《大数据》专题
-
Grails,使用withTransaction插入大量数据会导致OutOfMemoryError
问题内容: 我正在使用Grails 1.1 beta2。我需要将大量数据导入Grails应用程序。如果我反复实例化grails域类然后保存它,则性能会降低到无法接受的程度。以从电话簿导入人为例: 事实证明这是缓慢的。Grails邮件列表上的某人建议在事务中分批保存。所以现在我有: 这必须至少在开始时更快。每笔交易会保存500条记录。随着时间的流逝,交易花费的时间越来越长。最初的几笔交易大约需要5秒
-
数据透视表还是大熊猫分组依据?
问题内容: 我有一个非常希望直截了当的问题,在最近3个小时中,这一直给我带来很多困难。应该很容易。 这是挑战。 我有一个熊猫数据框: 我想要将数据框转换为: 值是值计数。有人有见识吗?谢谢! 问题答案: 这是重塑数据的几种方法 1) 使用 2) 或者,在over上使用,然后填充零。 3) 或者使用与, 4) 或者,与
-
无法通过phpmyadmin文件导入数据库太大
问题内容: 我一直在尝试通过phpMyAdmin导入数据库。我的数据库文件是,它的大小是1.2 GB,我正在尝试将其导入本地,并且phpMyAdmin表示: 您可能试图上传太大的文件。请参阅文档以了解解决此限制的方法。 请帮助我,我真的需要这个工作。 问题答案: 这是由于PHP对上传文件具有文件大小限制。 如果您具有终端机/外壳程序访问权限,则以上答案@Kyotoweb将起作用。 一种实现方法是创
-
php计算整个mysql数据库大小的方法
本文向大家介绍php计算整个mysql数据库大小的方法,包括了php计算整个mysql数据库大小的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了php计算整个mysql数据库大小的方法。分享给大家供大家参考。具体如下: 这里用MB,KB或者GB的格式返回计算结果。 希望本文所述对大家的php程序设计有所帮助。
-
Elasticsearch未分配的碎片CircuitBreakingException[[父级]数据太大
我收到警报说elasticsearch有两个未分配碎片。我进行了以下api调用以收集更多细节。 以下输出 我查询了断路器配置 并且可以看到3个节点(elasticsearch-data-0、elasticsearch-data-1和elasticsearch-data-2)的父limit_size_in_byes如下所示。 我参考了这个答案https://stackoverflow.com/A/6
-
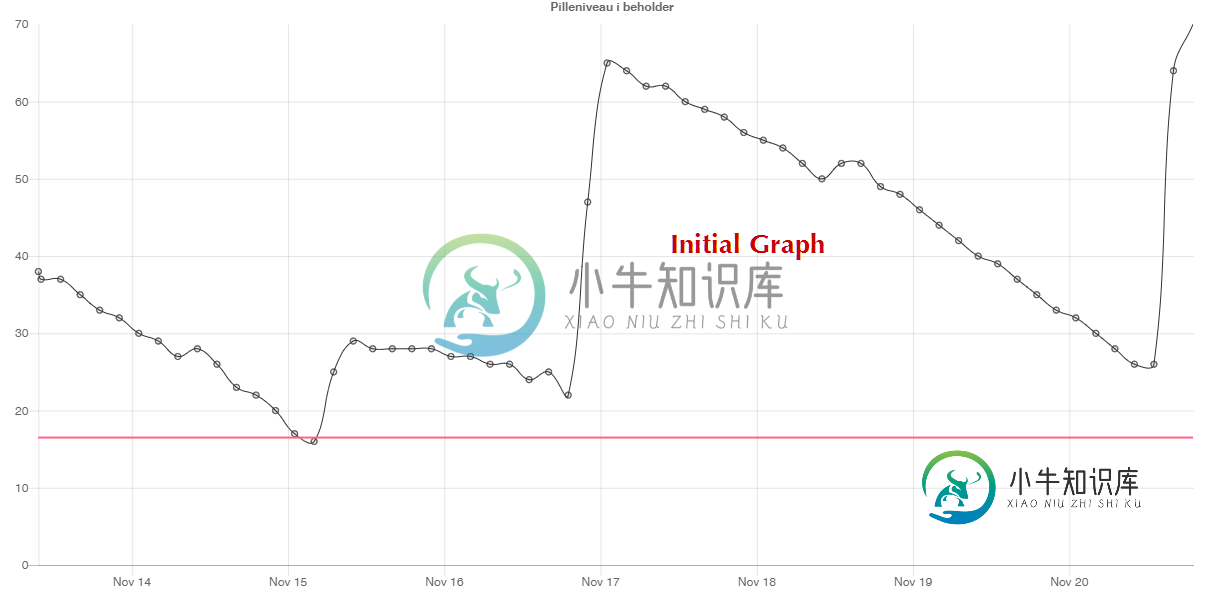 用不同大小的数据集更新chart.js图表
用不同大小的数据集更新chart.js图表我设置了一个chart.js图表,它使用mysql数据库中的数据。我已经建立了一个rest服务来提供tha数据,具有定义分组IE的能力。数据每隔5分钟测量一次,但我将其分组为3小时段,使用我的SQL语句 我希望能够通过定义一个新的粒度来改变数据的粒度。 我创建了一个更新函数来将请求发送到后端,并更新图表。 图表已更新,但默认值有61个条目(目前),最细粒度的数据有180个条目。所发生的情况是,数据
-
 根据数量动态布局固定大小的div
根据数量动态布局固定大小的div对你来说有点困惑...... 我有一个730px宽,自动高度div。在这里面,我将小div的数量164px X 261px。 这些将被动态地拉入模板,所以我可以有1个,或者我可以有18个,或者为了这个练习,我可以有1000个,或者介于两者之间的任何地方。 我需要把它们隔开,这样每一行之间就有相等的距离。简单,如果我们处理多达4个,我可以这样做: 然而,当有人说5。我想要3个在最上面一排,2个在最下
-
Neo4j/Spring数据Neo4j 4索引和字符大小写
我有以下SDN 4节点实体: 在这个实体内部,我添加了属性并声明了一个索引。 现在,我将按产品名称实现不区分大小写的搜索。 我创建了一个SDN 4存储库方法: 为了搜索产品,我使用以下密码: 我认为索引在这种情况下不能有效地工作,因为我小写了字符串。 Neo4j/SDN 4中使索引在这里工作的正确方法是什么?
