《长鑫存储》专题
-
“指定的密钥太长;最大密钥长度为1000字节”
问题内容: 我无法在上创建索引。 MySQL: 问题答案:
-
jQuery在较小的列表中拆分了长长的ul列表
问题内容: 我的UL清单很长,我需要分解成较小的清单,每个清单包含约20个项目。 我以为我可以使用类似 但事实并非如此。知道如何以最少的CPU使用jQuery吗? 问题答案: 我将使用删除的s 创建文档片段,然后将其重新添加到所需的位置。在这种情况下,我将它们重新附加到主体上:
-
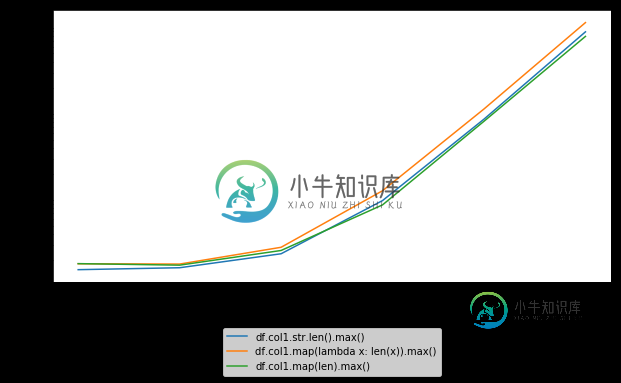 在Pandas数据框列中找到最长字符串的长度
在Pandas数据框列中找到最长字符串的长度问题内容: 有没有比下面的示例更快的方法来找到Pandas DataFrame中最长字符串的长度? 使用IPython的进行计时大约需要10秒钟。 问题答案: DSM的建议似乎是您无需进行一些手动微优化就能获得的最佳效果: 请注意,显式使用该方法似乎并没有多大改进。如果您不熟悉IPython(这是非常方便的语法所来自的地方),我绝对建议您尝试一下,以快速测试此类内容。 更新 添加了屏幕截图:
-
 对于长度为100000的类型字符变化(255),值太长
对于长度为100000的类型字符变化(255),值太长我使用的是Spring Data JPA,我的列定义是 在有效负载中,我使用了具有字符计数的描述。但它仍然在扔 错误:值太长,无法更改类型字符(255)` 仅使用长度为1990的文本,即使对于文本类型也会出现相同的错误
-
为什么flex项宽度随flex增长而增长:0[重复]
我遇到的最后一个问题与这里的链接相同:flexbox项目的宽度被忽略 一切看起来都很好,但在最后一刻,我想更改flex容器的方向,所以我添加了
-
 当文本内容太长时,停止flex子级增长[重复]
当文本内容太长时,停止flex子级增长[重复]我有一个灵活的布局,看起来像这样: 这很好,但是当产品描述很长时,我想隐藏溢出并显示省略号。 有一个类为的flex容器,它有两个flex子容器-(30%)和(70%)。右侧的
-
ValueError:值的长度与索引的长度不匹配 熊猫DataFrame.unique()
问题内容: 我正在尝试获取新的数据集,或将当前数据集列的值更改为其唯一值。这是我尝试获得的示例: 我不太在乎索引,但这似乎是问题所在。到目前为止,我的代码非常简单,我尝试了两种方法,一种是使用新的dataFrame,另一种是不使用。 两次都出现错误“值的长度与索引的长度不匹配”。 问题答案: 当您尝试向数据帧分配不同长度的numpy数组列表时,会出现此错误,并且可以按以下方式重现该错误: 四行数据
-
具有所有相同元素的最长子数组的长度
我有这个问题: 您将获得一个整数 A 和一个整数 k 的数组。您可以将 A 的元素递减到 k 次,目标是生成一个元素都相等的连续子数组。返回可以用这种方式生成的最长的连续子数组的长度。 例如,如果 A 是 [1,7,3,4,6,5] 并且 k 是 6,那么您可以生成 [1,7,3,4-1,6-1-1-1,5-1-1] = [1,7,3,3,3,3],因此您将返回 4。 最佳解决方案是什么?
-
将最长公共子序列降为最长递增子序列
在最多一个序列存在重复的情况下,可以将最长公共子序列问题转化为最长递增子序列问题。减少问题的过程说明在这里: 假设您有以下序列: 然后,创建一个整数序列S3,其中您必须将S2的每个元素的位置放在S1中(如果元素在S1中不存在,那么忽略那个元素)。在本例中: 这种方法是如何工作的?为什么这种约简解决了寻找最长公共子序列的问题?
