《解释器》专题
-
REPL (交互式解释器)
稳定性: 2 - 稳定的 repl 模块提供了一种 读取-求值-输出 循环(REPL)的实现,它可作为一个独立的程序或嵌入到其他应用中。 可以通过以下方式使用它: const repl = require('repl'); 设计与特性 repl 模块导出了 repl.REPLServer 类。 当 repl.REPLServer 实例运行时,它接收用户输入的每一行,根据用户定义的解释函数解释这些
-
设计模式 - 解释器
解释器(Interpreter) Intent 为语言创建解释器,通常由语言的语法和语法分析来定义。 Class Diagram TerminalExpression:终结符表达式,每个终结符都需要一个 TerminalExpression。 Context:上下文,包含解释器之外的一些全局信息。 Implementation 以下是一个规则检验器实现,具有 and 和 or 规则,通过规则可以构
-
编译器与解释器
那么,让我看看我是否明白了这一点。 > 当我们说编译器和解释器之间的区别时,解释器将高级指令翻译成中间形式,然后执行。[我认为编译器也将高级指令翻译成中间形式,但此刻它生成目标代码而不是执行它,对吗?] 解释器一次读取一条指令或一行的源代码,将该行转换为机器代码并执行它。[解释器本身不会将代码转换为机器代码,它会使用ist自己的预编译函数评估指令(在解析之后)。例如,高级语言中的Add表达式将使用
-
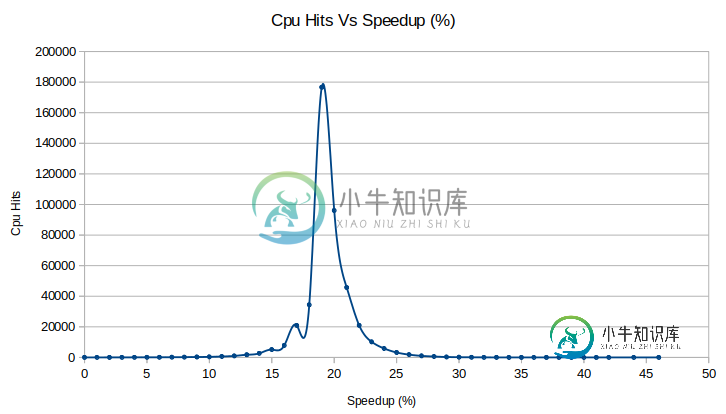 处理器行为解释
处理器行为解释问了这个问题后,我很困惑,于是决定为一个C编译器程序构建类似的测试。这是我的代码: 使用选项在GCC下编译 测试代码被更改,这样错误值只能在运行时知道(而不能在编译时知道),这样GCC优化器就不能删除循环的代码。 我们应该期待CPU的加速吗?(正如GCC编译程序预测的那样)
-
2. 使用 Python 解释器
2.1. 调用 Python 解释器 Python 解释器通常被安装在目标机器的 /usr/local/bin/python3.4 目录下。 将 /usr/local/bin 目录包含进 Unix shell 的搜索路径里,以确保可以通过输入: python3.4 命令来启动他。 [1] 由于 Python 解释器的安装路径是可选的,这也可能是其它路径,你可以联系安装 Python 的用户或系统
-
解释器模式( Interpreter Pattern)
解释器模式提供了一种评估语言语法或表达的方法。 这种模式属于行为模式。 此模式涉及实现表达式接口,该接口用于解释特定上下文。 此模式用于SQL解析,符号处理引擎等。 实现 (Implementation) 我们将创建一个接口Expression和实现Expression接口的具体类。 定义了一个类TerminalExpression ,它充当相关上下文的主要解释器。 其他类OrExpression
-
交互式解释器(REPL)
读取(Read)-运算(Eval)-输出(Print)-循环(Loop) (REPL) 是一个简单的, 交互式的计算机编程环境,它采用单个用户输入(即单个表达式),运算并返回结果给用户。 主进程 Electron 通过 --interactive 命令行参数将 Node.js repl 模块暴露出去。 假设你已将 electron 安装为本地项目依赖,则应能够使用下面的命令访问 REPL: ./n
-
解释jstat结果
问题内容: 我是jstat工具的新手。因此,我做了如下示例。 结果表明什么?哪些列需要注意可能的内存问题,例如内存泄漏等。 问题答案: 请参阅文档: https://docs.oracle.com/javase/8/docs/technotes/tools/unix/jstat.html 基本上,一行是一个时间点。这些列显示了有关JVM内存区域(Survivor,Eden等)的数据,如果不了解JV
-
用JavaScript解释[] .slice.call?
问题内容: 我偶然发现了将DOM NodeList转换为常规数组的简洁捷径,但我必须承认,我并不完全了解它的工作原理: 因此,它以一个空数组开头,然后用于将结果转换为新数组,是吗? 我不明白的是。它如何从NodeList转换为常规数组? 问题答案: 这里发生的是,您调用它就像是使用的功能。在这种情况下,要做的是创建一个空数组,然后遍历其运行的对象(最初是一个数组,现在是一个数组),并将该对象的元素
-
对context.xml的解释
在使用Tomcat时,我一直将视为或的等价物。似乎很自然,可能必须有某种方法来配置web服务器。 但是,我不太理解的用途。例如,在使用JDBC时,为什么必须在中添加,并在中添加包含更多信息的?我可以删除文件并在代码中实例化吗?我问是因为像这样的假设例子有助于我理解。 为什么我必须把这两个都放在那里才能使用JDBC?它们到底在做什么,除了在Java代码中,还有其他方法可以做同样的事情吗?就像我说的,
-
 Azure公钥解释?
Azure公钥解释?我正在更新我的应用程序,以便将Azure Active Directory用作OAuth 2.0身份验证服务器。目前,我正在成功地使用授权代码授予类型,并收到access_token和id_token值。 现在,我正在尝试验证返回的id_令牌。我正在遵循doco中概述的步骤,并且我能够找到用于签署JWT的公钥。例如,这是Azure RESTendpoint返回的记录 据我所知,这些是可用的公钥。我
-
解释jstat结果
我不熟悉jstat工具。因此,我做了如下样本。 这个结果表明了什么?哪些列需要注意可能的内存问题,例如内存泄漏等。
-
解释java.lang.NoSuchmetodError消息
我得到以下运行时错误消息(以及堆栈跟踪的第一行,它指向第94行)。我试图弄明白为什么它说不存在这样的方法。 第94行如下所示。 为什么括号里有四种类型(ILcom/sun/javadoc/ClassDoc; Lcom/sun/javadoc/MemberDoc; Ljava/lang/String; Z),括号后面有一种类型Ljava/lang/String;当方法printDocLinkForM
-
解释迈克尔
我在研究Michael 但我在我的代码中产生了一个竞赛,并认为算法中可能存在竞赛。 我在这里阅读了论文:简单、快速和实用的非阻塞和阻塞并发队列算法,原始的取消排队伪代码如下: 在我看来,比赛是这样的: < li >线程1前进到D3,然后停止。 < li >线程2前进到D3,读取与线程1相同的磁头。 < li >线程2幸运地一直前进到D20,在D19它释放了head.ptr < li >线程1继续前
-
节点解释树
不知道根据站点的规则我是否被允许这么做...但我会抓住机会...请你忍耐一下,我只是个学生...:-) 我有个大学作业...我很难理解类应该做什么。我曾三次去找我的老师,他给我的答案一点帮助也没有。总之,分配的详细信息如下所示... 创建一个名为的类,它充当节点的容器。树类应该支持以下方法。 public void add(Node parent,Node child){}--向父节点添加新的子节