《交互设计面经》专题
-
第20章 设计模式
第20章 设计模式 C语言设计模式 单例模式 原型模式 组合模式 模板模式 工厂模式 抽象工厂模式 责任链模式 迭代器模式 外观模式 代理模式 享元模式 装饰模式 适配器模式 策略模式 中介者模式 建造者模式 桥接模式 观察者模式 备忘录模式 解析器模式 命令模式 状态模式 访问者模式
-
UI 设计基础 通知
Apple Watch上的通知可促使用户与本地或者远程通知进行快速、轻量级的交互。这些交互主要发生在两个阶段,分别由Short-Look和Long-Look界面管理。当本地或者远程通知首次到达时展示Short-Look界面,该界面为用户展示了深思熟虑的最小化信息-保护一定程度的隐私。如果用户压低手腕,Short-Look会消失。如果用户手腕抬高或者点击Short-Look界面,则会展示Long-L
-
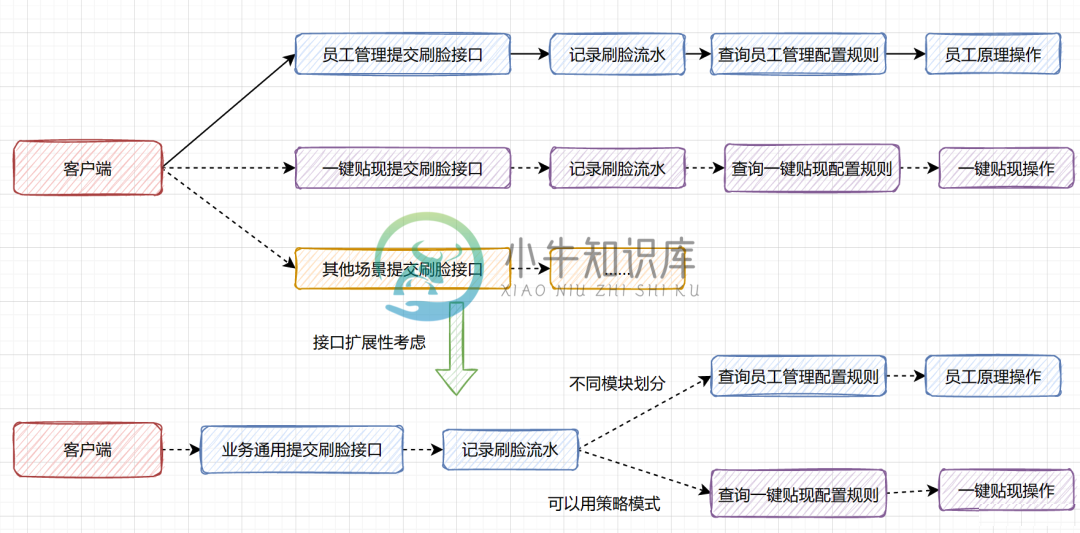 如何设计好接口
如何设计好接口主要内容:1.接口参数校验,2.注意接口的兼容性,3.充分考虑接口的可扩展性,4.接口考虑是否需要防重处理,5.重点接口考虑线程池隔离,6.调用第三方接口要考虑异常和超时处理,7.接口实现考虑熔断和降级,8.接口的功能定义要具备单一性,9.日志打印好1.接口参数校验 入参是否允许为空,入参长度是否符合你的预期长度。 比如你的数据库表字段设置为varchar(16),对方传了一个32位的字符串过来,如果你不校验参数,插入数据库直接异常了。 出参也是,比如你定义的接口报文,参数是不为空的,但是你的接
-
设计模式与原则
主要内容:1.GRASP:通用职责分配软件模式(共9种),2.SOLID:设计原则(共5种),3.GOF:设计模式(共23种),4.其他必要设计原则GRASP: 通用职责分配软件模式(共9种) SOLID:设计原则(共5种) GOF:设计模式(共23种) 其他必要设计原则 1.GRASP:通用职责分配软件模式(共9种) 告诉我们怎样设计问题空间中的类与分配它们的行为职责,以及明确类之间的相互关系等 Infomation Expert(信息专家) Creator(创造者) Low coupling
-
 设计原则-LOD原则
