《并发编程》专题
-
Gradle lint现在lints发布版本并需要密钥库密码?
我正在做一个项目,最近更新到android Gradle build tools 3.0.0()。通过Android Studio运行或gradle lint任务时,我现在看到以下错误: 任务“:app:PackageDevRelease”执行失败。无法从存储区“(密钥存储区名称)”读取密钥别名:密钥存储区被篡改或密码不正确。 看起来lint现在需要一个完整的版本构建来签名和构建,这需要密钥库密码
-
需要处理未捕获的异常并发送日志文件
更新:请参阅下面的“已接受”解决方案 当我的应用程序创建一个未处理的异常时,我希望首先给用户一个发送日志文件的机会,而不是简单地终止。我意识到在得到一个随机异常后做更多的工作是有风险的,但是,嘿,最糟糕的是应用程序崩溃,日志文件不会被发送。事实证明,这比我想象的要棘手:) 工作原理:(1)捕获未捕获的异常,(2)提取日志信息并写入文件。 对如何做到这一点有什么建议吗? 下面是一些作为入门指南的代码
-
并发填充列表中的经典for loop vs Arraylist forEach-Java 8
我正在对数组列表使用Java8迭代器。假设我有一个futures的ArrayList,在使用经典的for循环和使用ArrayList foreach之间有什么问题/建议吗?(除了不能从lambda表达式中抛出异常之外) 假设未来主义者同时被填补,最好的方法是什么?最后一个foreach示例是否容易出现问题?
-
为什么SafePoint类从实践书中的并发标记为@ThreadSafe?
在Java并发实践书中,您可以找到以下代码: 我很确定这个类不是线程安全的(如果我正确理解这个术语的话)。 示例: 我认为有几种可能的结果: null 如果为真,为什么作者将类标记为线程安全?我认为线程安全类-类可以在并发应用程序中使用,而不需要复杂的分析。 作者想说什么? 我已经阅读了私有构造函数以避免竞争条件 ...我的题目不重复。
-
发送响应并停止在nodejs中进一步执行代码
我使用node创建restful api,在发送响应时感到困惑。 以下是示例代码: 当我在失败的移动验证响应期间未指定return时,它会继续执行代码并在控制台中打印“数据未定义”,但Invalid mobile message json会正确发送到客户端,而不会进行错误跟踪。 我不知道在nodejs中创建api时应该遵循什么样的正确方法。我担心的是,一旦发送了响应,就不应该进一步处理请求。此外,
-
discord.py向成员发送加入信息并赋予他们角色
我想让我的机器人直接向加入我的服务器的人发送消息,并在30秒后给他们角色。我没有收到任何错误,我的机器人没有崩溃,但它什么也不做。 我的代码: 我已经导入了,,我的机器人有权限,成员没有阻止DMs。
-
发送0xFF并使用签名字节计算CRC-WriteSingleCoil&ModBUS&Java&Android-
编辑和SOVLED(下图) 我正在使用Java for Android试图将字节255(在WriteSingleCoil函数中为0xff)发送到ModBUS服务器设备。 设备没有运行,我不知道是因为不能解释签名字节-1还是因为我计算CRC错误。我不知道如何计算负字节的CRC。 这个答案帮助了我。非常感谢秃鹰的一天 但我最大的问题是Java中带符号字节的常见问题。我的CRC计算函数对无符号字节做得很
-
云功能算到Firebase实时数据库的并发连接吗?
在我的项目中,我使用实时数据库以及Firestore数据库。当一个文档被添加到Firestore数据库中的特定集合时,我的云函数会触发。然后该函数写入我的实时数据库以更新一些统计信息。我注意到,即使没有用户连接到我的实时数据库,当云函数写入实时数据库时,并发连接的数量也会增加。这是否意味着我的云功能被视为并发连接,并将减少可以同时连接到我的实时数据库的用户数,因为有100k并发连接的限制?
