《2024届毕业生》专题
-
kubernetes中的Flink部署无法启动作业
我按照以下指南在kubernetes创建了一个flink集群:https://ci.apache.org/projects/flink/flink-docs-release-1.11/ops/deployment/native_kubernetes.html 作业管理器正在运行。当作业提交给作业管理器时,它生成了一个任务管理器pod,但任务管理器无法连接到作业管理器。
-
Flink作业群集Kubernetes从保存点恢复
我们目前正在kubernetes上运行flink,作为使用这个helm模板的作业集群:https://github.com/docker-flink/examples/tree/master/helm/flink(带有一些添加的配置)。 如果我想关闭集群,重新部署新映像(由于应用程序代码更新)并重新启动,我将如何从保存点进行恢复? jobManager命令严格设置在standalone-job.s
-
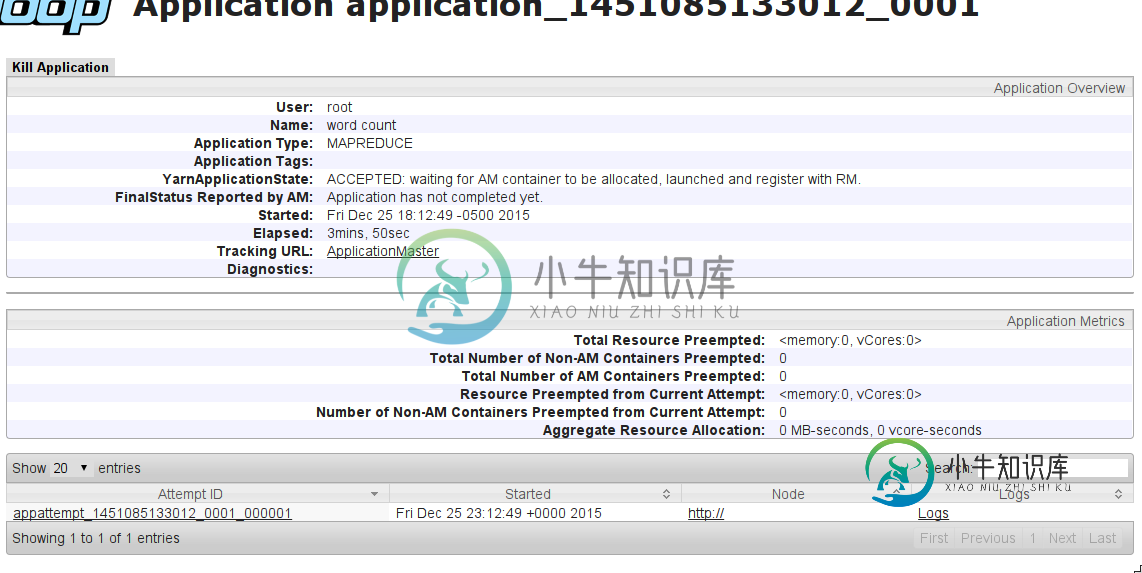 MapReduce作业挂起,等待分配AM容器
MapReduce作业挂起,等待分配AM容器我尝试将简单单词计数作为MapReduce作业运行。在本地运行时,一切工作都很好(所有工作都在Name节点上完成)。但是,当我尝试使用YARN在集群上运行它时(将=添加到mapred-site.conf),作业会挂起。 我在这里遇到了一个类似的问题:MapReduce作业陷入接受状态 作业输出: 会有什么问题? 编辑: 我在机器上尝试了这个配置(评论):NameNode(8GB RAM)+2x D
-
Spring Batch:作业存储库的水平扩展
我读了很多关于如何使用主/从范式实现单个作业的并行处理和分块的内容。考虑一个已经实现的Spring批处理解决方案,该解决方案打算在独立服务器上运行。通过最少的重构,我希望使其能够水平扩展,并在生产操作中更具弹性。速度和效率不是目标。 http://www.mkyong.com/spring-batch/spring-batch-hello-world-example/ 在以下示例中,使用连接到的作
-
杀死Tomcat时的Quartz当前执行作业
有些事我不清楚。假设我每天都有随机安排的作业,每个作业需要30分钟才能运行。假设我有五个这样的工作在运行,而Tomcat被杀了。当我用我的应用程序启动Tomcat时,作业是否会重新启动,或者当前正在运行的作业是否会因为已经启动而丢失?
-
从Cloud Composer运行java Google数据流作业
目前,我们正在库伯内特斯上使用自己安装的气流版本,但想法是在云作曲家上迁移。我们使用Airflow运行数据流作业,使用DataFlowJavaoperator的自定义版本(使用插件),因为我们需要执行java应用程序,而java应用程序不是在jar中自包含的。因此,我们基本上运行一个bash脚本,该脚本使用以下命令: 所有jar依赖项都存储在所有辅助角色之间的共享磁盘中,但是在Composer中缺
-
启动时运行谷歌数据流作业
我们的Google Cloud数据流管道程序调用了一些动态链接到*的库。所以要运行它,我需要设置linux环境变量LD_LIBRARY_PATH。有一种方法可以做到这一点:https://groups.google.com/forum/#!主题/综合。java。程序员/LOu18 OWAVM,但我想知道是否有一种方法可以在执行管道之前使用一些运行shell脚本的作业来实现这一点?
-
Google课堂-以编程方式创建作业
执行失败:接收到无效的JSON负载。“Course_Work.Materials[0]”处得未知名称“Share_Mode”:找不到字段.接收到无效的JSON负载。“Course_Work.Materials[0].Drive_File”处的名称“ID”未知:找不到字段。接收到无效的JSON负载。“Course_Work.Materials[0].Drive_File”处的未知名称“Title”:
-
从Spring批次中的步骤启动作业
我试图从步骤(实现接口Tasklet的类的execute方法)内部启动作业。 显然我收到了例外 Java语言lang.IllegalStateException:在JobRepository中检测到现有事务 如何使Spring批处理步骤不是事务性的? 有人能解决我从一步内启动工作的主要需求吗? 提前感谢您的帮助!
-
如何在kubernetes作业中创建init容器?
在job.yaml下面用于创建作业。未创建初始化容器。 [root@app]#kubectl版本客户端版本:version.info{Major:“1”,Minor:“15”,GitVersion:“v1.15.5”,GitCommit:“”,GitTreeState:“Clean”,BuildDate:“2019-10-15T19:16:51Z”,GoVersion:“Go1.12.10”,编译
-
事务管理器不回滚Spring Batch作业
我面临一个挑战,需要从SQL Server数据库中读取“未处理”的数据,处理数据,然后有选择地更新DB2数据库中的两到六个表,然后将该数据标记为在SQL Server上的原始数据库中已处理。在任何时候,如果出现任何故障,我希望所有更新都回滚。如果我有10个未处理的项目,9个良好,但有一个失败,我仍然希望9个良好的项目完成,第10个恢复到原始状态,直到我们可以研究问题并进行更正。 总体架构是,一个输
-
使用Apache Beam 2.9.0 Java SDK的Google dataflow作业
我使用的是Beam Java SDK2.9.0,我的工作读自Kafka中的步骤。我的工作在直跑方面很好。当我在Dataflow上部署它时,工作被卡住了,我看不到任何进展。数据流监视UI显示
-
只执行一行中的第一个作业
-
Flink作业在第二次提交后崩溃
-
如何从代码重新启动Flink作业
有人能给这点启示吗?