《中国兵器》专题
-
哨兵
主要内容:一、哨兵,二、源码分析,三、总结一、哨兵 Sentinel(哨兵),听名字大家都应该想得到这个家伙是做什么的。在redis的应用中,有单机模式、主从模式、哨兵模式和集群模式,其实你从它的发展就可以看出来,redis是从一个简单的应用开始,不断的壮大,从单点到分布式,从简单的主从备份以及初始的哨兵监控,再到可以看成把二者合成的集群模式,除了是应用场景的变化,更多的是为了提高安全性和高可用性。网上有很多人问哨兵和集群有啥不一样,其实
-
卫兵( Guards)
防护是我们可以用来增加模式匹配能力的结构。 使用警卫,我们可以对模式中的变量执行简单的测试和比较。 guard语句的一般语法如下 - function(parameter) when condition -> Where, Function(parameter) - 这是保护条件中使用的函数声明。 Parameter - 通常保护条件基于参数。 Condition - 应该评估的条件,以查看是否
-
v Redis 哨兵
Redis 哨兵(Sentinel)是 Redis 的高可用性(Hight Availability)解决方案:由一个或多个 Sentinel 实例组成的 Sentinel 系统可以监视任意多个主服务器,以及这些主服务器的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器的某个从服务器升级为新的主服务器,然后由新的主服务器代替已下线的主服务器继续处理命令请求。 Sentinel
-
Redis哨兵不会自动发现其他哨兵
每一个哨兵都可以连接到我的主人,并可以看到奴隶。它们能够独立地检测主从是否倒下。问题是哨兵们无法探测到对方。 我已经验证了每个哨兵都像预期的那样向通道发布消息,但似乎没有一个哨兵真正从其他哨兵通道接收消息。 我怎么让哨兵们见面?
-
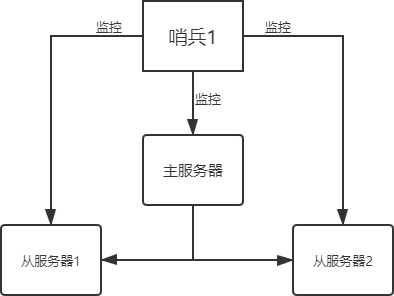 Redis哨兵模式
Redis哨兵模式主要内容:哨兵模式原理,哨兵模式应用,sentinel.conf配置项在 Redis 主从复制模式中,因为系统不具备自动恢复的功能,所以当主服务器(master)宕机后,需要手动把一台从服务器(slave)切换为主服务器。在这个过程中,不仅需要人为干预,而且还会造成一段时间内服务器处于不可用状态,同时数据安全性也得不到保障,因此主从模式的可用性较低,不适用于线上生产环境。 Redis 官方推荐一种高可用方案,也就是 Redis Sentinel 哨兵模式,它弥补了主
-
CSS卫兵(CSS Guards)
描述 (Description) 防护用于匹配简单值或表达式上的许多参数。 它适用于CSS选择器。 它是声明mixin并立即调用它的语法。 要成功显示if类型语句; 加入这个功能& ,它允许您分组多个警卫。 例子 (Example) 以下示例演示了在LESS文件中使用css guard - css_guard.htm <!doctype html> <head> <link re
-
1个雷迪斯哨兵vs多个雷迪斯哨兵?
我一直在读有关Redis sentinel用于故障转移的文章。我计划有1主+1从,如果主倒下超过1分钟,把从变成主。我知道这在哨兵身上是百分之百可能的。 null 与1个哨兵相比,多个哨兵有什么好处?我的应用程序一次只能连接到1个哨兵,即使有2个哨兵,如果其中一个在应用程序层中出现复杂的逻辑,我的应用程序也不能在其中任何一个之间旋转或切换。
-
Laravel错误的哨兵
