《高并发》专题
-
Hadoop高并发?
本文向大家介绍Hadoop高并发?相关面试题,主要包含被问及Hadoop高并发?时的应答技巧和注意事项,需要的朋友参考一下 首先肯定要保证集群的高可靠性,在高并发的情况下不会挂掉,支撑不住可以通过横向扩展。 datanode挂掉了使用hadoop脚本重新启动。
-
并发 - 高级并发对象
高级并发对象 目前为止,之前的教程都是重点讲述了最初作为 Java 平台一部分的低级别 API。这些API 对于非常基本的任务来说已经足够,但是对于更高级的任务就需要更高级的 API。特别是针对充分利用了当今多处理器和多核系统的大规模并发应用程序。 本章,我们将着眼于 Java 5.0 新增的一些高级并发特征。大多数功能已经在新的java.util.concurrent 包中实现。Java 集合框
-
高级合并
在 Git 中合并是相当容易的。 因为 Git 使多次合并另一个分支变得很容易,这意味着你可以有一个始终保持最新的长期分支,经常解决小的冲突,比在一系列提交后解决一个巨大的冲突要好。 然而,有时也会有棘手的冲突。 不像其他的版本控制系统,Git 并不会尝试过于聪明的合并冲突解决方案。 Git 的哲学是聪明地决定无歧义的合并方案,但是如果有冲突,它不会尝试智能地自动解决它。 因此,如果很久之后才合并
-
高并发测试-ConcurrencyTester
由来 很多时候,我们需要简单模拟N个线程调用某个业务测试其并发状况,于是Hutool提供了一个简单的并发测试类——ConcurrencyTester。 使用 ConcurrencyTester tester = ThreadUtil.concurrencyTest(100, () -> { // 测试的逻辑内容 long delay = RandomUtil.randomLong(
-
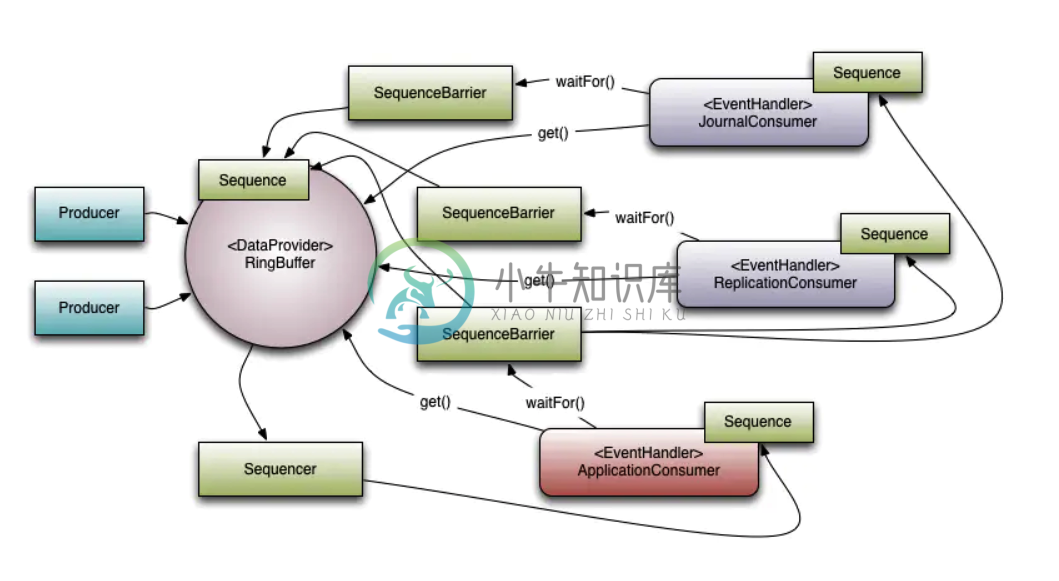 高并发框架 Disruptor
高并发框架 Disruptor主要内容:1.Disruptor介绍,2.Disruptor 的核心概念,3.demo1.Disruptor介绍 Disruptor是一个开源的Java框架,它被设计用于在生产者—消费者(producer-consumer problem,简称PCP)问题上获得尽量高的吞吐量(TPS)和尽量低的延迟。 从功能上来看,Disruptor 是实现了“队列”的功能,而且是一个有界队列。那么它的应用场景自然就是“生产者-消费者”模型的应用场合了。 其实Disruptor与其说是一个框架,不