-
如何在Spark Streaming DirectAPI中从每个Kafka分区并发读取
如果我是正确的,默认情况下,spark streaming 1.6.1使用单线程从每个Kafka分区读取数据,假设我的Kafka主题分区是50,这意味着每50个分区中的消息将按顺序读取,或者可能以循环方式读取。 案例1: -如果是,那么我如何在分区级别并行化读取操作?创建多个< code > kafkautils . createdirectstream 是唯一的解决方案吗? 案例2: -如果我的
-
Drools规则插入新事实并动态激发其他规则
我对drools和KIE服务器是新手。我遇到了一个问题,即如何通过触发规则RHS(then action)在工作记忆中插入新的事实,然后通过这些动态插入的事实激活其他规则。 我所期望的是,当BaseFeature从外部插入工作内存并激活RuleOne时,在RuleOne内部“然后”它将插入新的事实RuleResult,并希望激活RuleTwo,但它没有激活RuleTwo,只是RuleOne被激活了
-
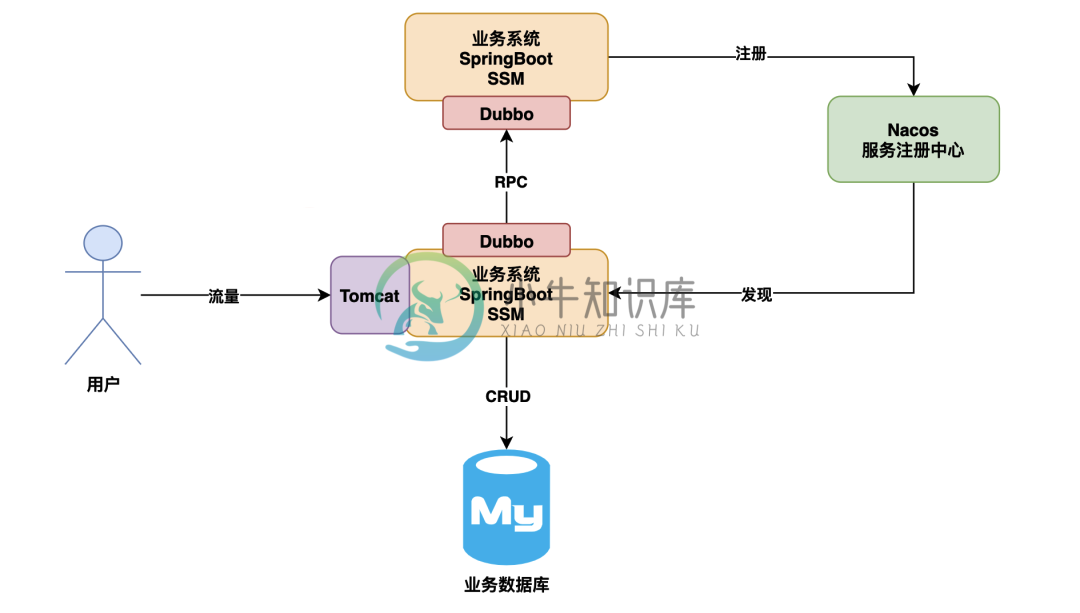 多级缓存架构如何支撑并发上10w的场景
多级缓存架构如何支撑并发上10w的场景主要内容:回头看看:原始系统技术架构,基于 CDN 的活动静态页面缓存方案,基于 Nginx+Tomcat+Redis 的多级缓存方案,超高并发写请求 RocketMQ 削峰填谷方案,系统限流防雪崩体系架构方案今天给大家分享一个话题,就是如果要是你老板突然要求你把你负责的系统,要接入到双十一中去抗下双十一带来的超大流量,你会感到心里特别慌,然后特别没底吗? 我估计大部分兄弟应该都会感到很慌很没底,不过没事,今天我们就来给大家讲讲,如果咱们系统要接入双十一活动抗下超大并发流量,应该怎么来优化设计。
-
 HDFS是如何抗住每秒上千次高并发访问的?
