《小红书信息集散地》专题
-
机器人信息
机器人信息 包含机器人的基本信息和服务管理。在机器人列表页点击“基本信息”,跳转到机器人信息页面;或者点击“设置机器人”,在机器人详情页点击左侧的“机器人信息”,也可以进入机器人信息页面。 基本信息 基本信息包括机器人昵称和头像设置。 服务管理 服务管理客队机器人服务功能进行设置,现主要分为六大类:日常聊天、物流查询、自动对联、机器写诗、知识问答、自定义闲聊。选择服务功能的开启之后,便可点击左下角
-
6 用户信息
用户信息模块可以查看用户的基本信息,使用量,信息设置等。 6.1 用户使用量 6.2 消息设置
-
3.10 修改地图信息
单击地图信息选项卡,可以查看当前地图的信息。单击地图名称旁边的 笔状图标,可以修改当前地图的信息。
-
数学组合的完美最小散列
首先,定义两个整数和,其中,两者在编译时都已知。例如:和。 接下来,定义一组整数(或者,如果这使答案更简单的话),并将其称为。例如: 具有元素的子集的数目由公式给出。例 我的问题是:为这些子集创建一个完美的最小哈希。示例哈希表的大小为或。 我不关心排序,只关心哈希表中有56个条目,并且我可以从一组整数中快速确定哈希。我也不在乎可逆性。 哈希示例:。(数字42并不重要,至少在这里不重要) 是否有一种
-
 Web 开发者 CentOS 小书
Web 开发者 CentOS 小书这本 CentOS 小书是对 CentOS 系统知识的一个整理以及补完,当然对于其它 Linux 发行版本也有很大的参考意义,但的确针对的是目前 CentOS 的最新版本 CentOS 7。
-
 Spring Boot生成信息通过/信息执行器endpoint
Spring Boot生成信息通过/信息执行器endpoint在Spring Boot应用程序中,我想通过从插件任务中获取执行器endpoint中的构建和其他应用程序相关信息。但是,构建信息属性文件名不是,而是不同的。属性文件存在于Spring引导创建的胖罐中的中。 我的问题是:有没有什么方法可以在任务中配置属性文件名而不是采用默认值? 更新:
-
获取构建信息 - 获取任务具体信息
执行 gradle help —task someTask 可以显示指定任务的详细信息. 或者多项目构建中相同任务名称的所有任务的信息. 如下例. 例 11.12. 获取任务帮助 gradle -q help —task libs的输出结果 > gradle -q help --task libs Detailed task information for libs Paths :api
-
信息流推广报告告诉我哪些信息
使用指南 - 数据报告 - 百度推广 - 信息流推广报告告诉我哪些信息 信息流推广报告提供百度信息流推广中已投放的计划单元给您网站带来的流量情况。您可以通过此报告了解信息流推广中所有已投放计划单元的效果,并且有依据地优化各个投放定向,从而不断提升百度信息流推广的投资回报率。 信息流推广流量可以分别按计划、单元、创意查看,也可以选择授权账户,查看其他授权账户的推广流量。 报告下方是对应的具体计划、单
-
如何获取垃圾收集对象的统计信息?