-
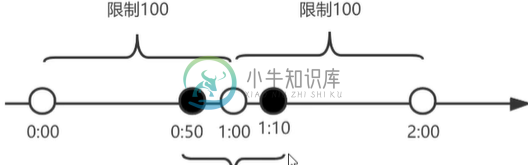 高并发之限流
高并发之限流主要内容:1.算法,2.单机限流器,3.分布式限流器,4.接入层限流器1.算法 计数器 漏桶算法 令牌桶算法 滑动窗口算法 1.1 计数器法 实现简单, 就是临界值问题 指在指定的时间里累加访问量,达到阈值后,触发限流策略,在下一周期访问数量清除 使用redis的incr和key过期 问题:在相邻的一个时间段20s内,请求超过100。 这个算法通常用于QPS限流和统计总访问量,对于秒级以上的时间周期来说,会存在一个非常严重的问题,那就是临界问题。 假设1min内服务
-
 高并发高可用高性能的解决方案
高并发高可用高性能的解决方案主要内容:1.难题与方案,2.具体措施,3.九种技术架构1.难题与方案 1、亿级流量电商网站的商品详情页系统架构 面临难题:对于每天上亿流量,拥有上亿页面的大型电商网站来说,能够支撑高并发访问,同时能够秒级让最新模板生效的商品详情页系统的架构是如何设计的? 解决方案:异步多级缓存架构+nginx本地化缓存+动态模板渲染的架构 2、redis企业级集群架构 面临难题:如何让redis集群支撑几十万QPS高并发+99.99%高可用+TB级海量数据+企业级数
-
springboot高并发下提高吞吐量的实现
本文向大家介绍springboot高并发下提高吞吐量的实现,包括了springboot高并发下提高吞吐量的实现的使用技巧和注意事项,需要的朋友参考一下 公司让做一个全文检索的项目,我使用的是elasticsearch。但是对性能有很高的要求,为了解决性能问题,我简直是寝食难安。 es(elasticsearch)没有使用分布式,单台的。 开发完测试的时候,查询慢,吞吐量低。 网友们建议用异步--使
-
高级 - 常见的并发模式
常见的并发模式 在基础知识部分,我们看到了如何使用辅助函数 takeEvery 和 takeLatest 来管理 Effects 之间的并发。 在本节中,我们将看到如何使用低阶 Effects 来实现那些辅助函数。 takeEvery function* takeEvery(pattern, saga, ...args) { while(true) { const action = y
-
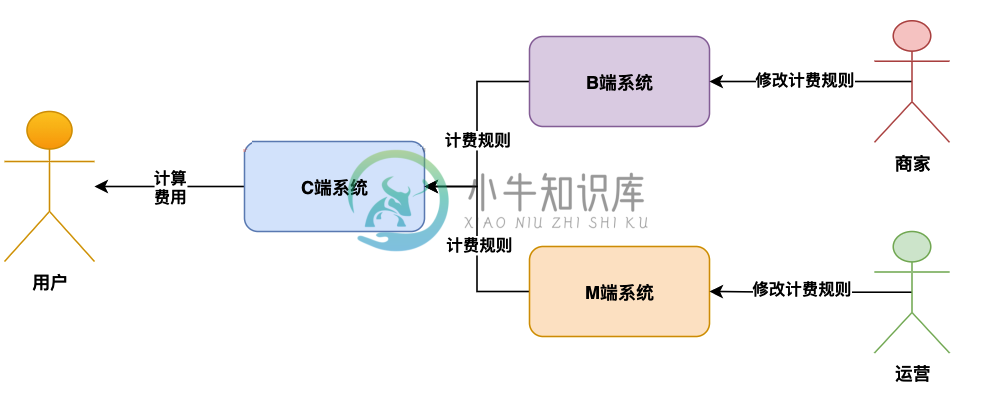 高可用高并发架构系统该如何设计?
