《大数据》专题
-
Kotlin中可调整大小的二维数组
问题内容: 我想知道如何在Kotlin中制作可调整大小的二维数组。 C ++示例: 我试过的 但是使用seqList.add()时出现错误 错误:未解决的参考:添加 我在stackoverflow上阅读了有关Kotlin中2d数组的一些问题,但它们与不可调整大小的数组有关或已过时 问题答案: 科特林有独立和接口,解释在这里,例如。是一个,您只需将其另存为变量,即可访问对其进行变异的方法: 还要注意
-
Java:HashMap的大小是“素数”还是“ 2的幂”?
问题内容: 许多书籍和教程都说,哈希表的大小必须是素数,才能在所有存储桶中平均分配密钥。但是Java 总是使用大小为2的幂。它不应该使用素数吗?哈希表的大小最好是“素数”还是“ 2的幂”? 问题答案: 使用2的幂可以有效地屏蔽哈希码的最高位。因此,在这种情况下,劣质哈希函数的性能可能会特别差。 Java 通过不信任对象的实现并对结果进行第二级哈希处理来缓解这种情况: 将补充哈希函数应用于给定的ha
-
在go中动态初始化数组大小
问题内容: 我尝试用go编写一个小型应用程序,该应用程序从标准输入中获取“ x”个整数,然后计算平均值并将其返回。到目前为止,我还没有: 尝试编译此错误时,出现以下错误消息: 无效的数组绑定元素 怎么了 问题答案: 您应该使用切片而不是数组: 请参阅“ 深入了解用法和内部原理 ”。 另外,您可能要考虑为循环使用范围:
-
抑制大熊猫的科学计数法吗?
问题内容: 我在熊猫中有一个DataFrame,其中一些数字用科学计数法(或指数计数法)表示,如下所示: 科学的表示法使应该进行轻松的比较成为不必要的困难。我认为正是21900的价值将其推向了其他水平。我的意思是1.0被编码。一! 这不起作用: 而且也没有实现抑制,而且我已经绝望了,只能为所有其他float值打开它,而无法关闭它。 问题答案: 您的数据可能是dtype。这是数据的直接复制/粘贴。将
-
C ++中字母构成的最大分数词
本文向大家介绍C ++中字母构成的最大分数词,包括了C ++中字母构成的最大分数词的使用技巧和注意事项,需要的朋友参考一下 假设我们有一个单词列表,一个字母列表和每个字符的分数。我们必须找到使用给定字母组成的任何有效单词集的最大分数。 我们可能不会在字母中使用所有字符,并且每个字母只能使用一次。字母“ a”,“ b”,“ c”,...,“ z”的得分分别由得分[0],得分[1],...,得分[25
-
如何在MySQL表中设置最大行数?
问题内容: 我需要在MySQL表中设置行的最大限制。文档告诉我们可以使用以下SQL代码创建表: 但是属性不是硬性限制(“存储不超过10万行并删除其他行”),而是数据库引擎的提示,该表将至少有10万行。 我看到的解决问题的唯一可能方法是使用触发器,该触发器将检查表中的行数并删除较旧的行。但是我很确定这是一个巨大的过热:/ 另一种解决方案是每N分钟使用cron脚本清除表。这是最简单的方法,但是仍然需要
-
Java:InvalidAlgorithmParameterException主要大小必须是64的倍数
我实现了一个Java程序,它将使用JSCH在远程服务器中连接和执行命令。问题是,每当我试图连接到服务器时,都会出现以下异常: 我尝试了在jre/lib和security.provider中添加Bouncy Castle提供程序的解决方案,它起作用了。但是我需要使它依赖于项目,所以我尝试在构建路径中添加Bouncy Castle并在程序中手动添加Bouncy Castle提供程序。但是在导出到jar
-
切片到固定大小的数组[重复]
我有一个结构与一些固定大小的数组: 我从一个文件中读取字节到一个固定大小的数组中,并将这些字节逐位复制到结构中。 最后一行()不起作用,因为在结构中它是一个,而是一个切片。我是否可以返回将一个片转换为一个固定大小的数组,就像在一个范围内那样,而不是像我所做的那样说?