-
使用J2ME存储大量数据的最佳实践
问题内容: 我正在开发一个J2ME应用程序,该应用程序具有要存储在设备上的大量数据(大约1MB,但是可变)。我不能依靠文件系统,所以我卡住了记录管理系统(RMS),该系统允许多个记录存储,但每个记录存储空间都有限。我最初的目标平台Blackberry将每个限制为64KB。 我想知道是否还有其他人必须解决在RMS中存储大量数据的问题,以及他们如何进行管理?我正在考虑必须计算记录大小并在多个存储区中拆
-
Java:将大量数据序列化为单个文件
问题内容: 我需要将大量小对象的数据(大约2gigs)序列化为单个文件,以便稍后由另一个Java进程进行处理。性能是很重要的。谁能建议一个好的方法来实现这一目标? 问题答案: 您是否看过Google的协议缓冲区?听起来像是一个用例。
-
 mysql大数据查询优化经验分享(推荐)
mysql大数据查询优化经验分享(推荐)本文向大家介绍mysql大数据查询优化经验分享(推荐),包括了mysql大数据查询优化经验分享(推荐)的使用技巧和注意事项,需要的朋友参考一下 正儿八经mysql优化! mysql数据量少,优化没必要,数据量大,优化少不了,不优化一个查询10秒,优化得当,同样查询10毫秒。 这是多么痛的领悟! mysql优化,说程序员的话就是:索引优化和where条件优化。 实验环境:MacBook Pro MJ
-
如何将巨大的pandas数据帧保存到HDFS?
问题内容: 我正在处理熊猫和Spark数据帧。数据帧始终很大(> 20 GB),而标准的火花功能不足以容纳这些大小。目前,我将我的pandas数据框转换为spark数据框,如下所示: 我进行这种转换是因为通过火花将数据帧写入hdfs非常容易: 但是,对于大于2 GB的数据帧,转换失败。如果将spark数据框转换为熊猫,则可以使用pyarrow: 这是从Spark到Panda的快速对话,它也适用于大
-
 Python对接六大主流数据库(只需三步)
Python对接六大主流数据库(只需三步)本文向大家介绍Python对接六大主流数据库(只需三步),包括了Python对接六大主流数据库(只需三步)的使用技巧和注意事项,需要的朋友参考一下 作为近两年来最火的编程语言的python,受到广大程序员的追捧必然是有其原因的,如果要挑出几点来讲的话,第一条那就python语法简洁,易上手,第二条呢? 便是python有着极其丰富的第三方的库。 所以不管你使用的关系型数据库是oracle,mysq
-
将大熊猫数据帧分块写入CSV文件
问题内容: 如何将大数据文件分块写入CSV文件? 我有一组大型数据文件(1M行x 20列)。但是,我只关注该数据的5列左右。 我想通过只用感兴趣的列制作这些文件的副本来使事情变得更容易,所以我可以使用较小的文件进行后期处理。因此,我计划将文件读取到数据帧中,然后写入csv文件。 我一直在研究将大数据文件以块的形式读入数据框。但是,我还无法找到有关如何将数据分块写入csv文件的任何信息。 这是我现在
-
php快速导入大量数据的实例方法
本文向大家介绍php快速导入大量数据的实例方法,包括了php快速导入大量数据的实例方法的使用技巧和注意事项,需要的朋友参考一下 PHP快速导入大量数据到数据库的方法 第一种方法:使用insert into 插入,代码如下: 最后显示为:23:25:05 01:32:05 也就是花了2个小时多! 第二种方法:使用事务提交,批量插入数据库(每隔10W条提交下)最后显示消耗的时间为:22:56:13 2