HDFS是如何抗住每秒上千次高并发访问的?主要内容:目录,一、写在前面,二、问题源起,三、HDFS优雅的解决方案,(1)分段加锁机制 + 内存双缓冲机制,(2)多线程并发吞吐量的百倍优化,(3)缓冲数据批量刷磁盘 + 网络的优化,四、总结一、写在前面 上篇文章我们已经初步给大家解释了Hadoop HDFS的整体架构原理,相信大家都有了一定的认识和了解。 本文我们来看看,如果大量客户端对NameNode发起高并发(比如每秒上千次)访问来修改元数据,此时NameNode该如何抗住? 二、问题源起 我们先来分析一下,高并发请求NameNode
-
第5章 OpenCL运行时和并发模型 - 5.6 本章总结
本章中我们讨论了很多有关运行时和执行模型的话题。运行时提供基于任务的执行模式,其底层是基于OpenCL的入队模型和时间对象提供的依赖机制。事件对象能用来分析OpenCL的命令,以及“用户定义的相关回调命令”的性能。内核的执行域是一组层级结构,其包含工作项,工作组,以及NDRange。OpenCL 2.0中加入的一些新功能,能让内核在设备端入队。我们也了解了如何在内核中使用块语法。同样,执行顺序和基
-
EOS 安装本地环境 并实现发币转账等功能
第一步:很重要:买个服务器或者装个虚拟机,推荐用linux服务器,注意:由于国内网络环境原因,建议使用国外服务器搭建。 下面为环境搭建过程 首先保证你服务器安装有git,没有自行百度安装 001 获取代码 克隆EOS存储库及子模块 git clone https://github.com/EOSIO/eos --recursive 002 安装EOSIO 这里我们使用自动构建脚本安装: cd eo
-
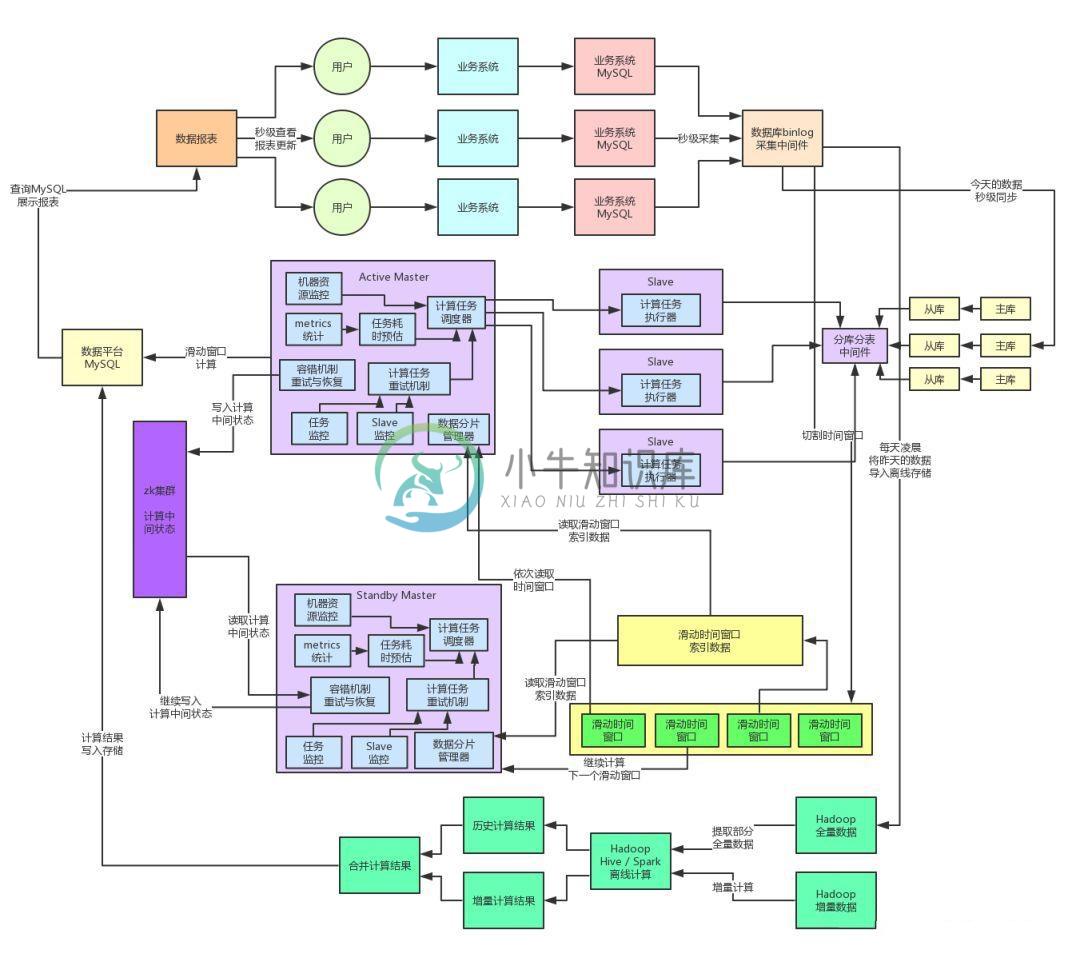 如何解决高并发和存算分离的技术架构
如何解决高并发和存算分离的技术架构主要内容:一、往期回顾,二、百亿流量的高并发技术挑战,三、计算与存储分离的架构,四、自研纯内存SQL计算引擎,五、MQ削峰以及流量控制,六、数据的动静分离架构,七、阶段性总结,八、下一步展望一、往期回顾 上篇文章《为什么有些看起来很厉害的技术高手,设计的架构都很垃圾?》,主要聊了一下将单块系统重构为分布式系统,以此来避免单台机器的负载过高。同时引申出来了弹性资源调度、分布式容错机制等相关的东西。 这篇文章我们继续来聊聊这个系统后续的重构演进过程,先来看下目前的系统架构图,一起来回顾一下。 二、百