是否可以看到被设为null的java对象(及其类类型)以及 尚未收集/清理垃圾 垃圾收集/清理。 此统计信息将有助于了解有多少对象重复创建(通过错误的逻辑)而不是一次性创建。
-
如何在spring集成框架中屏蔽敏感信息
我需要在登录时屏蔽敏感信息。我们使用集成框架提供的wire-tap进行日志记录,我们已经设计了许多接口,这些接口使用wire-tap进行日志记录。我们目前正在使用spring boot 2.1和spring集成。
-
在 Dreamweaver 中使用表单从用户处收集信息
注意:用户界面已经在 Dreamweaver CC 和更高版本中做了简化。因此,您可能在 Dreamweaver CC 和更高版本中找不到本文中描述的一些选项。有关详细信息,请参阅此文章。 关于从用户处收集信息 可以用 Web 表单或超文本链接来从用户处收集信息,将信息存储在服务器的内存中,然后根据用户的输入用这些信息来创建动态响应。收集信息最常用的工具是 HTML 表单和超文本链接。 HTML
-
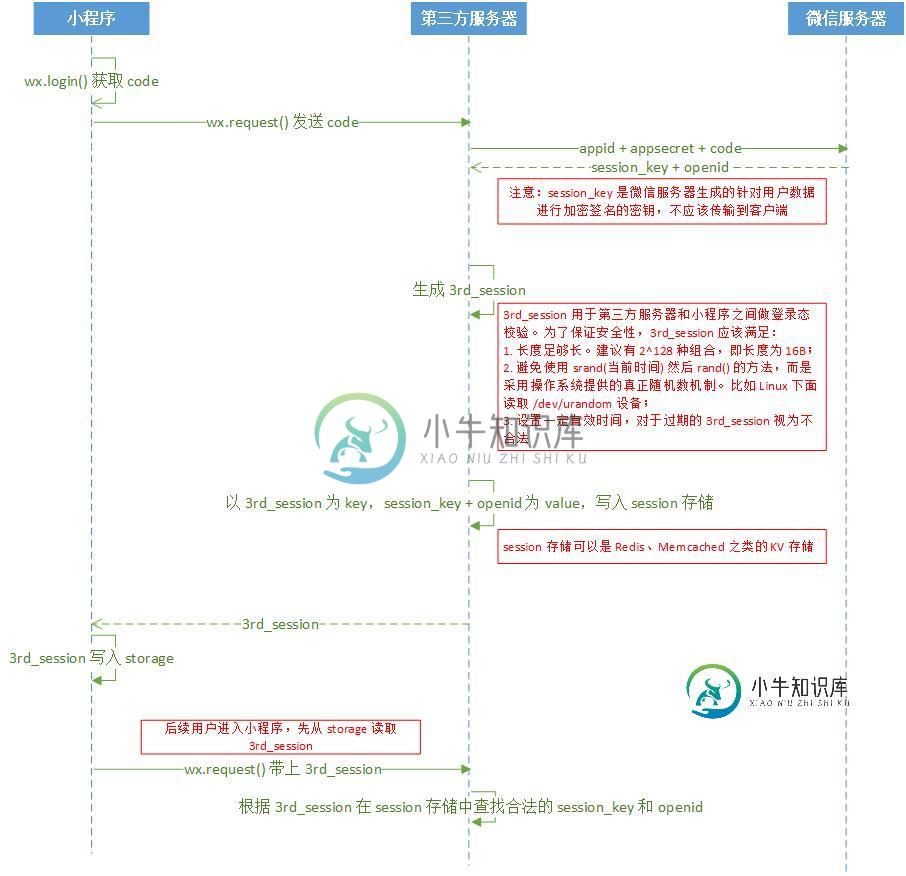 微信小程序获取用户信息并保存登录状态详解
微信小程序获取用户信息并保存登录状态详解本文向大家介绍微信小程序获取用户信息并保存登录状态详解,包括了微信小程序获取用户信息并保存登录状态详解的使用技巧和注意事项,需要的朋友参考一下 前言 微信小程序的运行环境不是在浏览器下运行的。所以不能以cookie来维护登录态。下面我就来说说我根据官方给出的方法来写出的维护登录态的方法吧。 一、登录态维护 官方的文档地址:https://mp.weixin.qq.com/debug/wxadoc/
-
 微信小程序连接服务器展示MQTT数据信息的实现
微信小程序连接服务器展示MQTT数据信息的实现本文向大家介绍微信小程序连接服务器展示MQTT数据信息的实现,包括了微信小程序连接服务器展示MQTT数据信息的实现的使用技巧和注意事项,需要的朋友参考一下 一、 实现工具——微信开发者工具 为何使用微信小程序作为展示? (1)范围广且能跨平台访问; (2)小而快能够快速的访问; 二、 实现步骤 1、总体大概: (1)界面设计:数据直观展示+历史数据+物联网调试信息 (2)连接服务器与回调 利用wx
-
java中的SSL可信证书
我们需要显式地将受信任的CA证书导入java密钥库吗?如果是,为什么? 我可以理解,我们应该始终将自签名SSL证书导入密钥库,因为它们不是经过验证的证书,除非密钥库中有java,否则无法信任。但是,即使对于可信CA生产证书,我们也需要执行同样的操作吗? 注意:我使用的是jdk v1。6.x。
-
在HDFS读书,给HBASE写信
Mapper正在从两个地方读取文件1)用户访问的文章(按国家排序)2)国家统计(国家明智) 两个Mapper的输出都是Text,Text 我正在运行Amazon集群的程序 我的目标是从两个不同的集合中读取数据,并将结果组合起来存储在hbase中。 HDFS到HDFS正在工作。代码在减少67%时卡住了,并给出了如下错误: 驱动程序类是 减速器等级为 属国