《大数据》专题
-
如何获取MySQL数据库表的大小?
问题内容: 我可以运行此查询来获取MySQL数据库中所有表的大小: 我希望对了解结果有所帮助。我正在寻找尺寸最大的桌子。 我应该看哪一列? 问题答案: 您可以使用此查询显示表的大小(尽管您需要先替换变量): 或此查询以列出每个数据库中每个表的大小,从大到大:
-
如何在大型数据库中使用typeahead.js
问题内容: 我有10,000个地址和5,000人的大型数据库。 我想让用户在数据库中搜索地址或用户。在输入文本时,我想使用Twitter的提前提示功能来建议结果。 在此处查看NBA示例:http : //twitter.github.io/typeahead.js/examples。 我了解从速度和负载的角度来看,预取15,000个项目并不是最佳选择。尝试实现此目标的更好方法是什么? 问题答案:
-
大话C语言变量和数据类型
主要内容:变量(Variable),数据类型(Data Type),连续定义多个变量,数据的长度(Length),最后的总结在《 数据在内存中的存储》一节中讲到: 计算机要处理的数据(诸如数字、文字、符号、图形、音频、视频等)是以二进制的形式存放在内存中的; 我们将8个比特(Bit)称为一个字节(Byte),并将字节作为最小的可操作单元。 我们不妨先从最简单的整数说起,看看它是如何放到内存中去的。 变量(Variable) 现实生活中我们会找一个小箱子来存放物品,一来显得不那么凌乱,二来方便以后
-
数据流大侧输入中的Apache波束
这与这个问题最为相似。 我正在Dataflow 2.x中创建一个管道,它从Pubsub队列获取流式输入。进入的每一条消息都需要通过来自Google BigQuery的一个非常大的数据集进行流式传输,并且在写入数据库之前附加了所有相关的值(基于一个键)。 问题是来自BigQuery的映射数据集非常大--任何将其用作侧输入的尝试都失败了,数据流运行程序会抛出错误“java.lang.IllegalAr
-
TOIT中的UDP和TCP/IP数据包大小
在实验运行在esp32上的UDP服务器时,我发现接收到的数据包的大小限制在1500字节: 20(IP头)8(UDP头)1472(数据),(尽管理论上UDP好像可以支持数据包64K)。这意味着,为了传输更大量的数据,客户端必须将其拆分成若干块并依次发送,而在服务器端,这些数据将需要恢复。我认为这种解决方案的管理费用将相当高。我还知道TOIT提供TCP/IP连接。自然,分组大小在TCP/IP的情况下也
-
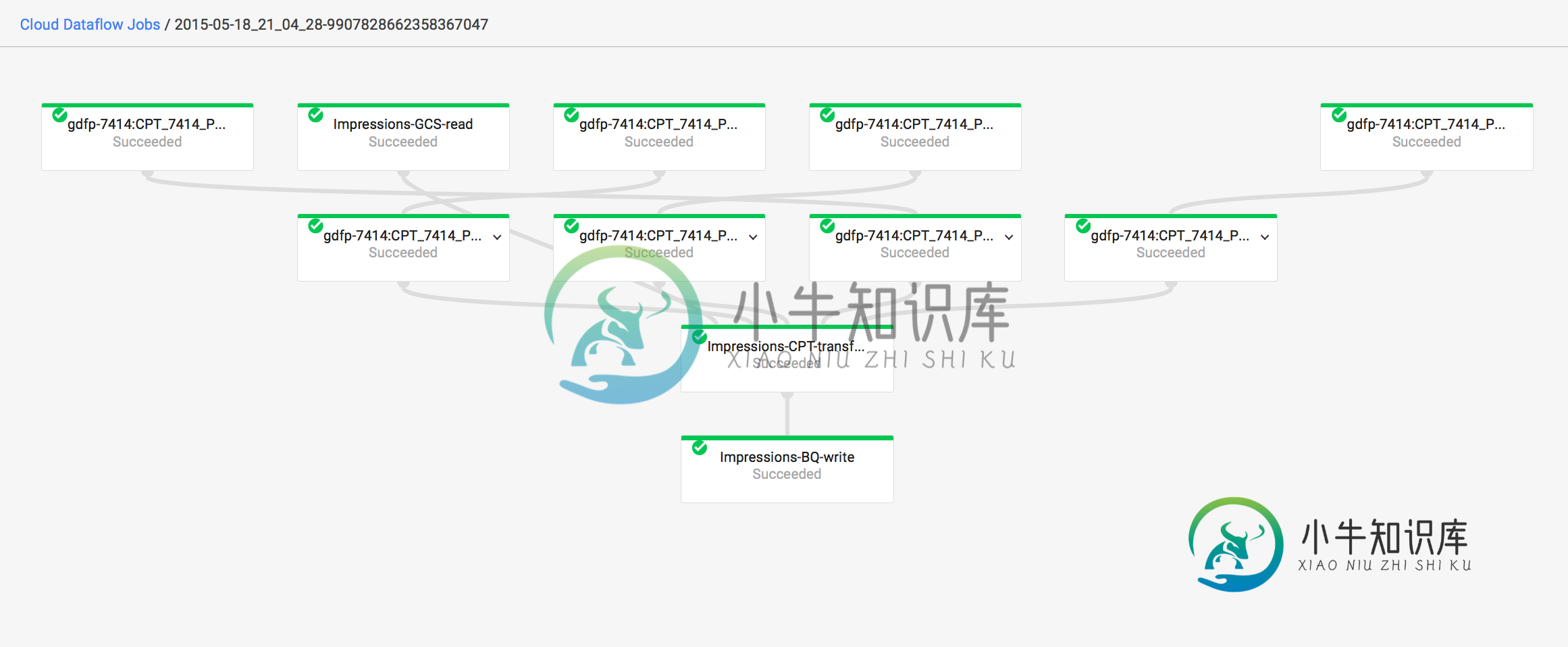 数据流错误-“源太大。限制为5.00ti”
数据流错误-“源太大。限制为5.00ti”BigQuery->ParDo->BigQuery 该表有~2B行,不到1TB。 运行了8个多小时后,作业失败,出现以下错误: 作业id为:2015-05-18_21_04_28-9907828662358367047 此外,即使作业失败,它仍然在图表上显示为成功。为什么?
