《架构思维》专题
-
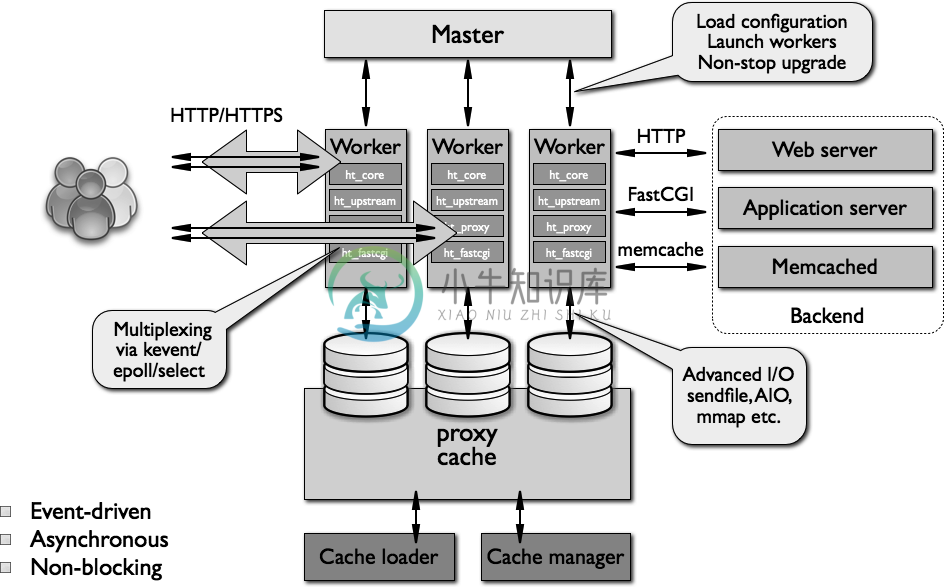 Nginx架构
Nginx架构主要内容:代码结构,工作模式,nginx进程角色,nginx缓存简介处理并发连接的传统的基于进程或线程的模型涉及使用单独的进程或线程处理每个连接,并阻止网络或输入/输出操作。 根据应用,在内存和CPU消耗方面可能非常低效。 产生一个单独的进程或线程需要准备一个新的运行时环境,包括分配堆和堆栈内存,以及创建新的执行上下文。 额外的CPU时间也用于创建这些项目,这可能会导致由于线程在过多的上下文切换上的转机而导致性能下降。 所有这些并发症都表现在较老的Web服务器架构
-
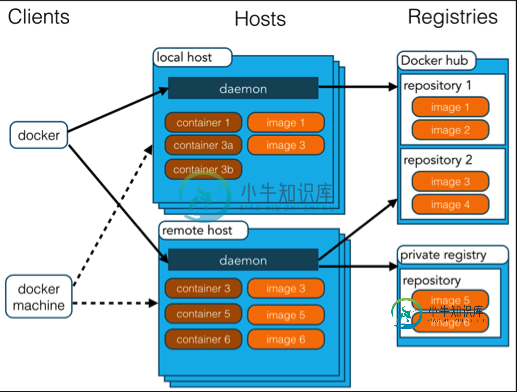 Docker 架构
Docker 架构Docker 包括三个基本概念: 镜像(Image):Docker 镜像(Image),就相当于是一个 root 文件系统。比如官方镜像 ubuntu:16.04 就包含了完整的一套 Ubuntu16.04 最小系统的 root 文件系统。 容器(Container):镜像(Image)和容器(Container)的关系,就像是面向对象程序设计中的类和实例一样,镜像是静态的定义,容器是镜像运行时的
-
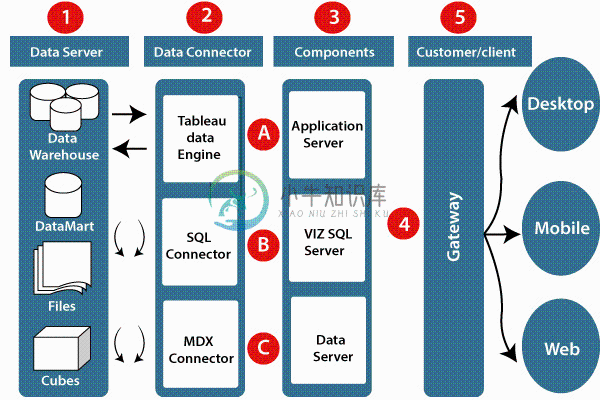 Tableau架构
Tableau架构Tableau Server旨在连接许多数据层。它可以连接来自Mobile,Web和Desktop的客户端。Tableau Desktop是一种功能强大的数据可视化工具。它非常安全且高度可用。 它可以在物理机和虚拟机上运行。它是一个多进程,多用户和多线程系统。 提供如此强大的功能需要独特的架构。 Tableau服务器中使用的不同层在以下体系结构图中给出: 下面我们来了解Tableau架构的不同组件
-
 JFreeChart 架构
