《顺丰2024春招》专题
-
查找顺序值的有效方法
问题内容: 每个“产品”最多可以有10000个“细分”行。这些细分受众群具有一个针对每种产品(1、2、3、4、5,…)从1开始的排序列,以及一个值列,该列可以包含诸如(323.113、5423.231、873.42、422.64、763.1,…)。 我想确定给定细分子集的产品的潜在匹配。例如,如果我按正确的顺序有5个细分值,那么如何在细分表中某处有效地找到所有具有相同顺序的5个细分的所有产品? 问
-
从起始值开始的MySQL顺序
问题内容: 在产品页面上,我有一个下拉列表,列出了与产品页面关联的当前颜色选项。 在此示例中,产品页面SKU为250E,可在以下位置使用: 如果客户选择GREEN,则我想运行一个MySQL命令,该命令将根据下面显示的custom_order值将数据更改为首先显示GREEN值。 起始值应覆盖其他数据项,然后应保留custom_order值。custom_order字段的字母类似c1,c2(它们将始终
-
联接顺序在SQL中重要吗?
问题内容: 无论性能如何,我从下面的查询A和B中都能得到相同的结果吗?C和D呢? 问题答案: 对于联接,不,顺序无关紧要。该查询将返回相同的结果,只要你改变你的选择来。 对于(,或)连接,是的,顺序是有意义的-和( 更新 )事情要复杂得多。 首先,外部联接不是可交换的,因此与 外部联接也不是关联的,因此在您的示例中同时涉及(可交换性和关联性)两个属性: 等效于 : 但: 不等同于 : 另一个(希望
-
强制SymPy保持条款的顺序
问题内容: 我有以下代码: 而当的输出是 问题是:我想要变量的原始顺序。 所有这些都是在IPython Notebook中完成的。有什么方法可以保持秩序? 问题答案: 可悲的是,SymPy无法跟踪输入顺序(请参阅我在对该问题的评论中链接的另一个问题)。您可以定义自己的排序函数,以便根据需要对表达式进行排序,但是由于无法保存信息,因此无法完全按照输入的顺序对它们进行排序。
-
Python:如何创建顺序文件名?
问题内容: 我希望我的程序能够以顺序格式写入文件,即:file1.txt,file2.txt,file3.txt。它仅意味着在执行代码时写入单个文件。它不能覆盖任何现有文件,并且必须创建。我很沮丧 问题答案: 两种选择: 反文件。 检查目录。 反文件 。 每次创建一个新文件时,您还将用适当的编号重写计数器文件。非常非常快 但是,从理论上讲,可以使两者不同步。发生事故时。 您还可以通过将其制成一小段
-
os.walk以什么顺序进行迭代?
问题内容: 我担心给出的文件和目录的顺序。如果我有这些目录,,,,,,,,,,,,,什么是输出列表的顺序? 它是按数值排序的吗? 或按ASCII值排序,如? 此外,如何获得特定的排序? 问题答案: 用途。这是的文档字符串: listdir(路径)-> list_of_strings 返回一个列表,其中包含目录中条目的名称。 该列表按任意顺序排列 。它不包括特殊条目“。” 和“ ..”,即使它们存在
-
基于列顺序的查询速度
问题内容: 数据库中列类型的顺序是否对查询时间有影响? 例如,具有混合顺序(INT,TEXT,VARCHAR,INT,TEXT)的表的查询是否比具有连续类型(INT,INT,VARCHAR,TEXT,TEXT)的表的查询慢? 问题答案: 答案是肯定的,这确实很重要,并且可能很重要,但 通常 并不重要。 所有I / O都在页面级别完成(根据您的操作系统,通常为2K或4K)。行的列数据彼此相邻存储,除
-
在nodejs中排序findAll排序顺序
问题内容: 我正在尝试通过sequelize从数据库中输出所有对象列表,如下所示,并希望在我在where子句中添加id时对数据进行整理。 但是问题是渲染后,所有数据按如下进行整理。 正如我发现的那样,它既没有按ID也没有按名称排序。请帮我解决。 问题答案: 在序列化中,您可以轻松添加order by子句。 看看我如何添加对象数组? 编辑: 一旦在诺言中收到对象,您可能必须订购这些对象。查看有关根据
-
查询与过滤器-执行顺序
问题内容: 我已经读过这个问题,我的一个同事让我感到怀疑: 在过滤查询中,何时应用过滤器?在执行查询之前还是之后?什么时候缓存结果? 如果事先应用了过滤器,那么在过滤器中复制查询部分不是一件好事吗?如果之后应用了筛选器,那么我将无法理解缓存的内容。 问题答案: 幸运的是,ES为您提供了两种类型的过滤器供您使用: 在第一种情况下,过滤器将应用于查询找到的所有文档。在第二种情况下,将在查询运行之前过滤
-
javascript顺序加载图片的方法
本文向大家介绍javascript顺序加载图片的方法,包括了javascript顺序加载图片的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了javascript顺序加载图片的方法。分享给大家供大家参考。具体如下: javascript监听一个图片是否加载完毕 如果加载完成再加载下一张,不是一次性从服务器加载 减少服务器压力, 可用到的地方:比如制作类似google地图的应用,可以使小
-
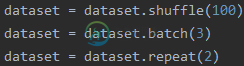 tensorflow dataset.shuffle、dataset.batch、dataset.repeat顺序区别详解
tensorflow dataset.shuffle、dataset.batch、dataset.repeat顺序区别详解本文向大家介绍tensorflow dataset.shuffle、dataset.batch、dataset.repeat顺序区别详解,包括了tensorflow dataset.shuffle、dataset.batch、dataset.repeat顺序区别详解的使用技巧和注意事项,需要的朋友参考一下 1.作用 dataset.shuffle作用是将数据进行打乱操作,传入参数为buffer_s
-
 Drools决策表动作执行顺序
Drools决策表动作执行顺序我有一个Drools决策表(见下文),其中规则2有一个条件,检查营养分数是否在某个阈值之间,并根据该条件执行操作。有一个初始规则(规则1)执行检查并执行其操作,它更新了我希望规则2在执行其条件时使用的总分。 我的期望/需要: 规则1运行,如果条件满足,则更新$model上的总体分数(通过执行其操作),然后规则2运行,并且对于它的条件,使用由规则1的操作运行更新的更新分数值。 实际发生了什么 规则1
-
顺序无关加权随机选择
假设我有一个随机选择的项目池。 我使用一个简单的加权选择算法来做到这一点: 计算项目权重总和 在0和权重和之间选择一个随机数 迭代项目,并按项目权重减少,选择项目时 同时,约束传播算法更新可用项目池。 例如,假设我们有一个N乘N的网格,每个单元格可以选择一个数字 使用上述算法,通过加权选择完成选择 一旦一个单元选择了它的编号,它还会使用一些规则限制相邻单元的可用编号 我的问题是: 假设牢房A和B是
-
Javascript增量运算顺序的计算
我知道后缀/前缀递增/递减运算符是做什么的。在javascript中,这似乎没有什么不同。 虽然我可以很容易地猜出这一行的结果: 当运算符出现在单独的表达式中时。 由于这些运算符出现在同一个表达式中,因此变得有点复杂: 我的问题是,Javascript(在本例中为V8,我在Chrome中测试了它们)如何以不同的方式计算第二个和第三个示例中的加法表达式? 为什么的评估结果与不同。后缀不是应该在表达式
-
比较两个Python列表的顺序
null 但是,如果清单2为应该返回false(因为字符串d出现的顺序混乱)