《农业银行》专题
-
 腾讯CSIG 云与智慧产业事业群产品运营 一二面面经
腾讯CSIG 云与智慧产业事业群产品运营 一二面面经一面 1.自我介绍 2.校园经历 3.建立深挖,不放过任何一个细节 1.你认为做产品运营需要具备的能力 5.情景假设/产品说方案出现问题,产品说要延期,不能及时上架,你应该怎么办? 6.实习过程中除了简历上写的还做了什么有价值的工作? 7.之前的工作和产品运营最相关的内容是什么? 8.之前的工作中跟数据相关的工作有什么? 9.工作中遇到的最大困难? 二面 1.自我介绍 2.介绍相关实习经历的主要工
-
 腾讯CSIG 云与智慧产业事业群产品运营 三四面面经
腾讯CSIG 云与智慧产业事业群产品运营 三四面面经三面 1.自我介绍 2.相关实习的主要工作任务? 3.有什么收获和启发? 4.如何理解产品运营的工作? 5.用户运营的职责和意义? 6.对于未来的规划? 7.认为自己做的比较好的运营案例? 8.对产品的了解如何?认为有什么比较好的地方和不足? 9.反问环节 -部门组织架构,入职后负责的方向? -实习生的培养计划? -面试的反馈? HR面 1.自我介绍 2.介绍以往的实习经历 3.对于产品经理的理解
-
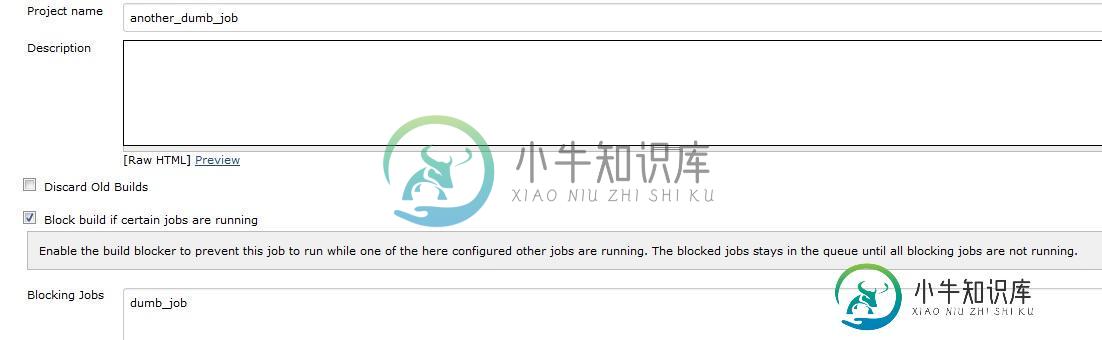 如果具有给定标签的给定节点正在/正在运行另一个作业,则阻止作业运行
如果具有给定标签的给定节点正在/正在运行另一个作业,则阻止作业运行在Jenkins中,如果作业B正在运行,我们可以使用Build blocker插件阻止作业a。 类似地或以某种方式,我希望一个作业,例如:another_dumb_job不运行/(等待并让它在队列中),如果有任何正在进行的作业在任何用户选择的从属上运行,直到这些从属再次空闲。 对于EX:我不想运行一个作业(这将删除一堆从机,无论是脱机还是联机--使用下游作业或通过调用一些Groovy/Script
-
在不使用JobConf的情况下运行Hadoop作业
问题内容: 我找不到一个提交不使用不推荐使用的类的Hadoop作业的示例。 尚未弃用的,仍然仅支持带有参数的方法。 有人可以给我指出一个Java代码示例,该示例仅使用类(而不是)提交Hadoop map / reduce作业,而不是使用包吗? 问题答案: 希望对您有所帮助
-
如何检查Quartz Cron作业是否正在运行?
问题内容: 如何检查计划的Quartz Cron作业是否正在运行?是否有任何API可以进行检查? 问题答案: scheduler.getCurrentlyExecutingJobs()在大多数情况下应该可以工作。但是请记住不要在Job类中使用它,因为它使用ExecutingJobsManager(a JobListener)将正在运行的作业放到HashMap中,该HashMap在作业类之前运行,因
-
无法使用Cassandra驱动程序运行Spark作业
Build.Gradle 分级。性质 例外情况: 代码: 有人知道怎么修吗?