JFreeChart 架构主要内容:JFreeChart 类关系结构,JFreeChart 应用架构JFreeChart 的库包含两个层次的体系结构来定义其各种类之间的交互。 JFreeChart 类关系结构 基本的类级别体系结构表示 JFreeChart 库中存在的各种类如何相互交互以生成各种类型的图表。 File:表示用于创建该文件中的数据集的用户输入。 Database:表示用于在数据库中创建的数据集的具有源的用户输入。 Create DataSet:表示正在创建并存储到该对象的数据集。
-
 Log4j 架构
Log4j 架构主要内容:Log4J核心对象,支持对象Log4j 遵循分层架构,其中每一层用于提供不同的对象来执行不同的任务。这种分层架构使设计在未来可以轻松灵活地扩展。 Log4j 框架中有两种类型的对象可用: 核心对象:核心对象是框架的强制性对象。所有对象都需要使用框架。 支持对象:支持对象是框架的可选对象。它们曾经支持核心对象执行额外但重要的任务。 Log4J核心对象 有以下类型的核心对象或以下是 Log4J 组件: Logger: Logge
-
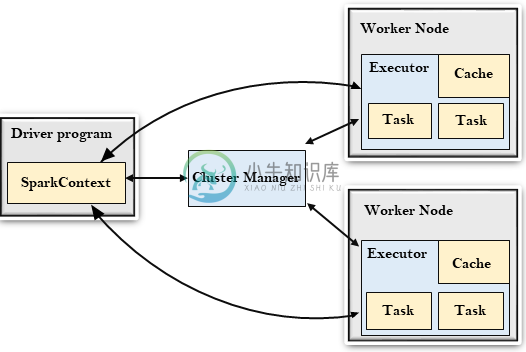 Spark架构
Spark架构主要内容:弹性分布式数据集(RDD),有向无环图(DAG)Spark遵循主从架构。它的集群由一个主服务器和多个从服务器组成。 Spark架构依赖于两个抽象: 弹性分布式数据集(RDD) 有向无环图(DAG) 弹性分布式数据集(RDD) 弹性分布式数据集是可以存储在工作节点上的内存中的数据项组。 弹性:失败时恢复数据。 分布式:数据分布在不同的节点之间。 数据集:数据组。 稍后将详细了解RDD。 有向无环图(DAG) 有向无环图是一种有限的直接图,它对数据
-
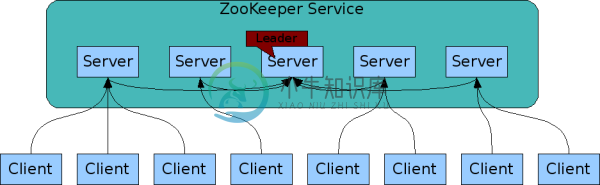 Zookeeper 架构?
