《大数据》专题
-
如何在不使用阻塞stdio的情况下从node.js的子进程传输大数据/向子进程传输大数据?
问题内容: 我在node.js中有一堆(子)进程,它们需要传输大量数据。 当我阅读该手册时,会说它们之间的stdio和ipc接口已阻塞,因此不会起作用。 我正在研究使用文件描述符,但是我找不到从它们流式传输的方法(请参阅我的其他更具体的问题,如何在node中的文件描述符中流式传输/? 我想我可能会使用网络插座,但是我担心会有不必要的开销。 问题答案: 我找到了一个似乎有效的解决方案:生成子进程时,
-
最多*最多*小数位数的大多数Python方式打印
问题内容: 我想格式化最多不超过2个小数位的浮点数列表。但是,我不想尾随零,也不想尾随小数点。 因此,例如=> ,=> ,=> ,=> 。 简单的解决方案是。但是,这看起来很丑陋,而且看起来很脆弱。还有更好的解决方案,也许带有一些神奇的格式标志? 问题答案: 您需要将和剥离分开;这样你永远不会剥夺自然。 或者,使用函数,但这实际上归结为同一件事: 一些测试:
-
Java:声明大小为n的数组的大O时间是多少?
问题内容: 在Java中声明大小为n的数组的运行时间是多少?我想这将取决于是否在垃圾回收中将内存清零(在这种情况下,内存可能为O(1))或在初始化时(这种情况下,内存必须为O(n))。 问题答案: 是。考虑以下简单程序: 生成的字节码为: 要看的指令就是指令(只需搜索)。从VM规范: 从垃圾收集堆中分配一个新数组,该数组的组件类型为type且长度计数。对该新数组对象的引用arrayref被推入操作
-
问题:将大量数据传递给第二个活动
问题内容: 我有一个奇怪的问题。我正在网上浏览,但没有找到答案。我仍然是android编程的初学者。让我们开始吧: 我要做的就是用一些数据调用第二个Activity。它适用于较小的数据,但是如果数据变大,则第二个活动将不会显示,第一个活动将结束。这是调用方法的代码: 接收数据的部分并不重要。即使我不尝试阅读捆绑软件,也不会调用该活动。我用以下几行进行了测试: 永远不会被调用。 也许您有一个主意…谢
-
处理巨大数据表时应如何使用Hibernate Mapping
问题内容: 问题定义: 我有一个包含大量数据(超过100,000行)的数据库表,表结构像 每个applicationID可能有成千上万的文档,我必须获取按applicationID分组的状态为0的文档数和状态为1的文档数。 当我使用hibernate方式映射该对象时,由于大量的表数据,它将占用大量的堆内存。 如何使用Hibernate查询实现这一目标? 还是我应该为此使用SQL查询或存储过程? 注
-
请问海量数据如何去取最大的k个
本文向大家介绍请问海量数据如何去取最大的k个相关面试题,主要包含被问及请问海量数据如何去取最大的k个时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 1.直接全部排序(只适用于内存够的情况) 当数据量较小的情况下,内存中可以容纳所有数据。则最简单也是最容易想到的方法是将数据全部排序,然后取排序后的数据中的前K个。 这种方法对数据量比较敏感,当数据量较大的情况下,内存不能完全容纳全部数据,这种
-
 JS对大量数据进行多重过滤的方法
JS对大量数据进行多重过滤的方法本文向大家介绍JS对大量数据进行多重过滤的方法,包括了JS对大量数据进行多重过滤的方法的使用技巧和注意事项,需要的朋友参考一下 前言 主要的需求是前端通过 Ajax 从后端取得了大量的数据,需要根据一些条件过滤,首先过滤的方法是这样的: 现在迷糊了,觉得这样处理数据不对,但是又不知道该怎么处理。 发现问题 问题就在过滤上,这样固然可以实现多重过滤(先调用 filterA() 再调用 filterB
-
如何在Django JSONField数据上聚合(最小/最大等)?