高可用高并发架构系统该如何设计?主要内容:背景,计费业务系统架构设计,计费业务数据补偿系统设计,总结背景 今天给大家分享一个话题,就是对于线上跟钱有关的计费类的系统,在线上可能出现的一些把钱算错的问题,以及我们如何来设计架构解决这些问题。 但凡是跟算钱相关的系统,都是每个公司的重中之重,比如说价格系统、运费系统、计费系统、支付系统、基金系统、财务系统、结算系统等等,因为这些系统运行过程中,随时可能因为技术问题或者运营的人为误操作问题,把钱给算错了。 所以今天来给大家讲讲这一类跟算钱有关的系统,我
-
高级分支与合并
在合并过程中得到解决冲突的协助 git会把所有可以自动合并的修改加入到索引中去, 所以git diff只会显示有冲突的部分. 它使用了一种不常见的语法: $ git diff diff --cc file.txt index 802992c,2b60207..0000000 --- a/file.txt +++ b/file.txt @@@ -1,1 -1,1 +1,5 @@@ ++<<<<<<<
-
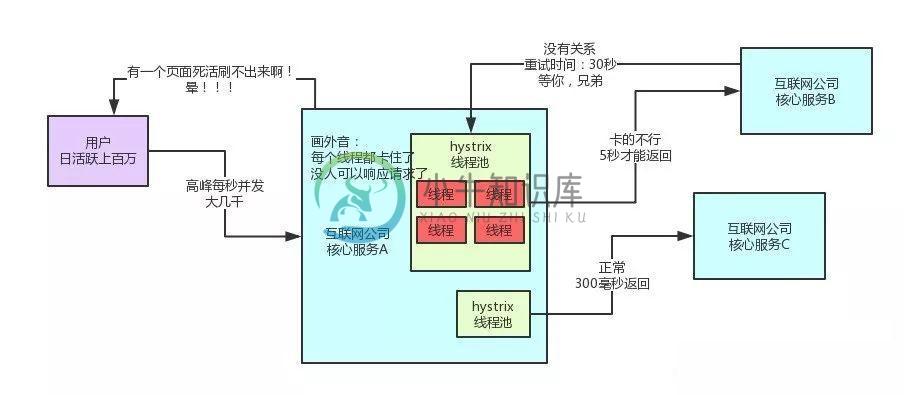 你的系统该怎么抗高并发还能高可用?
你的系统该怎么抗高并发还能高可用?主要内容:一、概述,二、业务场景介绍,三、线上经验—如何设置Hystrix线程池大小,四、线上经验—如何设置请求超时时间,五、服务降级,六、总结一、概述 上一篇文章讲了一个朋友公司使用Spring Cloud架构遇到问题的一个真实案例,虽然不是什么大的技术问题,但如果对一些东西理解的不深刻,还真会犯一些错误。 如果没看过上一篇文章的朋友,建议先看看:《我进了新公司结果不会用SpringCloud,人生第一次被辞退了!》因为本文的案例背景会基于上一篇文章。 这篇文章我们来聊聊在微服务架构中,到底如
-
与Netty和NIO高度并发的HTTP
