无效 最初在设置页面中添加python 2.7解
-
Node.js REPL(交互式解释器)
Node.js REPL(Read Eval Print Loop:交互式解释器) 表示一个电脑的环境,类似 Window 系统的终端或 Unix/Linux shell,我们可以在终端中输入命令,并接收系统的响应。 Node 自带了交互式解释器,可以执行以下任务: 读取 - 读取用户输入,解析输入了Javascript 数据结构并存储在内存中。 执行 - 执行输入的数据结构 打印 - 输出结果
-
解释对偶概念?
本文向大家介绍解释对偶概念?相关面试题,主要包含被问及解释对偶概念?时的应答技巧和注意事项,需要的朋友参考一下 一个优化问题可以从两个角度进行考察,一个是primal问题,一个是dual问题,就是对偶问题,一般情况下对偶问题给出主问题最优值的下界,在强对偶性成立的情况下由对偶问题可以得到主问题的最优下界,对偶问题是凸优化问题,可以进行较好的求解,SVM中就是将主问题转换为对偶问题进行求解,从而引入
-
(![] + [])[+ []]…解释为何有效
问题内容: 该代码的输出为:。为什么? 顺便说一句,对吗?但是为什么和为什么呢? 问题答案: 正如@Mauricio所评论的是“ f”(“ false”的第一个字符),“ a”等,等等。 它是如何工作的? 让我们检查第一个字符“ f”: 表达式的第一部分(括号之间)由组成,加法运算符的第一个操作数是,它将产生,因为数组对象(与任何其他Object实例一样)是 真实的 ,并且应用Logical(!)
-
解释Apache Kafka用例?
本文向大家介绍解释Apache Kafka用例?相关面试题,主要包含被问及解释Apache Kafka用例?时的应答技巧和注意事项,需要的朋友参考一下 答:Apache Kafka有很多用例,例如: Kafka指标 可以使用Kafka进行操作监测数据。此外,为了生成操作数据的集中提要,它涉及到从分布式应用程序聚合统计信息。 Kafka日志聚合 从组织中的多个服务收集日志。 流处理 在流处理过程中,
-
解释术语“Log Anatomy”
本文向大家介绍解释术语“Log Anatomy”相关面试题,主要包含被问及解释术语“Log Anatomy”时的应答技巧和注意事项,需要的朋友参考一下 答:我们将日志视为分区。基本上,数据源将消息写入日志。其优点之一是,在任何时候,都有一个或多个消费者从他们选择的日志中读取数据。下面的图表显示,数据源正在写入一个日志,而用户正在以不同的偏移量读取该日志。
-
请解释一下TreeMap?
本文向大家介绍请解释一下TreeMap?相关面试题,主要包含被问及请解释一下TreeMap?时的应答技巧和注意事项,需要的朋友参考一下 考察点:key-value集合 TreeMap是一个有序的key-value集合,基于红黑树(Red-Black tree)的 NavigableMap实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator进行排序,具体取决于使用的
-
解释'find -mtime'命令
问题内容: 我正在尝试删除除最近的日志以外的所有日期日志。在执行脚本删除文件之前,我当然想测试命令以确保获得正确的结果。 执行这些命令时,日期为: 目录清单: 我以为-mtime +1应该列出一天之内的所有文件。为什么没有列出8-30.log? 这是理想的效果,但这只是反复试验。0在说什么? 问题答案: find的POSIX规范说: 如果从初始化时间中减去的文件修改时间除以86400(任何剩余部分
-
谁能解释我StandardScaler?
问题内容: 我无法理解网页的的文档中。 谁能简单地向我解释一下? 问题答案: 背后的想法是它将转换您的数据,使其分布的平均值为0,标准差为1。 对于多变量数据,这是按功能进行的(换句话说,独立于数据的每一列) 。 给定数据的分布,数据集中的每个值都将减去平均值,然后除以整个数据集(或多变量情况下的特征)的标准差。