《格力结构设计岗》专题
-
1. 数据结构的概念
1. 数据结构的概念 数据结构(Data Structure)是数据的组织方式。程序中用到的数据都不是孤立的,而是有相互联系的,根据访问数据的需求不同,同样的数据可以有多种不同的组织方式。以前学过的复合类型也可以看作数据的组织方式,把同一类型的数据组织成数组,或者把描述同一对象的各成员组织成结构体。数据的组织方式包含了存储方式和访问方式这两层意思,二者是紧密联系的。例如,数组的各元素是一个挨一个存
-
15.6 集合数据结构Set
数据结构是一个容器,用于将一些数据组织到单个对象中。我们已经见过了几个数据结构,比如apstring是一些字符组成,而apvector是一组相同类型(可以是任意数据类型)的元素组成。 有序集是由一些项组成的集合,它有两个决定性的属性: 有序性:集合中的元素都有一个相应的索引。我们可以通过这些索引确定集合中的元素。 唯一性:集合中每个元素只能出现一次。向集合中添加一个已经存在的元素是没有效果的。 此
-
8.5 作为参数的结构
你能以通常做法把结构作为参数传递。例如: void printPoint ( Point p) { cout << "(" << p.x << ", " << p.y << ")" << endl; } printPoint方法把一个point作为参数,并以标准格式将其输出。若调用printPoint(blank),则会输出(3,4)。 作为第二个例子,可重写5.2节的distance函
-
8.4 对结构体的操作
大多数我们在其他类型上使用的操作符,例如数学运算符( +, %等)以及比较运算符(==,>等),都不适用于结构体。事实上,可以为这种新类型定义这些操作符的含义,不过在这本书中我们不会这么做。 另一方面,赋值运算符确实适用于结构。它可以用在两种方式上:初始化结构的实例变量或把实例变量从一个结构复制到另一个结构。一个初始化结构看起来像这样: Point blank = { 3.0, 4.0 }; 大
-
23. Maven 结构项目搭建
学习前提 相对于传统的项目,Maven 下管理和构建的项目真的非常好用和简单,所以这里也强调下,尽量使用此类工具进行项目构建。 学习本讲还有一个前提:你必须会 Maven 相关知识点,Maven 相关知识点是不在本专题的讲解范围里面的,所以请自己私下进行学习。如果愿意你也可以看我过去整理的一份视频(提取码:wh5g):http://pan.baidu.com/s/1eSovBkI Maven 常用
-
03 Rails 应用程序结构
Rails 有一个有趣的特点,它会对你的 web 应用结构增加限制。不过,这些限制使它更加容易创建应用。让我们看看其中的原因。 Models, Views 和 Controllers 回到 1979 年,Trygve Reenskaug 提出了开发交互应用的一个新架构。在他的设计中,应用分离为三种类型的组件:model,view 和 controller。 model 负责维护应用的状态。有时状态
-
第三章 Forms 代码结构
读者们会发现迄今为止我们提供的Scheme示例程序也都是s-表达式。这对所有的Scheme程序来说都适用:程序是数据。 因此,字符数据#\c也是一个程序,或一个代码结构。我们将使用更通用的说法代码结构而不是程序,这样我们也可以处理程序片段。 Scheme计算代码结构#\c得到结果#\c,因为#\c可以自运算。但不是所有的s-表达式都可以自运算。比如symbol 表达式 xyz运算得到的结果是xyz
-
InnoDB的内存结构源码
主要内容:一、说明,二、Buffer Pool,三、Change Buffer,四、ADaptive Hash Index,五、Log Buffer,六、总结一、说明 本来是想在前面的一篇分析中把源码和内容同时过一遍,可突然发现,那可能是非常大的一章。所以就把源码独立了出来,在此章节中对相关四类内存数据结构进行分析,在代码分析过程中,可以和前面的说明以及早先的日志分析一并进行对比,会有更大的收获。 二、Buffer Pool 按照老规矩,先看数据结构的定义相关代码: 此数据结构体的定义前面的说明
