《计算机视觉岗》专题
-
r计算同名列的均方差
我有一个简短的问题 我有一个数据帧,有许多测量列。我想计算具有相同(标题)名称的列的平均值。我使用下面的代码(在stackoverflow中找到)。。 如何计算数据帧中具有相同列名的列的平均值 作为示例数据... 结果是这样的。。。 这段代码告诉我具有相同(标题)名称的列的含义。 但是我也想要均方差。我试着用rowSds替换rowMeans,但是不起作用。 知道如何使用相同的代码来计算均方差吗??
-
Tip计算器函数的InnerHTML问题
因此,我希望当您输入支票金额和小费百分比并单击“计算小费”按钮时,它将运行函数,innerHTML将函数的输出写入div容器中的页面。然而,当我点击按钮时,似乎什么也没发生。如果有人有任何帮助/指导,我将不胜感激。
-
从字符串计算Modbus RTU的CRC
我有字符串:。我需要计算这个字符串的CRC。 我有一个计算CRC的函数: 我想将一个字符串强制转换为ushort数组: 但是返回给我的是这样一个数组:。 请告诉我为了正确计算CRC我应该做些什么。
-
 Concox跟踪器的16bit CRC-ITU计算
Concox跟踪器的16bit CRC-ITU计算我正在为一个服务器程序创建C#代码,该程序通过TCP从Concox TR06 GPS跟踪器接收数据: http://www.iconcox.com/uploads/soft/140920/1-140920023130.pdf 当第一次启动时,跟踪器发送一个登录消息,在发送任何位置数据之前,需要确认该消息。我的第一个问题是,根据文档,确认消息是18字节长,而它们提供的示例只有10字节长: 现在,我猜
-
在Java中计算多年即闰年
键入结束年度:2013 2008年是闰年 2012年是闰年 非常感谢您的回复!帮助我学到了比我的讲师实际教的更多的东西:)
-
计算两次之间的毫秒数
我试图计算两个时间之间有多少毫秒(例如,从13:00到13:01,有60000毫秒)。时间由2个整数(小时、分钟)表示。 我写了这个函数: 然而,当第二次是第二天时,这将不起作用(例如,从周日14:00到周一13:00之间有多少毫秒?)
-
JavaFX计算器中的方程问题
我的JavaFX/Java计算器有问题。当我输入一个方程式时,它(计算器)工作正常,答案也正确。但是,当我在另一个操作中按下/键,然后再按下另一个数字时,结果/和/等将不正确,除非我按下/键的运算符与之前相同。下面是一个例子: 工程量:26=82=10 不起作用:26=8-2=10 工程:6x2=12x2=26 不起作用:6x2=12÷2=26 我想知道有没有办法解决这个问题。 这是我的FXML控
-
创建计算器但无法退出
我需要编码方面的帮助。我再次练习我的java编程,今天我创建了一个计算器,它具有与真正的计算器相同的功能,但我再次遇到错误,无法再次计算。 好的,我希望我的计算器工作的方式是,而不是像这样从用户那里获取逐行输入:- 代码内输出 我想让它在用户按下enter键时进行计算,如下所示:- 我想要的输出 因此,他们可以在按下enter calculate键之前添加任意长的数字。用户应该能够在计算循环中使用
-
OWLAPI慢速计算不相交公理
问题是:执行时间非常慢,我会说是永恒的。即使我减少了一些if语句的比较数,情况还是一样的。 Protege似乎非常快地计算出这些推断的公理,并且它基于我正在使用的相同API(OWLAPI)。那么,我是不是走错了路?
-
计算文档文档中的页数
我有一个word文件,我想数一下里面有多少页。 已使用Docx4Java创建该文件。 以前有人这么做过吗? 谢谢!
-
 计算云中的多个重复值
计算云中的多个重复值我需要计算某个值在一列中出现的次数 看起来是这样的(< code > select * from znajezyki order by klos ) klos-是一个人的序列号(重复此值) 现在我需要创建一个查询,显示有多少人知道1,2,3种语言 如果相同的“klos”值重复2次,则意味着这个人知道2种语言,如果它出现3次,则意味着pearson知道3种语言,依此类推 我试着在这里参考这篇文章,但
-
Spark emr重新分配计算合并
我有一个新手火花问题。下面是我试图执行的程序: 我试图做的计算(doComput)是昂贵的,因为内存限制,我决定将数据集重新分区为7000个分区(即使我有1200个执行器,所以一次只能执行1200个)。然而,在完成计算后,我尝试写入s3,它大部分工作正常,但很少有任务最终超时,工作被重试。 1) 为什么在我保存在进行昂贵计算后生成的RDD时,整个作业都会被重试? 2) 我试图在持久化之后合并,但s
-
用于高性能计算的C++类
最简单的经验法则之一是记住硬件喜欢数组,并且针对数组的迭代进行了高度优化。对许多问题的一个简单优化只是停止使用花哨的数据结构,只使用简单的数组(或C++中的std::vectors)。这需要一些时间来适应。 C++类是那种“奇特的数据结构”,即一种可以用数组代替的数据类型,以在C++程序中获得更高的性能吗?
-
自动显示计算器的结果
我是机器人和爪哇的新手。我已经构建了一个计算器,当我输入3个输入时,我需要它来自动显示结果,但我不知道该怎么做。 我将multiply添加到了一个文本视图(通过属性onclick),它可以工作,但我希望它能在textview中自动显示。
-
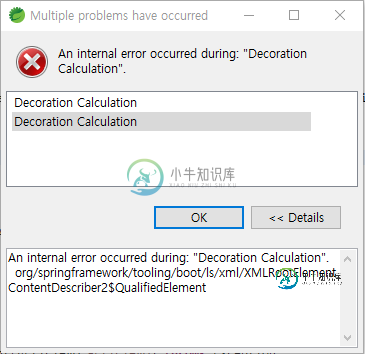 Eclipse上的装饰计算错误(STS)
Eclipse上的装饰计算错误(STS)当我试图在STS上打开xml文件时,我得到一个错误。 内容如下: “装饰计算”期间发生内部错误。org/springframework/tooling/boot/ls/xml/XMLRootElementContentDescriber2$QualifiedElement 当我查看元数据中的日志时,输出了以下错误消息。 有什么问题?STS版本是4.3.2。