-
Neo4j和spring-data-Neo4j-导入大型数据集
我正在使用数据库和。现在,我想导入相当大的数据集,因此我研究了的批插入功能。 经过我的研究,我发现: 用于嵌入式数据库:http://docs.neo4j.org/chunked/stable/batchinsert.html以及使用它的Michael Hunger项目:https://github.com/jexp/batch-import/ REST批处理终结点:http://docs.neo
-
Java大数据结构用于存储矩阵
问题内容: 我需要存储一个2d矩阵,其中包含邮政编码以及每个邮政编码之间的距离(以km为单位)。我的客户有一个计算距离的应用程序,然后将其存储在Excel文件中。目前,有952个地方。因此,矩阵将具有952x952 = 906304条目。 我试图将其映射到HashMap [Integer,Float]。整数是两个字符串在两个位置(例如“ A”和“ B”)的哈希码。浮点值是它们之间的距离(以公里为单
-
功能强大的PHP POST提交数据类
本文向大家介绍功能强大的PHP POST提交数据类,包括了功能强大的PHP POST提交数据类的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了PHP功能强大的 POST提交数据类,供大家参考,具体内容如下 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
从php中的csv文件读取大数据
问题内容: 我正在读取csv并与mysql检查记录是否存在于我的表中或不在php中。 csv大约有25000条记录,当我运行我的代码时,它在2m 10s后显示“服务不可用”错误(加载:2m 10s) 在这里我添加了代码 注意:我只想列出表中不存在的记录。 请为我建议解决方案… 问题答案: 首先,您应该了解,在使用file_get_contents时,您会将整个数据字符串提取到一个变量中,该变量存储
-
Python—将不同大小的数据帧相乘
我有两个数据帧: df1-是一个透视表,它包含列和行的总数,两者都具有默认名称“全部”df2-我通过指定值并使用与上面透视表中使用的相同的索引和列名手动创建的df。本表没有总数。 我需要将第一个数据帧乘以第二个数据帧中的值。我希望总数返回NaN,因为总数不存在于第二个表中。 当我执行乘法运算时,我得到以下错误:
-
使用MapReduce / Hadoop对大数据进行排序
问题内容: 我正在阅读有关MapReduce的内容,以下内容使我感到困惑。 假设我们有一个包含一百万个条目(整数)的文件,并且我们想使用MapReduce对它们进行排序。我了解的处理方式如下: 编写一个对整数排序的映射器函数。因此,框架会将输入文件分为多个块,并将它们分配给不同的映射器。每个映射器将彼此独立地对数据块进行排序。完成所有映射器后,我们会将其每个结果传递给Reducer,它将合并结果并
-
MySQL数据库基础命令大全(收藏)
本文向大家介绍MySQL数据库基础命令大全(收藏),包括了MySQL数据库基础命令大全(收藏)的使用技巧和注意事项,需要的朋友参考一下 整理了一下mysql基础命令,分享一下 以上所述是小编给大家介绍的MySQL数据库基础命令大全,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对呐喊教程网站的支持!
-
Android数据库大小不会减少HTC Thunderbolt
问题内容: 更新:db-wal文件太大了。是什么原因,如何限制sqlite日志文件的大小? 我正在使用SQLiteOpenHelper。当发生onUpgrade时,我将删除我的应用程序中存在的每个表。当我使用设置应用程序查看应用程序数据大小时,在机器人上,您可以看到数据大小会减小。但是使用HTC Thunderbolt时,数据大小不会减少。更糟糕的是,当您再次开始使用我的应用程序时,Thunder
-
awk 强大地处理表格数据(CSV等)
本文向大家介绍awk 强大地处理表格数据(CSV等),包括了awk 强大地处理表格数据(CSV等)的使用技巧和注意事项,需要的朋友参考一下 示例 只要输入的格式正确,用awk处理表格数据非常容易。大多数产生表格数据的软件都使用该格式系列的特定功能,并且处理表格数据的awk程序通常特定于特定软件所产生的数据。如果需要更通用或更健壮的解决方案,则大多数流行语言都提供了包含表格式数据中许多功能的库: 第