问题内容: 我正在使用内置的Django 1.9 和Postgres 9.4。在模型的json字段中,我存储带有一些值(包括数字)的对象。我需要汇总它们以找到最小/最大值。像这样: 另外,提取特定的密钥将很有用: 上面的查询失败了 FieldError:“无法将关键字’my_key’解析为字段。不允许加入’attrs’。” 有可能吗? 笔记: 我知道如何进行简单的Postgres查询来完成这项工作
-
使用Json.net以JSON格式流式传输大量数据
问题内容: 使用MVC模型,我想编写一个JsonResult,它将Json字符串流式传输到客户端,而不是一次将所有数据转换成Json字符串,然后将其流回客户端。我有一些动作需要在Json传输时发送非常大的记录(超过300,000条记录),我认为基本的JsonResult实现是不可伸缩的。 我正在使用Json.net,我想知道是否有一种方法可以在转换Json字符串时流化它的块。 但是我不确定如何将这
-
php导入大量数据到mysql性能优化技巧
本文向大家介绍php导入大量数据到mysql性能优化技巧,包括了php导入大量数据到mysql性能优化技巧的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了php导入大量数据到mysql性能优化技巧。分享给大家供大家参考。具体分析如下: 在mysql中我们结合php把一些文件导入到mysql中,这里就来分享一下我对15000条记录进行导入时分析与优化,需要的朋友可以参考一下. 之前有几篇文章
-
将大文件中的数据分块进行多处理?
问题内容: 我正在尝试使用多重处理来并行化应用程序,该处理程序会处理一个非常大的csv文件(64MB至500MB),逐行执行一些工作,然后输出一个固定大小的小文件。 目前,我正在执行,不幸的是,它已完全加载到内存中(我认为),然后我将该列表分成了n个部分,n是我要运行的进程数。然后,我在分类列表上执行。 与单线程,仅打开文件并迭代的方法相比,这似乎具有非常非常糟糕的运行时。有人可以提出更好的解决方
-
MySQL数据库表分区注意事项大全【推荐】
本文向大家介绍MySQL数据库表分区注意事项大全【推荐】,包括了MySQL数据库表分区注意事项大全【推荐】的使用技巧和注意事项,需要的朋友参考一下 表分区与数据库分区是不一样的那么碰到表分区使用时我们要注意一些什么事情呢,今天我们来看一篇关于MySQL数据库表分区注意事项的细节。 1、分区列索引约束 若表有primary key或unique key,则分区表的分区列必须包含在primary ke
-
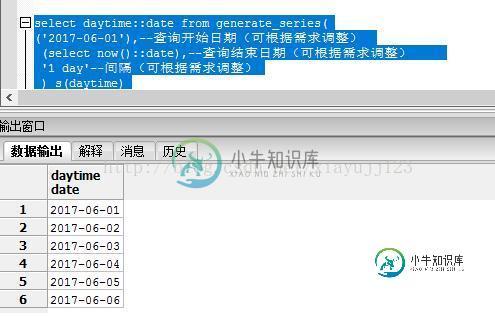 postgresql 实现取出分组中最大的几条数据
postgresql 实现取出分组中最大的几条数据本文向大家介绍postgresql 实现取出分组中最大的几条数据,包括了postgresql 实现取出分组中最大的几条数据的使用技巧和注意事项,需要的朋友参考一下 看代码吧~ 其中 执行结果: 添加行序号:ROW_NUMBER () OVER (ORDER BY A.bsm ASC) AS 序号 分组添加序号:ROW_NUMBER () OVER (PARTITION BY xzqdm ORDER
-
传递大量数据的查询的最佳MySQL设置?
问题内容: 我从事科学家工作,并使用MySQL作为数值模拟结果的存储库。通常,我有一组通过实验获得的数据和一个对照组。这两个数据集存储在一个表中。一个指示符字段告诉我记录是来自实验还是来自控件集。该表通常具有约1亿条记录。5000万次实验和5000万个控件。 在对数据进行后处理时,我的典型任务是首先发出以下两个查询: 和 我在RC,df上有一个多列索引。这些查询会花费大量时间,而查询会花费大部分时
-
MySQL快速从大型数据库中删除重复项
问题内容: 我有大的(>百万行)MySQL数据库被重复弄乱了。我认为这可能是充满它们的整个数据库的1/4到1/2。我需要快速摆脱它们(我是指查询执行时间)。外观如下: id(索引)| text1 | text2 | text3 text1&text2组合应该是唯一的,如果有重复项,则仅应保留一个text3 NOT NULL组合。例: …成为: 新的id可以是任何东西,它们不依赖于旧表的id。 我已