《农业银行》专题
-
Spring@事务性和长期运行的业务逻辑
-
如何选择要在哪个GPU上运行作业?
然后再次运行,但它也转到GPU0。 我看了相关的问题,如何选择指定的GPU来运行CUDA程序?但是命令不在CUDA 8.0 bin目录中。除了之外,我还看到其他文章引用了环境变量但这些都没有设置,我也没有找到关于如何使用它的信息。 虽然与我的问题没有直接关系,但使用我能够使应用程序在GPU1上运行,但使用不能在GPU0和1上运行。 我正在一个使用bash shell运行的系统上测试这一点,该系统在
-
记录在cron作业中运行的curl的返回
我有一个页面“test.PHP”,它运行一个PHP脚本并返回datetime/some结果...这个页面我在cron作业中调用,它运行成功,但我想将返回的结果记录在一个文件中 我试过了...cron_log.log是空的
-
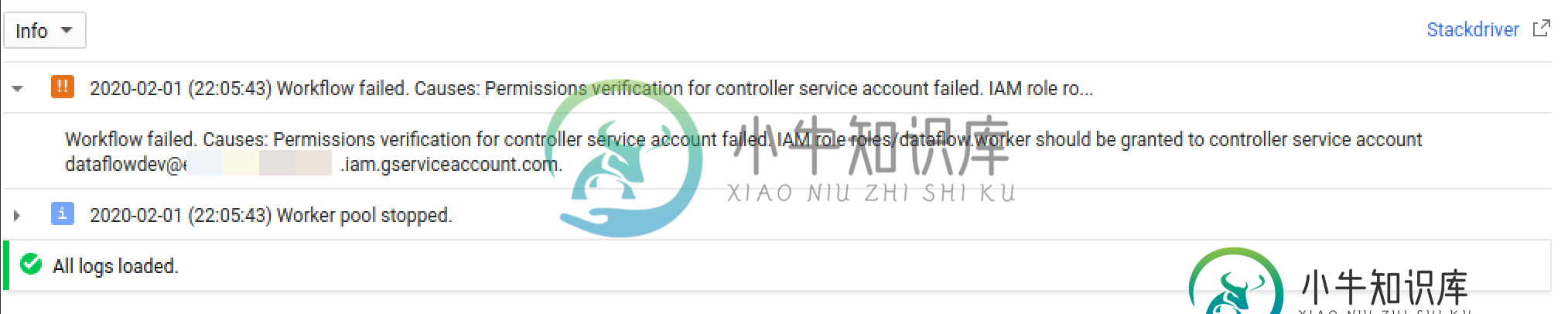 服务帐户执行批处理数据流作业
服务帐户执行批处理数据流作业我需要使用服务帐户执行数据流作业,下面是同一平台中提供的一个非常简单和基本的wordcount示例。 根据这一点,GCP要求服务号具有数据流工作者的权限,以便执行我的作业。即使我已经设置了所需的权限,错误仍然出现时,堰部分会出现: 有人能解释这种奇怪的行为吗?太感谢了
-
业务规则在jbpm流程上只执行一次
-
如何在spring batch中同时运行两个作业
我正在尝试使用Spring Batch和Spring Task Scheduler运行两个作业,而不考虑它们的调度时间。这两个作业(Tasklet)在不同的时间间隔执行不同的作业。 以下是springConfig。xml文件: 以下是CouPonTougleActivationScheduler和OTPJobScheduler的实现: @enableSched调度公有类CouPonTougleAc
-
 阿里巴巴 行业运营 实习一面面经
阿里巴巴 行业运营 实习一面面经面试内容 简历细挖:针对各项经历提问,主要为以下方向 过往实习的工作内容、过往项目的主要工作 实习的收获 团队合作中负责哪部分工作 项目的具体idea从哪里来,为什么提这样的方案 对一些具体概念的理解 行为面:问题偏personal,部分类似宝洁八大问 觉得之前的商赛最满意哪一段?为什么? 讲一件坚持很久的事 有没有被建议/批评的经历 为什么投递这个岗位 关于个性特点、工作内容偏好的提问 反问&业
-
 阿里巴巴 行业运营 实习二面面经
阿里巴巴 行业运营 实习二面面经没有遇到业务场景题,更多的还是针对过往实习/项目经历的提问,不同部门面试风格差异蛮大的。 1. 你在过往的项目经历里有哪些可以体现快速学习能力的? 2. 在这段商赛遇到的困难有哪些? 3. 觉得印象最深的一段实习是什么?有哪些收获? 4. 在这段实习中遇到的困难是什么? 5. 这段实习中团队管理遇到的困难有哪些? 6. 还有其他的吗? 7. 几段实习最满意的是哪一段?最不满意的是哪一段?为什么?
