《一汽解放》专题
-
WebClient第一次请求缓慢的解决方法
我在Spring Boot MVC 2.1项目中使用WebClient,发现客户端发出的第一个请求需要6秒。后续请求的速度要快得多(~30ms)。 在Spring的JIRA中有一个封闭的问题,建议使用Jetty作为WebClient Http连接器。我已经尝试了这种方法,改进了数字,第一个请求约为800ms。这次是一个改进,但它仍然远离RestTemplate,它通常采取 Netty 方法(5 秒
-
从mvn依赖中排除一些依赖:解决
在我的
-
Jison解析器在第一条规则后停止
我有一个简单的文件格式,我想用jison解析器生成器解析。这个文件可以由任意顺序和数量的多个表达式组成。这是解析器的jison文件: 为了简单起见,我将文件缩短为只有字符串和文件id表达式。 我的问题是,如果第二个表达式只包含一个类似令牌的字符串,那么生成的解析器似乎只能识别一个或两个完整的表达式。例如: 文件版本: 1.0 将被解析,或者 文件版本:1.0“我的字符串” 也将被解析,但对于 文件
-
如何在ANTLR中解析一个部分日期?
我正在进行使用antlr4的第一步,并尝试以欧洲格式解析部分日期。 我想要识别像或这样的正常日期,但也要识别像或这样的只包含月份和年份的日期,以及像或这样的只包含年份的日期。在我的应用程序中,我希望能够访问日期(日、月和年)的所有部分,其中一些部分可能是空的/空的。 这是我到目前为止的语法。 该语法适用于单个年份(),但无法识别月份-年份组合()。告诉我以下内容。 因此,根据我的一点经验,我认为解
-
Spring 3.2中关于@MatrixVariable注解的一些信息
今天,我正在研究可从STS仪表板下载的Spring MVC展示 我对Spring 3.2版本引入的新注释@MatrixVariable以及URI路径中Matrix变量的使用有些怀疑。 在我的家中.jsp视图我有以下链接: 此处阅读有关@MatrixVariable注释的官方文档:http://static.springsource.org/spring-framework/docs/3.2.0.M
-
用 scikit-learn 求解一元线性回归问题
一元线性回归 y=f(x)叫做一元函数,回归的意思就是根据已知数据复原某些值,线性回归(regression)就是用线性的模型做回归复原。 那么一元线性回归就是:已知一批(x,y)值来复原另外未知的值。 比如:告诉你(1,1),(2,2),(3,3),那么问你(4,?)是多少,很容易复原出来(4,4),这就是一元线性回归问题的求解 当然实际给你的数据可能不是严格线性,但依然让我们用一元线性回归来计
-
解决问题——编写一个Python脚本 / 概括
我们已经学习如何创建我们自己的Python程序/脚本,以及在编写这个程序中所设计到的不同的状态。你可以发现它们在创建你自己的程序的时候会十分有用,让你对Python以及解决问题都变得更加得心应手。 接下来,我们将讨论面向对象的编程。
-
解决问题——编写一个Python脚本 / 问题
目录表 问题 解决方案 版本一 版本二 版本三 版本四 进一步优化 软件开发过程 概括 我们已经研究了Python语言的众多内容,现在我们将来学习一下怎么把这些内容结合起来。我们将设计编写一个能够 做 一些确实有用的事情的程序。 问题 我提出的问题是: 我想要一个可以为我的所有重要文件创建备份的程序。 尽管这是一个简单的问题,但是问题本身并没有给我们足够的信息来解决它。进一步的分析是必需的。例如,
-
 浙江大华解决方案工程师一面
浙江大华解决方案工程师一面三个人面的,我最后反问说认为有什么可以改进的,面试官反问我说之前的面试给你什么建议呢我就说了点,她说我们也是这么感觉得😅