问题内容: 我正在研究示例Netty HTTP客户端代码 ,以便在并发线程环境中发出http请求。 但是,我的系统以相当低的吞吐量完全崩溃(有很多异常)。 用几乎伪代码: 在示例中,为了发出请求,我创建了一个ClientBootstrap,然后从那里(通过几个箍)创建一个Channel以编写HTTPRequest。 这一切都很好,而且很好。 但是,在同时发生的情况下,是否每个请求都要经过相同的循环
-
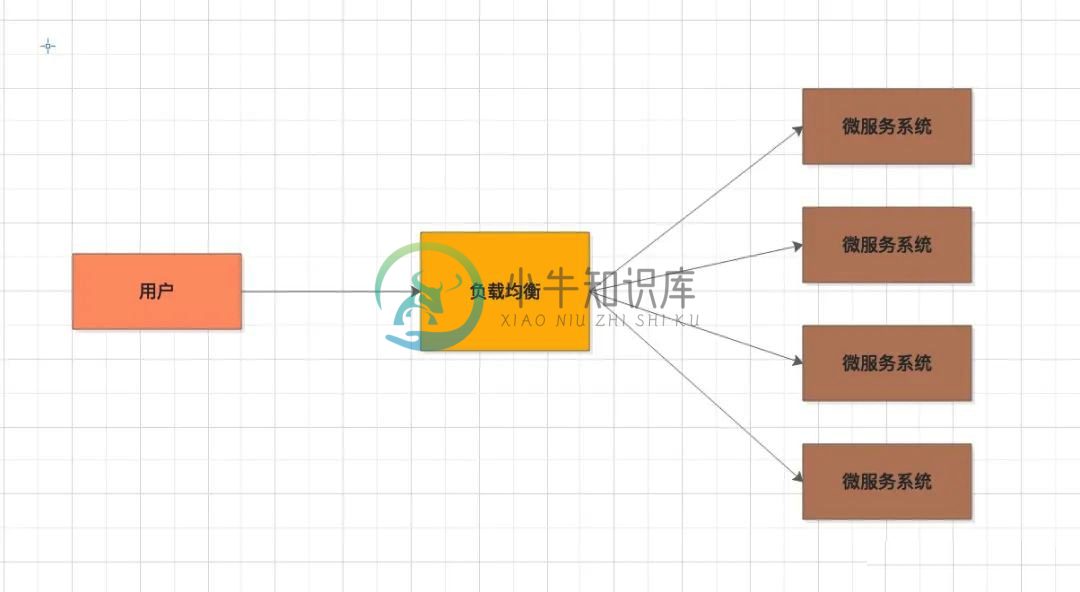 高并发设计的技术方案
高并发设计的技术方案主要内容:1.负载均衡,2.分布式微服务,3.缓存机制,4.分布式关系型数据库,5.分布式消息队列,6.CDN 内容分发网络,7.其他,8.总结1.负载均衡 靠优化单台机器的内存、CPU、磁盘、网络带宽,使其发挥极致性能,已经不太现实。 负载均衡,它的职责是将网络请求 “均摊”到不同的机器上。避免集群中部分服务器压力过大,而另一些服务器比较空闲的情况 通过负载均衡,可以让每台服务器获取到适合自己处理能力的负载。在为高负载服务器分流的同时,还可以避免资源浪费,一举两得。 常见的负载算法: 随机算法
-
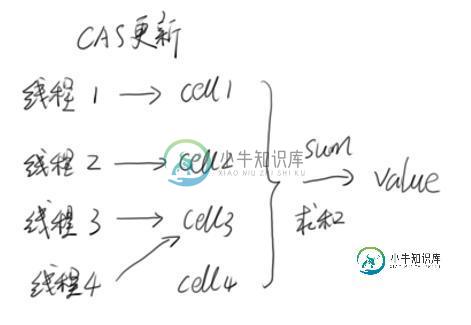 Java 高并发十: JDK8对并发的新支持详解
Java 高并发十: JDK8对并发的新支持详解本文向大家介绍Java 高并发十: JDK8对并发的新支持详解,包括了Java 高并发十: JDK8对并发的新支持详解的使用技巧和注意事项,需要的朋友参考一下 1. LongAdder 和AtomicLong类似的使用方式,但是性能比AtomicLong更好。 LongAdder与AtomicLong都是使用了原子操作来提高性能。但是LongAdder在AtomicLong的基础上进行了热点分离,