-
 pdd用户增长交互设计岗面试 一面长达1.5h
pdd用户增长交互设计岗面试 一面长达1.5h整个招聘的流程是这样的:在官网投递了简历 如果简历筛选经过的话,就会有设计师和你通个大概10-15分钟的电话讲解一下pdd的上班时间为11-11和单休(真的有人能接受嘛!!)然后就讲解一下岗位负责的项目内容 一面1.5h的设计师专业面 二面 团队leader老板面关于团队的内容 hr面 新鲜出炉一面的一些问题 希望以后可以派上用场! 整个面试时常为1.5小时左右 ·面试问题· Q1: 自我介绍 Q
-
 2024华为OD机试 - 最长子字符串的长度(一)JAVA
2024华为OD机试 - 最长子字符串的长度(一)JAVA2024华为OD机试真题,代码包含语言java代码基本都有详细注释。 题目描述 给你一个字符串 s,首尾相连成一个环形,请你在环中找出 'o' 字符出现了偶数次最长子字符串的长度。 输入描述 输入是一个小写字母组成的字符串 输出描述 输出是一个整数 备注 1 ≤ s.length ≤ 500000 s 只包含小写英文字母 用例 输入 alolobo 输出 6 描述 最长子字符串之一是 "alolo
-
现在不赞成使用getDownloadUrl()来使Firebase Storage“获取长期存在的下载URL”
问题内容: 更新至后,此方法显示已弃用 ‘com.google.firebase:firebase-storage:15.0.2’ 官方网站上没有其他方法可以实现url,那么有什么方法可以以不推荐的方式实现Url? 问题答案: 在文档中它说: 该类的和方法现已弃用。使用from 代替。 因此,您需要在 异步检索具有可撤销令牌的长期下载URL。可以用于与他人共享文件,但是如果需要,开发人员可以在Fi
-
在Python中检查较长字符串中存在的模糊/近似子字符串?
问题内容: 使用像leveinstein(leveinstein或difflib)之类的算法,很容易找到近似匹配。 可以通过根据需要确定阈值来检测模糊匹配。 当前要求:基于较大字符串中的阈值来查找模糊子字符串。 例如。 一种蛮力解决方案是生成长度为N-1到N + 1(或其他匹配长度)的所有子串,其中N是query_string的长度,并在它们上逐个使用levenstein并查看阈值。 在pytho
-
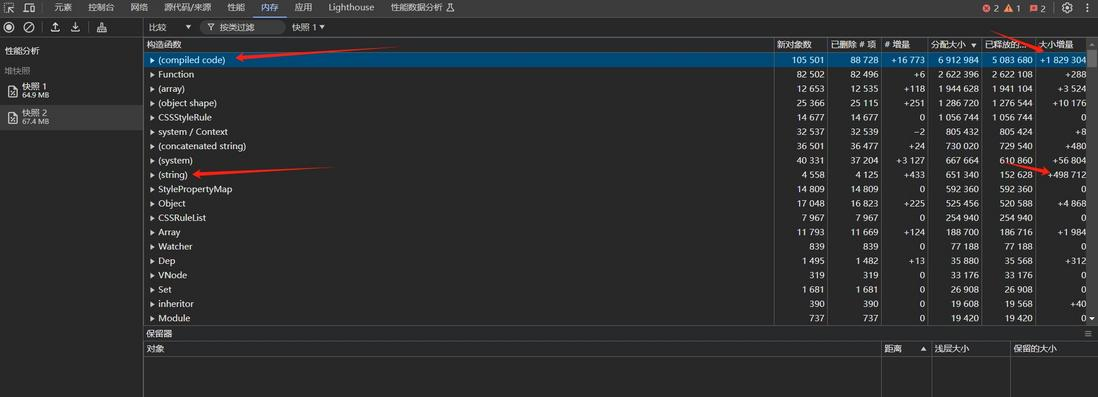 javascript - 如何优化 Vue 应用以防止刷新页面时内存不断增长?
javascript - 如何优化 Vue 应用以防止刷新页面时内存不断增长?vue刷新页面内存会增长,内存泄漏问题 问题1.每次刷新页面会造成内存泄漏,不做任何操作光刷新也会有内存增长,如果做了一些操作再刷新可能会长得比较厉害。通过使用浏览器开发者排查,发现会增长很多字符串(string)和编译代码(compiled code)还有一些游离节点吧。 问题2. 为什么我用到的字符串显示的路径是依赖包里面的路径啊?比如下图: 已经把定时器和组件销毁了,监听了一个刷新事件,每次
-
XSSFWorkbook加载时间很长
问题内容: 我正在使用以下代码: xlsx文件本身具有25,000行,每行包含500列的内容。在调试过程中,我看到创建XSSFWorkbook的第三行需要很长时间(1小时!)来完成此语句。 有没有更好的方法来访问原始xlsx文件的值? 问题答案: 首先,当您有文件时,不要从InputStream加载XSSFWorkbook!使用InputStream需要将所有内容缓冲到内存中,这会占用空间并占用时