-
 中国电信解决方案工程师一面
中国电信解决方案工程师一面双非本,坐标地级市分公司,总共感觉十分钟不到 1.自我介绍 2.说说实习干了啥 3.看项目上写的有商业计划书,说说怎么进行商业模型分析的 4.担任学生干部,说说主要都做了什么 结束,没有反问环节 面试间不隔音,一面前里面面试官大声密谋听的清清楚楚🤣多少人过笔试,多少人筛过简历,要录取多少个,我前一个好像是研究生,张嘴就是SCI,拿研究成果跟清华那个比怎么怎么好,听得我一愣一愣的,想走了都
-
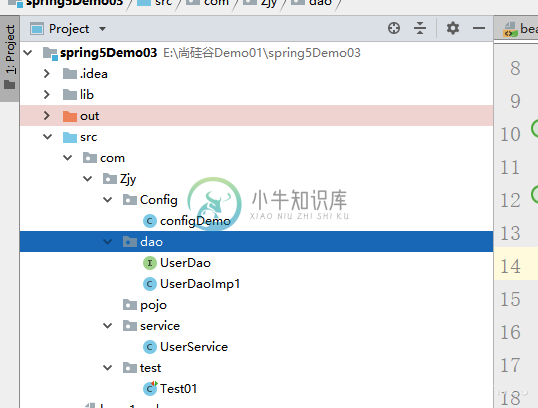 Spring-第一个简单程序基于纯注解
Spring-第一个简单程序基于纯注解文件结构: 这里是进行了外部注入 这里是configDemo.java代替了bean.xml中的扫描 如果是外部注入的话则需要加上注解 @AutoWired:根据属性类型自动装配 @Qualifier:根据属性名称自动注入 @Resource:都可以 @Value:注入普通类型属性 这里的注解注入方式为 @Component:普通主键 @Service:业务 @Controller:控制 @Rep
-
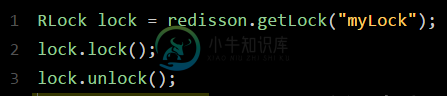 一文带你了解分布式锁的原理
一文带你了解分布式锁的原理主要内容:一、写在前面,二、Redisson实现Redis分布式锁的底层原理一、写在前面 现在面试,一般都会聊聊分布式系统这块的东西。通常面试官都会从服务框架(Spring Cloud、Dubbo)聊起,一路聊到分布式事务、分布式锁、ZooKeeper等知识。 所以咱们这篇文章就来聊聊分布式锁这块知识,具体的来看看Redis分布式锁的实现原理。 说实话,如果在公司里落地生产环境用分布式锁的时候,一定是会用开源类库的,比如Redis分布式锁,一般就是用Redisson框架就
-
 求一种数据引入的解决方案(vue3)?
求一种数据引入的解决方案(vue3)?要求是这样的:在公共的 TS 文件中定义一个接口获取列表数据的方法,并且封装一个函数返回上个方法中返回的列表数据并导出, 在组件中通过 import 直接引入这个数据来展示,同时在不同组件中引入这个数据的请求都要重新发起。类似下面 实际的 useList 实现如下 但是我有下面一些问题: 我在 useList 中使用 computed 来返回数据,但是有缓存,在不同组件中引入的时候会有缓存。 如果
-
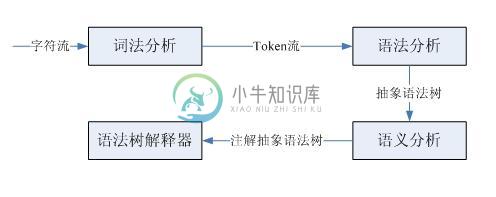 使用Python编写一个最基础的代码解释器的要点解析
使用Python编写一个最基础的代码解释器的要点解析本文向大家介绍使用Python编写一个最基础的代码解释器的要点解析,包括了使用Python编写一个最基础的代码解释器的要点解析的使用技巧和注意事项,需要的朋友参考一下 一直以来都对编译器和解析器有着很大的兴趣,也很清楚一个编译器的概念和整体的框架,但是对于细节部分却不是很了解。我们编写的程序源代码实际上就是一串字符序列,编译器或者解释器可以直接理解并执行这个字符序列,这看起来实在是太奇妙了。本文会
-
我需要解释一下如何使用printf命令来解决这个问题
输入格式 每一行输入都将包含一个字符串,后跟一个整数。每个字符串将有最多的字母字符,每个整数将在从到的包含范围内。 输出格式 在每行输出中,应该有两列:第一列包含字符串,并使用完全字符左对齐。第二列包含整数,以数字表示;如果原始输入少于三位数,则必须用零填充输出的前导数字。 样本输入 样本输出 我试过使用制表符空间。但我不能把这个对齐。 我的输出 预期产出