-
 阿里淘天行业运营面试问题分享
阿里淘天行业运营面试问题分享1、自我介绍 2、详细介绍某段实习内容:包括具体工作内容和数据结果。 追问:运营前后的数据表现如何?你认为达到这种效果最有效的策略是什么? 追问:你在其中最大的收获是什么? 追问:你在团队中扮演什么角色? 3、详细介绍另一段相关实习:包括具体工作内容和数据结果。 追问:你认为新品品牌成长到有销量过程中最重要的是什么?为什么? 追问:怎么将新品运营成为优质品?(从产品侧、运营侧、价格侧、营销侧、购买
-
 20230307招商银行广州分行信息技术岗(校招)一面凉经
20230307招商银行广州分行信息技术岗(校招)一面凉经啊...想来想去还是决定写一写,作为给想去银行试试的uu们的参考叭~ 面试形式:群面(12人一组) 上指定楼层签到、领取姓名卡,等待(会有工作人员带上去哦~还有水和零食嘿嘿) 叫到名字的自成一组(12人),到指定面试间准备面试 有三位面试官,按座位随机再把12人分为两组(每组6人),一组正方一组反方 自行控制时间按以下流程展开辩论(论题:银行中智能机器人的出现是利大于弊/弊大于利): 5分钟阅读材
-
 招商银行2023校园招聘提前批专场笔试笔经(9-24)
招商银行2023校园招聘提前批专场笔试笔经(9-24)招商银行我投的是总行信息技术岗和信用卡中心,发的笔试不知道是哪个的,在官网上看状态两个岗位都是简历筛选中。。。 24号下午2点开始,持续125分钟,下面笔经是凭记忆写的,可能会有点小错。 (1)英语 30分钟 20道单选题 3篇阅读理解,每篇5个单选 (2)行测 55分钟 1分钟1题的速度才能做完,根本做不完。。。 言语理解 20道 数字推理 10道 逻辑推理 15道 思维策略 10道 (3
-
 浦发银行杭州分行-信息科技岗(一面终面二合一)
浦发银行杭州分行-信息科技岗(一面终面二合一)通知说18:00,但是提前了,16点半给我打电话说面试可以开始了,所以要提前准备好。候场等5个人齐了一起开始的。大概等了15分钟。 5个人一组,三个面试官,两女一男,有个女面试官好像全程负责cue流程,话筒声有点杂 1.一分钟自我介绍 然后从后往前顺序针对每个人提两个左右的问题 2.用了哪些语言和技术,然后延申了一下技术栈、版本这类问题 3.实习经历 4.接不接受转岗,产品经理
-
JS代码随机生成姓名、手机号、身份证号、银行卡号
本文向大家介绍JS代码随机生成姓名、手机号、身份证号、银行卡号,包括了JS代码随机生成姓名、手机号、身份证号、银行卡号的使用技巧和注意事项,需要的朋友参考一下 开发测试的时候,经常需要填写姓名、手机号、身份证号、银行卡号,既要符合格式要求、又不能重复。大家会到网上搜各种生成器。 下面小编自己写的一个js生成器代码。随机生成姓名、手机号、身份证号、银行卡号的js代码。 // 生成随机姓名 //生成随
-
将电子商务支付发送到信用卡,而不是银行账户
我想知道电子商务供应商是否有可能通过信用卡而不是银行账户收到付款。通常在电子商务交易中,会发生以下情况: 设置: 供应商建立电子商务网站 供应商使用Paypal等服务开立支付网关账户,还可以设置银行商户账户 供应商将其网站连接到支付网关(API等) 供应商通过提供账号等将支付网关连接到其银行账户 购买 客户进行购买并提供信用卡详细信息以从 网站将此信息传递给支付网关 支付网关授权客户卡支付 如果授
-
用java阅读excel表。那个excel表也包含一些银行单元格
这是我的excel表,其中包含一些空白单元格之间。所以我不能正确地阅读这张纸。所以,当读行时,当它在中间找到一个空白单元格时,列计数就会减少。