设计原则-LOD原则主要内容:1.迪米特法则,2.高内聚,3.松耦合,4.代码,5.总结1.迪米特法则 迪米特法则的英文翻译是:Law of Demeter,缩写是 LOD。 单从这个名字上来看,我们完全猜不出这个原则讲的是什么。不过,它还有另外一个更加达意的名字,叫作最小知识原则,英文翻译为:The Least Knowledge Principle。 它不像 SOLID、KISS、DRY 原则那样,人尽皆知,但它却非常实用。利用这个原则,能够帮我们实现代码的“高内聚、松耦合” “
-
设计原则-KISS原则
主要内容:1.Kiss原则,2.Kiss原则意义,3.Kiss原则落地1.Kiss原则 Keep It Simple and Stupid Keep It Short and Simple Keep It Simple and Straightforward. 2.Kiss原则意义 KISS 原则算是一个万金油类型的设计原则,可以应用在很多场景中。它不仅经常用来指导软件开发,还经常用来指导更加广泛的系统设计、产品设计等,比如,冰箱、建筑、iPhone 手机的设计等等
-
设计原则-DRY 原则
主要内容:1.DRY 原则,2.实现逻辑重复,3.功能语义重复,4.代码执行重复,5.注释重复,6.数据重复,7.提高代码复用性1.DRY 原则 它的英文描述为:Don’t Repeat Yourself。中文直译为:不要重复自己。将它应用在编程中,可以理解为:不要写重复的代码。 很多人对这条原则存在的误解。实际上,重复的代码不一定违反 DRY 原则,而且。 DRY不是只代码重复,而是“知识”的重复,意思是指业务逻辑。例如由于沟通不足,两个程序员用两种不同的方法实现同样功能的校验。 2.实现逻辑
-
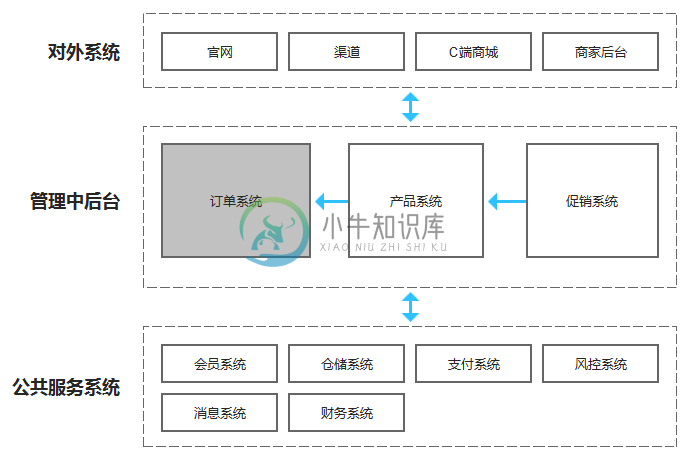 订单系统的设计
订单系统的设计主要内容:1.订单系统在企业中的角色,2.订单系统与各业务系统的关系,3.订单系统上下游关系,4.订单系统的业务架构1.订单系统在企业中的角色 在搭建企业订单系统之前,需要先梳理企业整体业务系统之间的关系和订单系统上下游关系,只有划分清业务系统边界,才能确定订单系统的职责与功能,进而保证各系统之间高效简洁的工作。 2.订单系统与各业务系统的关系 2.1 对外系统 所有给企业外部用户使用的系统都在这一层,包括官网、普通用户使用的C端,还包括给商户使用的商家后台和在各个销售渠道进行分销的系统,比如与
