《模型》专题
-
CoffeeScript模块的模式
问题内容: 在Github上查看CoffeeScript的源代码时,我注意到大多数(如果不是全部)模块定义如下: 这种模式看起来像是将整个模块包装在一个匿名函数中并调用自身。 这种方法的优点(和缺点)是什么?还有其他方法可以实现相同的目标吗? 问题答案: Harmen的答案是相当不错的,但让我详细说明一下CoffeeScript编译器在何处完成此操作以及原因。 当您使用编译内容时,总会得到如下所示
-
模板方法模式
亦称: Template Method 意图 模板方法模式是一种行为设计模式, 它在超类中定义了一个算法的框架, 允许子类在不修改结构的情况下重写算法的特定步骤。 问题 假如你正在开发一款分析公司文档的数据挖掘程序。 用户需要向程序输入各种格式 (PDF、 DOC 或 CSV) 的文档, 程序则会试图从这些文件中抽取有意义的数据, 并以统一的格式将其返回给用户。 该程序的首个版本仅支持 DOC 文
-
模板方法模式
一、定义 模板方法是基于继承的设计模式,可以很好的提高系统的扩展性。 java中的抽象父类、子类 模板方法有两部分结构组成,第一部分是抽象父类,第二部分是具体的实现子类。 二、示例 Coffee or Tea (1) 把水煮沸 (2) 用沸水浸泡茶叶 (3) 把茶水倒进杯子 (4) 加柠檬 /* 抽象父类:饮料 */ var Beverage = function(){}; // (1) 把水煮沸
-
模板 - 应用模板
英文原文:http://emberjs.com/guides/application/the-application-template/ 应用模板是应用启动的时候默认渲染的模板。 你应该把你的header、footer和其他装饰性的内容放在应用模板里面。另外,应用模版中至少需要一个{{outlet}}占位符,以便路由能根据当前的URL将适当的模版渲染进来。 下面是一个应用模板的例子: 1 2 3
-
模板方法模式
问题 定义一个算法的结构,作为一系列的高层次的步骤,使每一个步骤的行为可以指定,使属于一个族的算法都具有相同的结构但是有不同的行为。 解决方案 使用模板方法( Template Method )在父类中描述算法的结构,再授权一个或多个具体子类来具体地进行实现。 例如,想象你希望模拟各种类型的文件的生成,并且每个文件要包含一个标题和正文。 class Document produceDocu
-
模版方法模式
简介 模板方法模式定义了一个算法的步骤,并允许子类别为一个或多个步骤提供其实践方式。让子类别在不改变算法架构的情况下,重新定义算法中的某些步骤。在软件工程中,它是一种软件设计模式,和C++模板没有关连。 实例 事实上,模版方法是编程中一个经常用到的模式。先来看一个例子,某日,程序员A拿到一个任务:给定一个整数数组,把数组中的数由小到大排序,然后把排序之后的结果打印出来。经过分析之后,这个任务大体上
-
模块 / 模块的__name__
每个模块都有一个名称,在模块中可以通过语句来找出模块的名称。这在一个场合特别有用——就如前面所提到的,当一个模块被第一次输入的时候,这个模块的主块将被运行。假如我们只想在程序本身被使用的时候运行主块,而在它被别的模块输入的时候不运行主块,我们该怎么做呢?这可以通过模块的__name__属性完成。 使用模块的__name__ 例8.2 使用模块的__name__ #!/usr/bin/python
-
模板模式( Template Pattern)
在模板模式中,抽象类公开定义的方式/模板以执行其方法。 它的子类可以根据需要覆盖方法实现,但调用的方式与抽象类的定义相同。 此模式属于行为模式类别。 实现 (Implementation) 我们将创建一个Game抽象类,定义操作,模板方法设置为final,以便不能覆盖它。 Cricket和Football是扩展Game并覆盖其方法的具体类。 我们的演示类TemplatePatternDemo将使用
-
javascript设计模式之module(模块)模式
本文向大家介绍javascript设计模式之module(模块)模式,包括了javascript设计模式之module(模块)模式的使用技巧和注意事项,需要的朋友参考一下 模块是任何强大应用程序中不可或缺的一部分,它通常能帮助我们清晰地分离和组织项目中的代码单元。 js中实现模块的方法: 1.对象字面量表示法 2.Module模式 3.AMD模块 4.CommonJS模块 5.ECMAS
-
JavaScript设计模式:模块模式和显示模块模式之间的区别?
