《dom》专题
-
使用Axonframework基于特定事件从domainevententry表中检索数据
-
 Jsoup 使用DOM解析HTML
Jsoup 使用DOM解析HTML主要内容:Jsoup 使用DOM解析HTML 语法,Jsoup 使用DOM解析HTML 说明,Jsoup 使用DOM解析HTML 示例以下示例将展示在将 HTML 字符串解析为 Document 对象后如何使用类似 DOM 的方法。 Jsoup 使用DOM解析HTML 语法 document : 文档对象代表 HTML DOM。 Jsoup : 解析给定 HTML 字符串的主类。 html : HTML 字符串。 sampleDiv : 元素对象表示由 id“sampleDiv”标识的 html
-
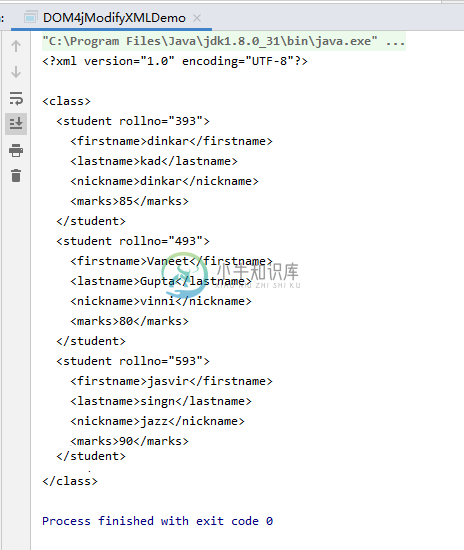 Java DOM4J解析器 修改XML文档
Java DOM4J解析器 修改XML文档主要内容:Java DOM4J解析器 修改XML文档的示例Java DOM4J解析器 修改XML文档的示例 需要修改的文件内容如下: 编写Java DOM4J解析器 修改XML文档的程序 输出结果为:
-
 Java DOM4J解析器 创建XML文档
Java DOM4J解析器 创建XML文档主要内容:Java DOM4J解析器 创建XML文档的示例Java DOM4J解析器 创建XML文档的示例 需要生成的文件内容如下: 编写Java DOM4J解析器 创建XML文档的程序 输出结果为:
-
 Java DOM4J解析器 查询XML文档
Java DOM4J解析器 查询XML文档主要内容:Java DOM4J解析器 查询XML文档的示例Java DOM4J解析器 查询XML文档的示例 需要解析的文件input.xml 编写Java DOM4J解析器 查询XML文档的程序 输出结果为:
-
 Java DOM4J解析器 解析XML文档
Java DOM4J解析器 解析XML文档主要内容:Java DOM4J解析器 解析XML文档的步骤,Java DOM4J解析器 解析XML文档的示例Java DOM4J解析器 解析XML文档的步骤 以下是使用 DOM4J Parser 解析文档时使用的步骤。 导入与 XML 相关的包。 创建一个 SAXReader。 从文件或流创建文档。 通过调用 document.selectNodes() 使用 XPath 表达式获取所需的节点 提取根元素。 迭代节点列表。 检查属性。 检查子元素。 导入 XML 相关的包 创建一个文档生成器 从
-
Java DOM4J解析器 介绍
主要内容:什么是DOM4J解析器,DOM4J解析器的环境设置,DOM4J解析器的应用场景,使用DOM4J解析器,你得到什么?,DOM4J解析器的好处,DOM4J 类,常见的 DOM4J 方法什么是DOM4J解析器 DOM4J 是一个开源的、基于 Java 的库,用于解析 XML 文档。它是一个高度灵活且内存高效的 API。它是 Java 优化的,并使用了像 List 和 Arrays 这样的 Java 集合。 DOM4J 适用于 DOM、SAX、XPath 和 XSLT。它可以以非常低的内存占用
-
 Java DOM解析器 修改XML文档
Java DOM解析器 修改XML文档主要内容:Java DOM解析器 修改XML文档的示例Java DOM解析器 修改XML文档的示例 修改前的文件input.xml: 修改XML文档的程序 以上程序执行后,控制台输入以下内容:
-
 Java DOM解析器 创建XML文档
Java DOM解析器 创建XML文档主要内容:Java DOM解析器 创建XML文档的示例Java DOM解析器 创建XML文档的示例 执行以上程序后,控制台输出结果为 在D盘根目录下生成了cars.xml文件,内容如下:
-
 Java DOM解析器 查询XML文档
Java DOM解析器 查询XML文档主要内容:Java DOM解析器 查询XML文档的示例Java DOM解析器 查询XML文档的示例 项目结构如下: input.xml文件: QueryXmlFileDemo解析程序 输出结果为:
-
 Java DOM解析器 解析XML文档
Java DOM解析器 解析XML文档主要内容:Java DOM解析器 解析XML文档的步骤,Java DOM解析器 解析XML文档的示例Java DOM解析器 解析XML文档的步骤 以下是使用 DOM解析器 解析文档时使用的步骤。 导入与 XML 相关的包。 创建一个文档生成器。 从文件或流创建文档 提取根元素 检查属性 检查子元素 导入 XML 相关的包 创建一个文档生成器 从文件或流创建文档 提取根元素 检查属性 检查子元素 Java DOM解析器 解析XML文档的示例 项目结构如下: input.xml文件: DomPars
-
Java DOM解析器 介绍
主要内容:什么是DOM解析器,DOM解析器的应用场景,使用DOM解析器可以获取什么,DOM解析器的好处,常见的DOM解析器接口,常用的DOM解析器方法什么是DOM解析器 文档对象模型 (DOM) 是万维网联盟 (W3C) 的官方建议。它定义了一个接口,使程序能够访问和更新 XML 文档的样式、结构和内容。支持 DOM 的 XML 解析器实现了这个接口。 DOM解析器的应用场景 您在以下情况下可以使用 DOM 解析器 : 您需要获取文档结构数据。 您需要移动 XML 文档的各个部分(例如,您可能想
-
使用react-router-dom重定向到第三方URL
问题内容: 我非常了解我想对组件进行条件渲染的react-router-dom。如果未登录use,则将他重定向到某个第三方URL 例如,下面的代码看起来很整洁,可以正常工作 让我们在上面的示例中说,如果我想重定向 https://www.google.com, 该怎么做? 如果我写 如何重定向到第三方网站? 问题答案: 您可以将标记用于外部网址, 但您也可以提供这样的组件:
-
Java XML DOM:id属性有何特殊之处?
问题内容: 该类的Javadoc 在下有以下注释。 注意:除非如此定义,否则名称为“ ID”或“ id”的属性不是ID类型的 因此,我将XHTML文档读入DOM(使用Xerces 2.9.1)。 该文档中有一个普通的旧文档。 我叫,它返回null。 我使用XPath来获取“ // * [id =’fribble’]”,一切都很好。 因此,问题是,是什么导致实际将ID属性标记为“如此定义”? 问题答
-
正则表达式以检索domain.tld
问题内容: 我需要Java中的正则表达式,可用于从任何URL检索domain.tld部分。所以https://foo.com/bar,HTTP://www.foo.com#bar,http://bar.foo.com都会返回foo.com。 我写了这个正则表达式,但它与整个网址匹配 我不确定我是否匹配“。” 角色权利。我试过了 ”。” 但是我从netbeans收到一个错误。 更新: tld不限于2