-
 Kafka高性能设计-3
Kafka高性能设计-3主要内容:1.消费消息的性能优化手段,2.消费者组1.消费消息的性能优化手段 1.1 稀疏索引 Kafka 利用offset 和 timestamp 查到消息。 B Tree 类的索引并不适用于 Kafka。哈希索引看起来却非常合适。 为了加快读操作,如果只需要在内存中维护一个「从 offset 到日志文件偏移量」的映射关系即可,每次根据 offset 查找消息时,从哈希表中得到偏移量,再去读文件即可。(根据 timestamp 查消息也可以采用
-
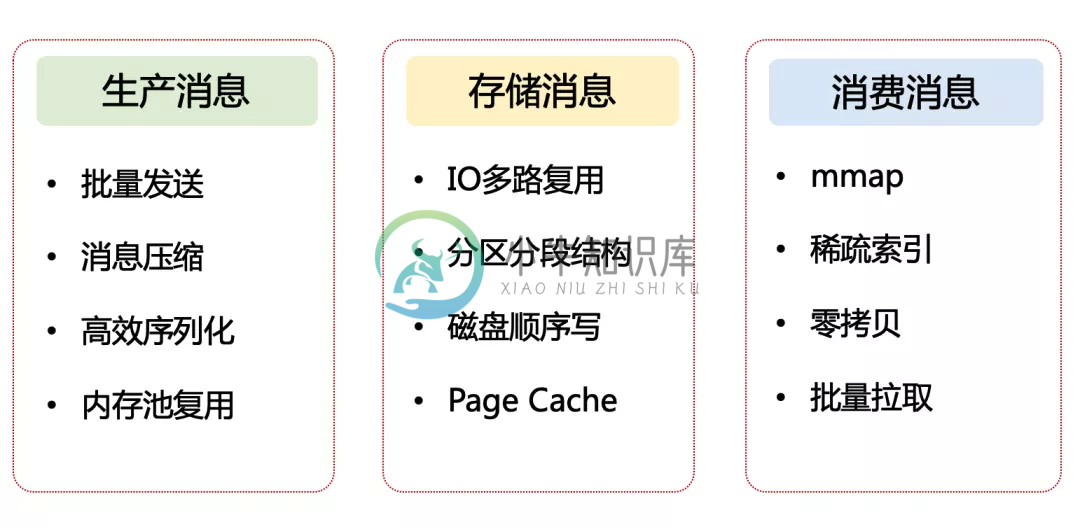 Kafka高性能设计-2
Kafka高性能设计-2主要内容:1. 存储消息的性能优化手段1. 存储消息的性能优化手段 存储消息属于 Broker 端的核心功能 IO多路复用, 磁盘顺序写, page缓存, 分区分段结构 1.1 IO 多路复用 对于 Kafka Broker 来说,要做到高性能,首先要考虑的是:设计出一个高效的网络通信模型,用来处理它和 Producer 以及 Consumer 之间的消息传递问题。 SocketServer : Kafka采用的是Reactor 网络
-
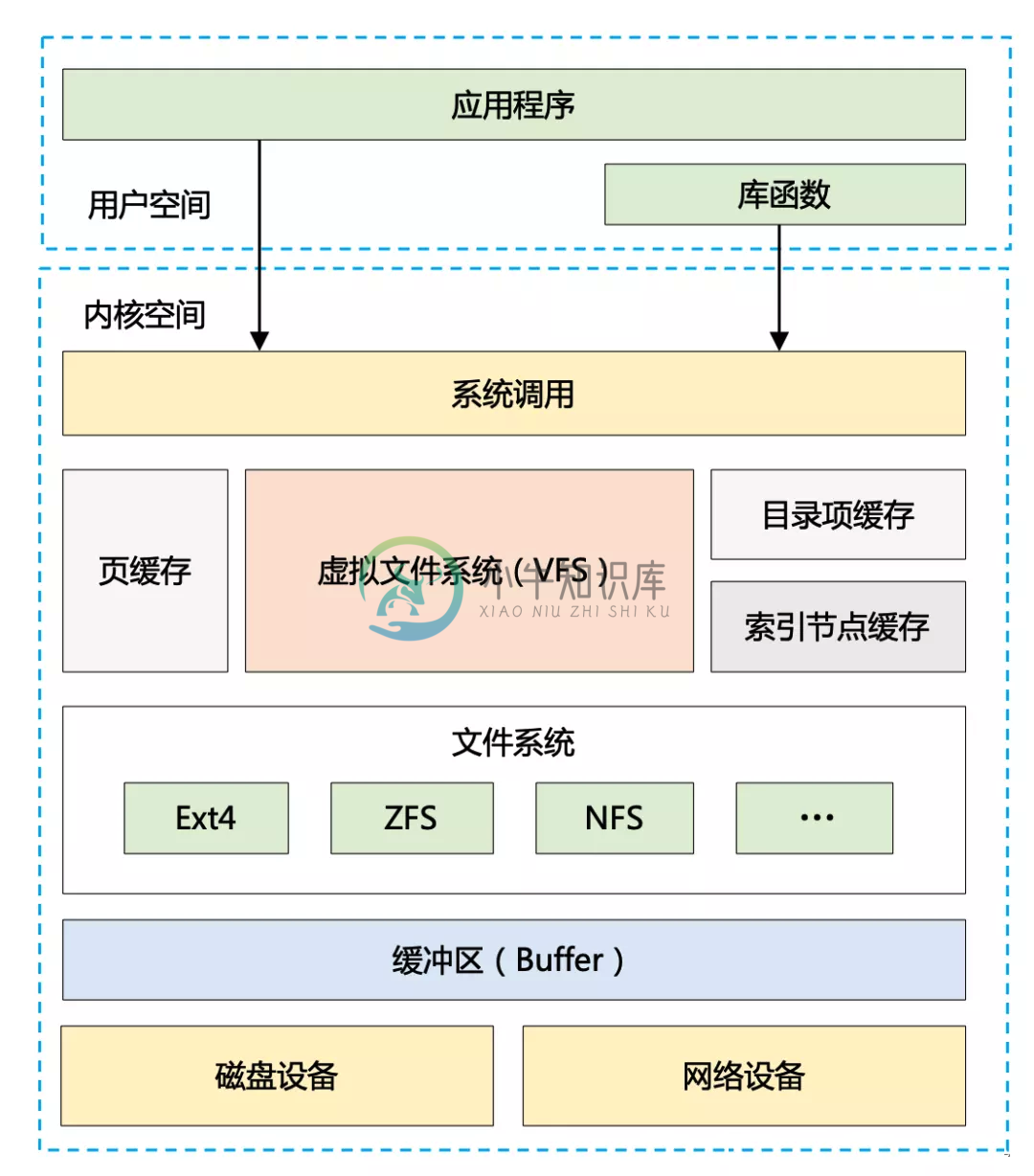 Kafka高性能设计-1
Kafka高性能设计-1主要内容:1. 如何理解高性能设计,2. Kafka 高性能设计的全景图,3. 生产消息的性能优化手段,4.Kafka源码分析Kafka 的高性能设计可以说是全方位的,从 Prodcuer 、到 Broker、再到 Consumer, 1. 如何理解高性能设计 对于线程池、多级缓存、IO 多路复用、零拷贝等技术是一个系统性的问题,至少需要深入到操作系统层面。从 CPU 和存储入手,去了解底层的实现机制,然后再自底往上,一层一层去解密和贯穿起来。 高性能设计离不开的就是计算和IO 计算: 1、让更
-