-
InnoDB的内存结构分析
主要内容:一、基本的数据结构,二、Buffer Pool,三、Change Buffer,四、ADaptive Hash Index,五、Log Buffer,六、总结一、基本的数据结构 在InnoDB中,数据的分配和存储也有自己的数据结构,在前面分析过MySql中的内存管理,但是内存管理是有一个不断抽象的过程。在InnoDB中还会有一层自己的内存管理。在InnoDB引擎中的内存结构主要有四大类: 1、Buffer Pool 在MySql中,数据都是存储在磁盘中的,也就是说,从理论上讲,每次做S
-
基础的数据结构quicklist
主要内容:一、quicklist,二、源码分析,三、总结一、quicklist 再看一下quicklist,它是从Redis3.2才提供的一个数据结构。从字面意思上理解,这个应该比list快。但是同样是list,为什么它要快?就得找一下原因。在普通的list中,可以通过拥有的前向和后向指针进行前后的遍历和查找。但是,当数据量大时,这两个指针占用的空间就非常明显了。而在前面的ziplist中,可以看到,通过指示本Entry的长度配合相关标识,就可以去除这
-
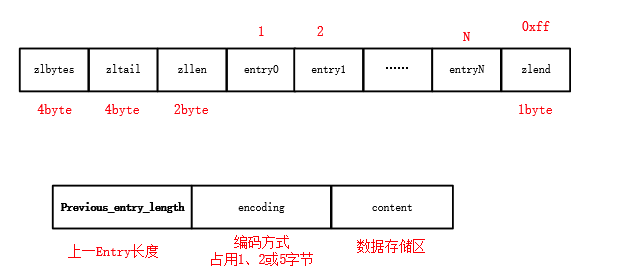 基础的数据结构ziplist
基础的数据结构ziplist主要内容:一、ziplist压缩列表,二、源码分析,三、总结一、ziplist压缩列表 压缩列表是HASH和跳表的小数据时的数据结构,这个在前面提到过。压缩列表的定义和使用其实在源码的头部说明中是很清楚的。看一下英文的注释: The ziplist is a specially encoded dually linked list that is designed to be very memory efficient. It stores both st
-
 基础的数据结构skiplist
基础的数据结构skiplist主要内容:一、skiplist 跳表,二、源码分析,三、总结一、skiplist 跳表 跳表这个数据结构是新生的,在学习数据结构的时候儿是没有这个的。当然,也可以理解成是对数据结构的进一步的封装,这样理解的话,可能就会更准确一些。为什么叫跳表?想想生活中跳的动作,一般人走路是一步一步的走,而如果跳跃的话,一下子可以走好几步,但是付出的代价就是要多费些力气。 其实跳表也是如此,正常的链表list,访问的时候儿是从头到尾(或者反过来)一条条的遍历,而跳表由于多
-
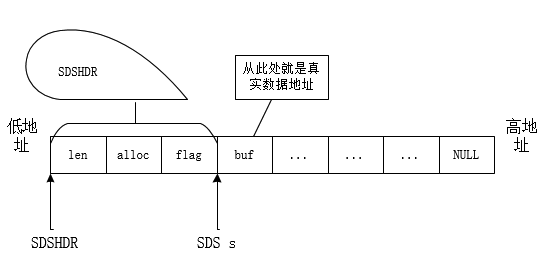 基础的数据结构SDS
基础的数据结构SDS主要内容:一、SDS,二、源码分析,三、总结一、SDS 在前面的初步介绍中,知道Redis中的字符串是SDS——simple dynamic string,可能对于非c++人员有点不好理解,其实如果看STL的代码中std::string的实现,可能就会发现,其实有些类似,而且SDS相对简单不少。SDS除了可以实现字符串,其实还可以用来做缓冲区,毕竟char*的定义本身在C/C++中都是天然做为缓冲区的。 使用char*来操作字符串,但是底层
-
Golang 指向结构体指针
Go 语言中指向结构体的指针和 C 语言一样 结构体和指针 创建结构体指针变量有两种方式 package main import "fmt" type Student struct { name string age int } func main() { // 创建时利用取地址符号获取结构体变量地址 var p1 = &Student{"lnj", 33}
-
2.1 iOS文件目录结构
出于安全考虑,iOS系统把每个应用以及数据都放到一个沙盒(sandbox)里面,应用只能访问自己沙盒目录里面的文件、网络资源等(也有例外,比如系统通讯录、照相机、照片等能在用户授权的情况下被第三方应用访问)[1]。 请注意,使用沙盒的目的是为了防止被攻击的应用危害到系统或者其他应用,它并不能阻止应用本身被攻击,因此,开发者需要防御式的编程来避免应用被攻击。苹果官方是这样说的: Important: