《拼多多2024春招》专题
-
ES6类多重继承
我已经在BabelJS和MDN上完成了大部分研究(根本没有信息),但如果我在寻找有关ES6 Spec的更多信息时不够小心,请随时告诉我。 我想知道ES6是否以与其他鸭子类型语言相同的方式支持多重继承。例如,我可以做这样的事情吗: 要将多个类扩展到新类?如果是这样,解释器会更喜欢类二的方法/属性而不是类一吗?
-
向TableLayout添加多行
-
Birt报告多参数
目前,我正在使用Birt Report从我的系统生成报告。我正在使用输入参数将参数从系统发送到Birt Report。问题是当我试图从系统发送多个参数时。 示例:Birt报表中一个参数的SQL语句 当我将此查询用于一个参数时,它起作用了。 我现在努力实现的是, 我试过这样SQL 我已经在数据集和报表参数上创建了参数,但它仍然无法工作
-
多次压缩位图
Android API提供了保存位图对象的方法。我创建了一个示例应用程序,它将jpeg图像(一些嘈杂的相机照片)加载到位图中,然后将其压缩回同一个文件。然后,再做5次。 显然,我的位图积累了压缩伪影。让我惊讶的是,这些伪影的数量以一种奇怪的方式取决于压缩的质量。当我将质量设置为100(我认为这是最好的质量)时,工件清晰可见。当我将质量降低到90时,工件的可视性明显降低。质量设置为80会给我最好的效
-
重命名多个表
在SQL Server中,我有一个数据库< code>abc。在这个数据库中,我有数百个表。这些表格中的每一个都被称为< code>xyz.table 我想把所有的表格都改成< code>abc.table。 我们有办法将数据库< code>abc中的所有名称从< code>xyz.table更改为< code>abc.table吗? 我可以通过将每个表的模式更改为abc来手动更改名称
-
WSO2多租户和域
全新的,查看wso2 API管理器1.8.0。我为一家拥有多个组织/团队的公司工作,所以建立多租户似乎是合乎逻辑的选择。 按照《快速入门指南》,我首先创建了一个新租户,给它一个“dev.api.myorg.company.net”域,添加了一些用户,我可以登录。我添加了一个API。 我能够使用商店中列出的URL命中endpoint: http://wso2server。公司net:8280/t/d
-
Kafka:1对多加入
基本上,我想知道如果我有topic1和topic2会发生什么,因为topic1可以有N个topic2元素。 Topic1是用户的事件,topic2是该用户的配置。作为第一步,我将通过key匹配它们,从topic2中过滤掉不属于该用户的配置,但我仍然有多个匹配项。我需要向topic2添加更多过滤器来找到精确的匹配项,但我不知道在按key连接之后是否可以这样做。 我读到这个:Kafka Stream和
-
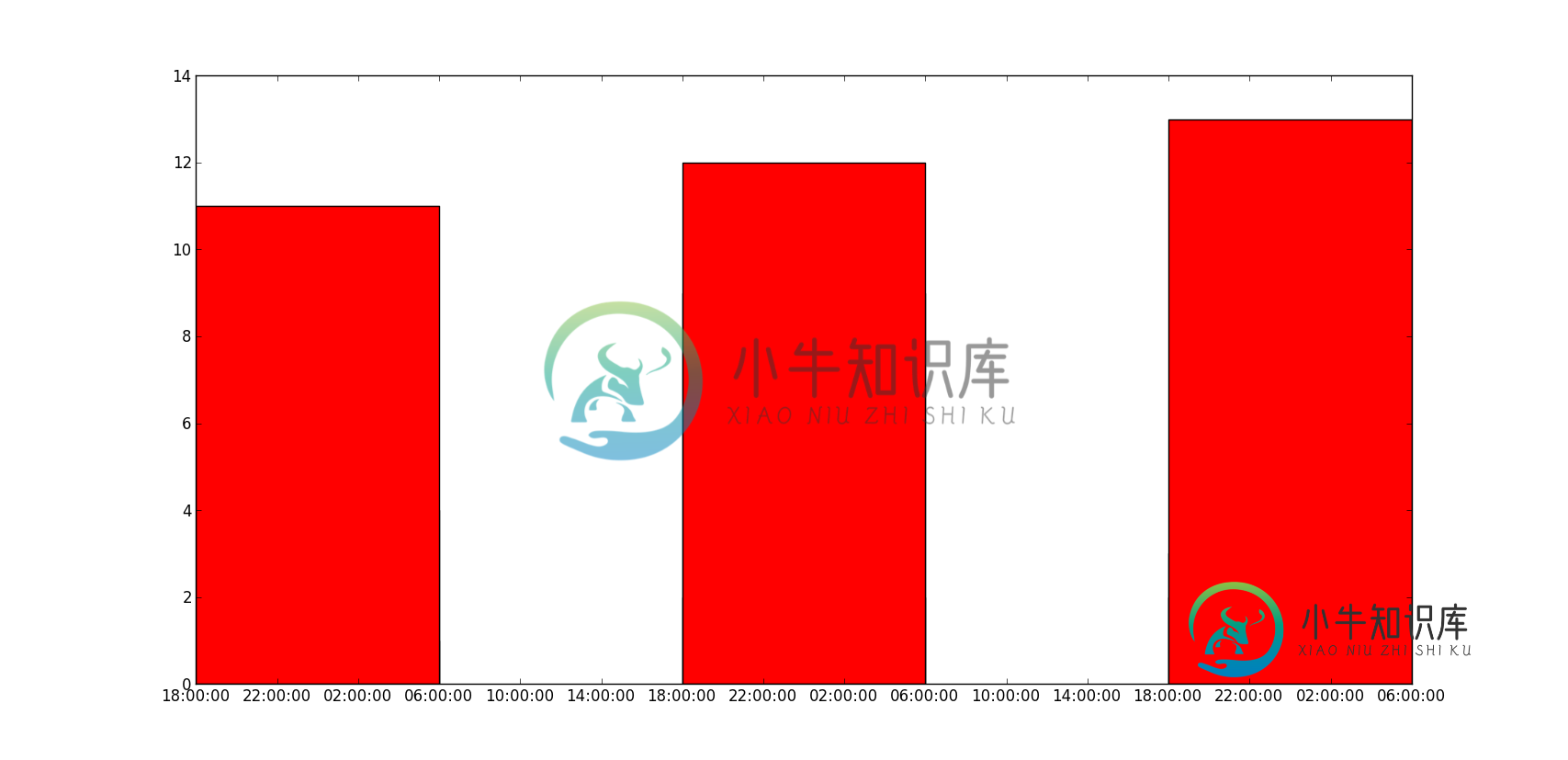 蟒蛇垫线多条
蟒蛇垫线多条如何在matplotlib中绘制多个条形图,当我多次尝试调用bar函数时,它们重叠,如下图所示,最高值红色只能看到。如何在x轴上绘制带有日期的多个条形图? 到目前为止,我尝试了这个: 我得到了这个: 结果应该是这样的,但是日期在x轴上,横条彼此相邻:
-
匹配多个类名
是否可以让Selenium匹配多个类名? 例如: 谢谢
-
Firebase存储多规则
只是一个关于如何实现多个Firebase存储安全规则的简短问题。 事实上,我想限制可以上传的文件的大小,但保留我的认证规则。 我一直在阅读上一篇文章,它给了我一个关于如何限制每个文件的上传大小的提示,但我仍然在努力实现“匹配/files/{fileName}”与身份验证规则的某个地方。 经过多次尝试,这是我在写这篇文章之前的最后一次迭代: 当然,我确实阅读了官方文档,但似乎我仍然无法正确理解。
-
Jena多个RDF:标签
下面是java代码: 这有帮助吗?我真的不知道了...
-
多Docker容器性能
假设我有一堆不同的docker容器,它们都是基于Python3.5的。在Ubuntu系统上使用Python3.5将所有任务作为后台进程同时运行(假设是5、10或20个容器),这一任务是否会使用更多/更少的资源?
-
@KafkaListener并发多主题
我想创建一个并发的,它可以处理多个主题,每个主题都有不同数量的分区。 我注意到,对于大多数分区的主题,Spring Kafka每个分区只初始化一个使用者。 示例:我已经将并发设置为8。我得到了一个听以下主题的。主题A有最多的分区-5,所以Spring-Kafka初始化了5个消费者。我期望Spring-Kafka初始化8个消费者,这是根据我的并发属性允许的最大值。 主题A有5个分区 没有初始化更多消
-
多重@Qualifier EJB注入
我有两个EJB实现相同接口,我有一些限定符: 而且 和我的错误: 原因:org.jboss.weld.exceptions.deploymentexception:Weld-001408:类型IConnectorService的依赖关系不满足,其限定符为@MetrilioConnector在注入点[UnbackedAnnotatedField]@MetrilioConnector@Inject c
-
Hibernate OneTo多项映射
我使用的是spring boot starter数据jpa 1.5.1。内部使用hibernate core 5.0.11的版本。最终的 我的实体看起来像这样: 区域 节日的 行动 我试图理解以下观点: > 我的映射是准确的,还是应该使用多重映射来处理这种关系,因为一个区域可以有多个节日,每个节日可以有多个动作 背景:如果我将fetch类型从LAZY改为eanger,就会出现以下错误。希望能够理解