-
跨多个实例只运行一次调度作业
我有一个,每个月底运行一次。运行后,它会将一些数据保存到数据库中。 当我扩展应用程序时(例如有2个实例),两个实例都运行计划作业,并且都保存数据,在一天结束时,我的数据库有相同的数据。 所以我希望计划作业只运行一次,而不管云上的实例数量如何。
-
php - laravel中如何区分不同端进行业务?
做的项目有PC端和H5端之分 有的接口和PC端是共用一个的,但是会根据不同端显示的数据小有不同 如何来精确区分PC端还是H5端来进行业务
-
如何在Linux系统上每天运行Cron作业
本文向大家介绍如何在Linux系统上每天运行Cron作业,包括了如何在Linux系统上每天运行Cron作业的使用技巧和注意事项,需要的朋友参考一下 本文将教您如何安排玉米作业,以便每天在特定时间执行脚本,命令或Shell脚本。作为系统管理员,我们知道在后台自动运行例行维护作业的重要性。Linux corn实用程序将帮助我们维护这些作业以在后台运行。 Cron作业的一般语法 要查看机器上存在的cro
-
SQL Agent作业:确定已运行了多长时间
问题内容: 场景 某些SQL Agent Jobs计划在一天中每隔几分钟运行一次。 在某些情况下,它会丢失其下一个计划,因为它仍在按上一个计划运行。 每隔一段时间,一项工作可能会“挂起”。这不会产生故障(因为作业尚未停止)。发生这种情况时,可以手动停止该作业,并在下次运行时正常运行。它旨在从停下来的地方重新取回。 最有效的方法是什么? 我想要一种确定名为“ JobX”的SQL代理作业当前正在运行多
-
Spring批处理:重新运行作业后重复行
我们的Spring Batch应用程序在重新启动失败的作业时,再次处理相同的记录,导致重复的行,我们希望了解如何避免这种情况。 启动批处理作业的Spring集成轮询器配置为每两个小时运行一次。第二次运行时,作业参数将相同,但如果上一次运行失败(例如,由于数据截断异常),Spring Batch不会抱怨作业已完成。 在故障点,几十万条记录已经被处理并从源表复制到目标表。在以后运行作业时,相同的行将复
-
运行Spark流作业时出现序列化问题
无法解决以下由)触发的序列化问题。我认为可以解决序列化问题,但事实并非如此。那么,如何使用? 我假设变量和是不可序列化的,但是我如何正确地序列化它们,以便代码能够在集群上工作,而不仅仅是在本地工作呢? 上面显示的代码抛出错误:
-
使用mockito初始化spring批处理作业执行
问题: 我正在为我的一个spring批处理作业方法编写单元测试。我使用mockito来模拟我的批处理作业依赖关系。在jobExecution发挥作用之前,一切都很好。我要测试的方法调用了jobExecution变量,但它给了我NPE(NullPointerException)并且我没有成功地用mockito模拟它。 删除此currentJobExecution时 从我要测试的方法,然后测试成功完成
-
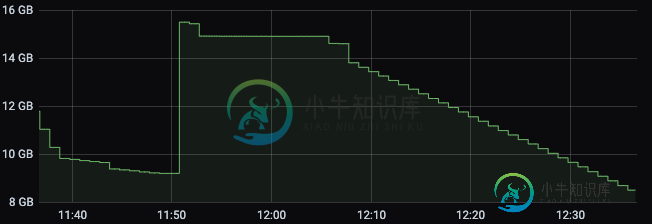 运行Apache Flink作业时K8s群集内存减少
运行Apache Flink作业时K8s群集内存减少我们正在尝试在K8s集群上部署apache Flink作业,但我们注意到一个奇怪的行为,当我们开始我们的作业时,任务管理器内存以分配的数量开始,在我们的例子中是3 GB。 最终,内存开始减少,直到达到约160 MB,此时,它会恢复一点内存,所以不会达到其极限。 这种非常低的内存通常会导致作业因任务管理器心跳异常而终止,即使在尝试查看Flink仪表板上的日志或执行作业流程时也是如此。 为什么它的内存
-
如何用线程池并行化单个quartz作业?
我在Spring boot应用程序中有一个quartz调度作业,通过每5分钟激发一次的方法,将一个大列表中的项目发送到一些webservices。 我在下面的代码中尝试了一个,其池大小为5个线程。然而,当我执行并检查作业日志时,它说作业只需几秒钟就完成了,但发送所有数据需要几分钟。它继续正常工作,但工作似乎在几秒钟内完成。它可能表示在设置了所有线程之后作业就完成了。这是我避免的,因为我不知道作业执