-
C:处理大量数字时避免溢出
问题内容: 我已经在C中实现了一些排序算法(用于对整数进行排序),并谨慎地用于存储与数据大小有关的任何内容(因此还包括了计数器和填充物),因为该算法也应使用数千兆字节的数据集进行测试整数 这些算法应该很好,并且分配的数据量应该没有问题:数据存储在文件中,并且每次仅加载很少的块,即使将内存中的缓冲区阻塞为任意大小,也可以正常工作。 使用数据集最多4千兆字节(因此16GB数据)的测试可以正常工作(排序
-
NPTL将最大线程数限制为65528吗?
问题内容: 以下代码假定可以创建100,000个线程: 它运行在具有32GB RAM的64位计算机上;已安装Debian 5.0,所有库存。 ulimit -s 512来减小堆栈大小 / proc / sys / kernel / pid_max设置为1,000,000(默认情况下,上限为32k pid)。 ulimit -u 1000000增加最大进程数(根本不认为这很重要) / proc /
-
5.1.9 09.打印1到最大的n位数
一、题目 输入数字n,按顺序打印出从1到n位最大十进数的数值。比如输入3,则打印出1、2、3一直到最大三位数即999。 二、解题思路 ①使用一个n位的数组来存储每一位的元素。例如n位3,则000表示为[0,0,0]。 使用递归的方式,存放每一位元素值。 ②同上,使用一个n位的数组来存储每一位的元素。然后循环执行加1运算,并在数组中进行模拟进位,直到最高位需要进位,则表示循环结束。 三、解题代码 p
-
17. 打印从 1 到最大的 n 位数
题目描述 输入数字 n,按顺序打印出从 1 到最大的 n 位十进制数。比如输入 3,则打印出 1、2、3 一直到最大的 3 位数即 999。 解题思路 由于 n 可能会非常大,因此不能直接用 int 表示数字,而是用 char 数组进行存储。 使用回溯法得到所有的数。 // java public void print1ToMaxOfNDigits(int n) { if (n <= 0)
-
将数组拆分为大致相等的块
问题内容: 当每个块的总和大致相等时,如何将数组分成两个块? 问题答案: 像这样: 测试:
-
枚举两个大数组的快速方法?
问题内容: 我有两个大阵列需要处理。但是,让我们看一下下面的简化示例以了解这个想法: 我想查找in中的元素是否与in中的元素匹配,并返回两者中的数组索引,以及是否以新数组的形式找到匹配项。例如,使用以下一组和,程序将返回: 我当前的代码如下: 这很好。但是,我正在处理的实际两个数组每个都有60万个项目。上面的代码将非常慢。有什么方法可以加快这个过程? 问题答案: 可能不是最快,但又容易又相当快:使
-
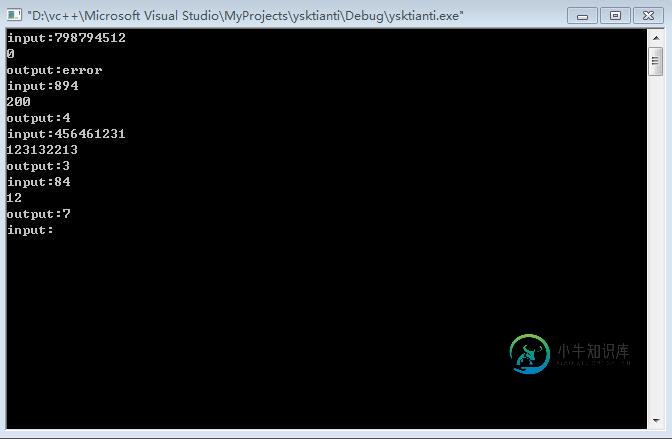 C++使用string的大数除法运算(4)
C++使用string的大数除法运算(4)本文向大家介绍C++使用string的大数除法运算(4),包括了C++使用string的大数除法运算(4)的使用技巧和注意事项,需要的朋友参考一下 本次项目目标:使用C++完成对于大数的除法运算,供大家参考,具体内容如下 项目要点 1.大数指的是远超long long int的数据 2.将大数用矩阵进行存储,并通过矩阵实现运算 3.本人采用字符串进行存储,应注意char的特点 比如:char a=