问题内容: 我最近正在读《 学习JavaScript设计模式》 这本书。我没有得到的是模块模式和显示模块模式之间的区别。我觉得他们是同一回事。有人可以举一个例子吗? 问题答案: 至少有三种不同的方法来实现模块模式,但是显示模块模式是唯一具有正式名称的模块模式后代。 基本模块模式 模块模式必须满足以下条件: 私有成员住在封闭中。 公共成员暴露在返回对象中。 但是这个定义有很多歧义。通过以不同方式解决
-
Nosql模型结构
问题内容: 您将如何构建Cloud Firestore数据库。 我收藏了团队,竞技场和游戏: 在游戏中,团队可以是主队也可以是客队,而游戏始终具有竞技场。 因此,目前我的想法是将所有比赛都纳入“游戏”收藏夹,当我想查找某个团队的所有游戏时,我需要查询“游戏”收藏夹并查找所有选定球队是主队还是客队的比赛。 我应该在Firestore生成的ID处引用团队吗?还是应该输入团队名称?我可以从中获得更多关于
-
部署Keras模型
问题内容: 我部署了一个keras模型,并通过flask API将测试数据发送到该模型。我有两个文件: 首先:My Flask应用程序: 第二:文件Im用于将json数据发送到api端点: 我从Flask收到有关Tensorflow的回复: ValueError:Tensor Tensor(“ dense_6 / BiasAdd:0”,shape =(?, 1),dtype = float32)不
-
Cassandra数据模型
主要内容:群集,键空间,Cassandra数据模型规则,数据建模目标Cassandra中的数据模型与RDBMS中正常情况完全不同。 我们来看看Cassandra如何存储数据。 群集 Cassandra数据库分布在运行的几(多)台机器上。 最外层的容器被称为包含不同节点的群集。 每个节点都包含一个副本,如果发生故障,副本将负责顶上。 Cassandra将节点以环形格式排列在群集中,并为其分配数据。 键空间 键空间(Keyspace)是Cassandra中数据的最外层
-
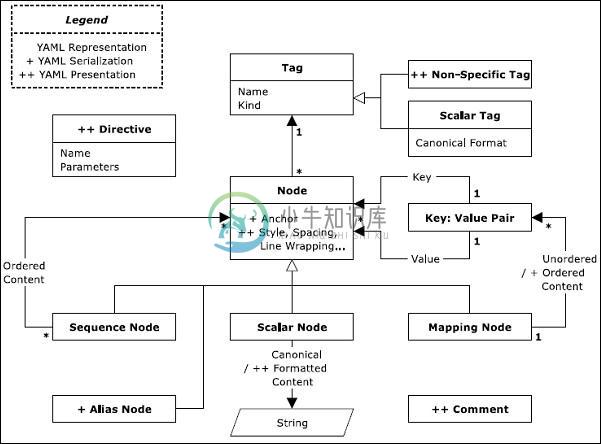 YAML信息模型
YAML信息模型本章将解释在上一章中讨论的程序和过程的详细信息。 YAML中的信息模型将使用特定图表以系统格式指定序列化和表示过程的功能。 对于信息模型,重要的是表示在编程环境之间可移植的应用程序信息。 上面的图表表示以图形格式表示的正常信息模型。 在YAML中,本机数据的表示是根,连接的并且是标记节点的有向图。有向图包括一组带有有向图的节点。 如信息模型中所述,YAML支持三种节点 - 序列 标量 映射 上一章
-
 MongoDB数据模型
MongoDB数据模型主要内容:数据模型设计,嵌入式数据模型,规范化数据模型在 MongoDB 中存储数据非常灵活,它与关系型数据库完全不同,在关系型数据库中,插入数据之前必须先确定数据表的结构并创建数据表。而 MongoDB 中对文档的结构没有强制要求,只要合理即可。 数据模型设计 MongoDB 提供了两种数据模型,分别是嵌入式数据模型和规范化数据模型,您可以根据需要使用其中的任何一种。 在 MongoDB 中模型设计需要注意以下几点: 要根据具体的项目需求来选择合适