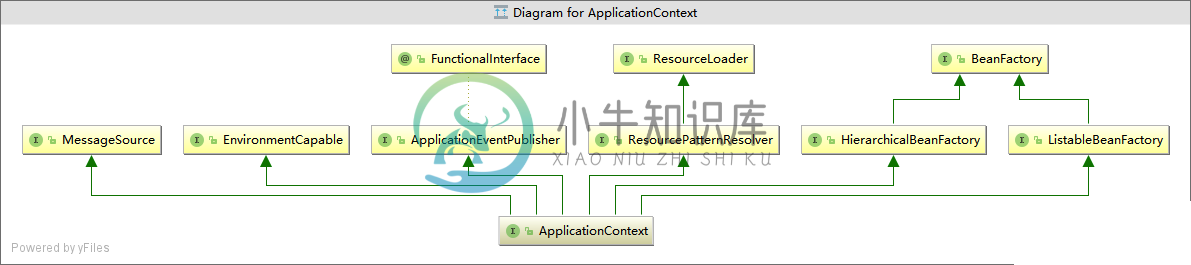 Spring Ioc 容器的设计
Spring Ioc 容器的设计主要内容:1.Spring IOC容器的设计,2.BeanFactory和ApplicationContext的区别,3.BeanFactory容器的设计原理,4.BeanFactory的详细介绍,5.ApplicationContext容器的设计原理,6.ApplicationContext的详细介绍,7.ApplicationContext容器扩展功能详解介绍1.Spring IOC容器的设计 实现BeanFactory接口的简单容器 实现ApplicationContext接口的高级容器
-
Yearning 权限设计(重要)
理念 Yearning自2.1.7版本之后采用权限组的方式进行权限授权,权限最低下放至数据源。 Yearning中用户先以角色的形式分为三大类,分别为 提交人/操作人/超级管理员。其中超级管理员角色为可见管理页面角色, 提交人/操作人为非可见管理页面角色。通过角色Yearning在细粒度权限划分之前先将用户分类。使管理类权限不会出现在使用者细粒度权限划分中 可根据每个用户的实际需求配置相应ddl/
-
图表设计及样式
在 Highcharts 中,所有的布局及样式均可通过配置来自定义。 一、布局及位置 Highcharts 图表中大部分元素都可以通过 x 和 y 参数设置偏移量来改变其位置,偏移是相对其水平对齐和竖直对齐方式的;水平对齐可用的值有 “left”、“right” 和 “center”,默认是 “left”;竖直对齐可用在值有 “top”、“bottom” 和 “middle”。 1、图表布局 Hi
-
《Apache Spark 设计与实现》
本文主要讨论 Apache Spark 的设计与实现,重点关注其设计思想、运行原理、实现架构及性能调优,附带讨论与 Hadoop MapReduce 在设计与实现上的区别。不喜欢将该文档称之为“源码分析”,因为本文的主要目的不是去解读实现代码,而是尽量有逻辑地,从设计与实现原理的角度,来理解 job 从产生到执行完成的整个过程,进而去理解整个系统。 讨论系统的设计与实现有很多方法,本文选择 问题驱