Zookeeper 架构?本文向大家介绍Zookeeper 架构?相关面试题,主要包含被问及Zookeeper 架构?时的应答技巧和注意事项,需要的朋友参考一下 作为一个优秀高效且可靠的分布式协调框架, 在解决分布式数据一致性问题时并没有直接使用 ,而是专门定制了一致性协议叫做 原子广播协议,该协议能够很好地支持 崩溃恢复 。
-
DirectDraw架构
DirectDraw架构 返回上级 这一章介绍了DirectDraw与操作系统和系统硬件之间的关系。包含以下主题: DirectDraw结构概览 DirectDraw对象类型 硬件抽象层(HAL) 软件仿真层(HEL) DirectDraw架构概览 多媒体应用程序及游戏需要高表现力的图形引擎。Microsoft公司通过DirectDraw,为广大开发者提供了一个比GDI层次更高、功能更强、操作更有
-
5. 架构
英文原文 本章我们将从软件工程的角度,来简单介绍一下Kivy的设计。这对于理解各个部分如何配合工作会有帮助。如果你只关注代码,可能有时候会遇到这样一种情况,就是你已经有了一个初步的想法了,但具体怎么去实现可能还是一头雾水,所以本章就针对这种情况,来更深入地讲解一下Kivy的一些基本思想。你也可以先跳过这一章,等以后再翻回来看,不过我们建议开发者还是先看一下这些内容比较好,起码可以快速略读一下有个印
-
1.6.3 架构
Contiki的文件组织架构: 文件夹 描述 相关文件 examples 1:2 examples/zolertia, examples/cc2538-common app 1:3 - cpu 1:4 msp430,cc2538 dev 1:5 cc2420,cc2538 platform 1:6 z1,zoul core 1:7 - tools 1:8 zolertia,sky doc 1:9
-
9.4 架构
Kafka Streams 建立在 Kafka 的 producer 和 consumer 两个库之上以简化应用开发,并利用 Kafka 的原生功能来提供数据的并行处理能力、分布式协调、容错和操作的简化。在这一节中,我们将阐述 Kafka Streams 是如何运作的。 下图展示了使用Kafka Streams库的应用程序的解剖结构。让我们来看看一些细节。 Stream Partitions an
-
1.2.3 架构
节点角色说明 节点 角色说明 Provider 暴露服务的服务提供方 Consumer 调用远程服务的服务消费方 Registry 服务注册与发现的注册中心 Monitor 统计服务的调用次数和调用时间的监控中心 Container 服务运行容器 调用关系说明 服务容器负责启动,加载,运行服务提供者。 服务提供者在启动时,向注册中心注册自己提供的服务。 服务消费者在启动时,向注册中心订阅自己所需的
-
Profile架构
这篇文章描述了一个进行中的设计重构,始于2012年1月。 注意:2013年六月之后,这篇文章需要更新。相关的类被重命名(s/ProfileKeyed/BrowserContextKeyed/)以及移动到components/browser_context_keyed_service中。 Chromium有许多与Profile挂钩的特性,所谓Profile,即一些与当前用户以及跨越多个浏览器wind
-
架构(Architecture)
JSF技术是用于开发,构建服务器端用户界面组件并在Web应用程序中使用它们的框架。 JSF技术基于模型视图控制器(MVC)架构,用于将逻辑与表示分离。 什么是MVC设计模式? MVC设计模式使用三个独立模块设计应用程序 - S.No 模块和描述 1 Model 携带数据并登录 2 View 显示用户界面 3 Controller 处理应用程序的处理。 MVC设计模式的目的是将模型和表示分开,使开发
-
Serverless架构
就像无线互联网实际有的地方也需要用到有线连接一样,无服务器架构仍然在某处有服务器。Serverless(无服务器架构)指的是由开发者实现的服务端逻辑运行在无状态的计算容器中,它由事件触发, 完全被第三方管理,其业务层面的状态则被开发者使用的数据库和存储资源所记录。 CNCF 的云原生 landscape 中就包括 Serverless 附图,这也是云原生发展到更高阶段的面向特定应用场景的简易抽象。