我正在与一个远程合作伙伴开发一个Laravel项目。 我没有安装mcrypt,所以每次需要使用composer时,我都会通过别名引用php: 这是一个很好的修复,直到我的远程朋友安装了哨兵软件包,这是我无法做到的。 使用另一个stackoverflow线程,我能够使用mcrpyt引用正确版本的php,更新composer并安装sentry。 我的问题是: Sentry在我搭档的本地主机上工作,我将
-
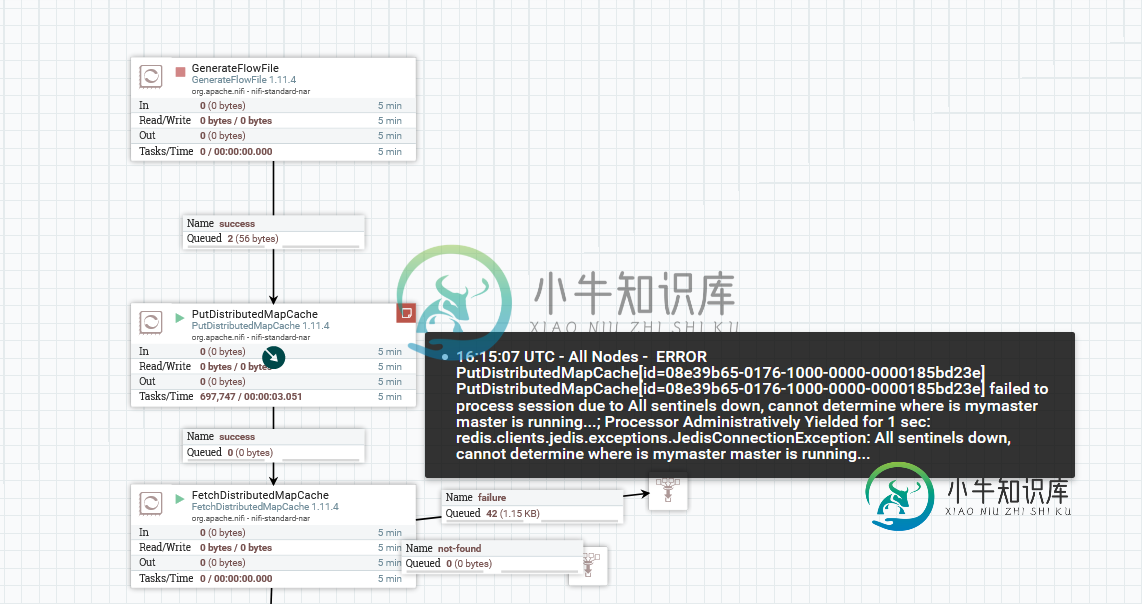 Nifi Redis哨兵积分
Nifi Redis哨兵积分我试图在哨兵模式下将Nifi与Redis集成,如本教程所述: https://bryanbende.com/development/2017/10/09/apache-nifi-redis-integration 我的Redis集群有2个节点,运行在端口6391上,还有2个sentinel,运行在端口6392上。它似乎工作正常: PutDistributedMapCache[ID=08E39B65
-
带TLS的Redis哨兵
Redis4.x是否兼容使用Sentinels运行TLS?我发现一些线程提到对TLS的支持将被添加到3.2中,但没有任何证实。
-
双链表哨兵法
我在Java双向链表,我在书的双向链表中阅读哨兵。其中指出 为了避免在双链接列表的边界附近操作时出现一些特殊情况,可以在列表的两端添加特殊节点:列表开头的头节点和列表末尾的尾节点。这些“虚拟”节点称为Sentinel(或guards),它们不存储主序列的元素 那些特例是什么?为什么我们需要哨兵接近?这是强制性的吗?如果我们对双向链表使用普通方法(没有哨兵),不会节省这些额外节点的内存吗?当用循环方
-
纸上谈兵: 图 (graph)
图(graph)是一种比较松散的数据结构。它有一些节点(vertice),在某些节点之间,由边(edge)相连。节点的概念在树中也出现过,我们通常在节点中储存数据。边表示两个节点之间的存在关系。在树中,我们用边来表示子节点和父节点的归属关系。树是一种特殊的图,但限制性更强一些。 这样的一种数据结构是很常见的。比如计算机网络,就是由许多节点(计算机或者路由器)以及节点之间的边(网线)构成的。城市的道
-
纸上谈兵: 堆 (heap)
堆(heap)又被为优先队列(priority queue)。尽管名为优先队列,但堆并不是队列。回忆一下,在队列中,我们可以进行的限定操作是dequeue和enqueue。dequeue是按照进入队列的先后顺序来取出元素。而在堆中,我们不是按照元素进入队列的先后顺序取出元素的,而是按照元素的优先级取出元素。 这就好像候机的时候,无论谁先到达候机厅,总是头等舱的乘客先登机,然后是商务舱的乘客,最后是
-
纸上谈兵: AVL树
二叉搜索树的深度与搜索效率 我们在树, 二叉树, 二叉搜索树中提到,一个有n个节点的二叉树,它的最小深度为log(n),最大深度为n。比如下面两个二叉树: 深度为n的二叉树 深度为log(n)的二叉树 这两个二叉树同时也是二叉搜索树(参考树, 二叉树, 二叉搜索树)。注意,log以2为基底。log(n)是指深度的量级。根据我们对深度的定义,精确的最小深度为floor(log(n)+1)。 我们将处
-
纸上谈兵: 栈 (stack)
栈(stack)是简单的数据结构,但在计算机中使用广泛。它是有序的元素集合。栈最显著的特征是LIFO (Last In, First Out, 后进先出)。当我们往箱子里存放一叠书时,先存放的书在箱子下面,我们必须将后存放的书取出来,才能看到和拿出早先存放的书。 栈中的每个元素称为一个frame。而最上层元素称为top frame。栈只支持三个操作, pop, top, push。 pop取出栈中