《图像算法工程师》专题
-
在JavaFX中加载图像
下面是我的代码: 只是一个加载图像的文件。 我得到以下错误: 以下是完整的代码:
-
JavaFX创建图像和ImageView
停留在基础上。我在设置图像路径时遇到了一些语法问题。当我尝试创建一个图像并给它图像路径时,它总是抛出一些关于路径的一些异常。我已经评论了一些我已经尝试过的路径组合。你能告诉我我做错了什么吗?谢谢你。 封装JOPOFX; 这是打印出来的内容:错误while creating image java.lang.IllegalArgumentException:无效URL:在javafx.scene.im
-
Javafx从jar加载图像
我正在使用Scene Builder2.0和eclipse Luna。在fxml文件中,我有我的场景的代码和图像。如果我在eclipse上测试这一点,一切都是正常的,但是如果我将它导出到可运行的jar中,然后运行它,我就会得到没有图像的窗口...以下是部分代码: 文件结构: 我觉得问题出在路径上,但我不知道这条路是怎么走的。加载程序代码: 初始化函数:
-
docx4j-文档中的图像
如何从docx4j中删除图像。 假设我有10个映像,我想用我自己的字节数组/二进制数据替换8个映像,我想删除剩下的2个。 我也有麻烦在定位图像。 是否可以用图像替换文档中的文本占位符?
-
Vaadin流:字节[]到图像
我尝试显示一个图像,作为blob存储在表中。 因此,我需要将byte[]转换为Vaadin图像类(我想这是显示它的最佳方式?)。 我尝试此解决方案(4岁): https://vaadin.com/forum/thread/10271496/byte-array-to-vaadin-image 它不起作用: 在瓦丁13我怎么做?
-
使用PDFBox旋转图像
我刚开始使用PDFBox。我需要的是将图像旋转添加到退出的PDF中!我知道如何添加图像,但我的问题是如何旋转图像!我看到了一些关于AffineTransform和Matrix的信息,但我不知道那是什么以及它是如何工作的! 我真的很感谢通过一些样本代码,并提前感谢你! 致敬
-
JavaFX 2.2 中的 SVG 图像
我是JavaFX 2.2的新手,到目前为止,我无法找到在我的JavaFX 2.2应用程序中显示SVG图像的方法。我看了一下Batik,但它没有为我做这个把戏,因为它可以转换为而不是。 有什么方法可以在JavaFX应用程序中显示SVG图像?或者至少可以从JavaFX导出一个SVG图像?函数< code>Node.snapshot()有什么帮助吗?
-
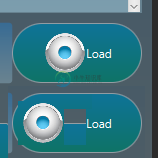 图像圆角按钮 JavaFX
图像圆角按钮 JavaFX我正在使用圆形按钮,我想在里面有一个图像。问题是图像在中心,而不是在左边,即使调用 loadButton.setAlignment(Pos.BASELINE_LEFT); 我得到的是上面的按钮,我需要的是下面的按钮。你知道在圆角下显示png的方法吗? 非常感谢!
-
MariaDB插入斑点图像
我想做什么? 我想使用命令行插入图片到MariaDB数据库,使用LOAD_FILE功能。 发生了什么? 我总是得到一个NULL返回。 我不想要这样的解决方案:这是糟糕的风格,到目前为止我还没有看到过-尝试存储完整的路径!我想将此图片存储在这个数据库中,而不是路径中。 系统 > ArchLinux 4.7.2-1-ARCH 一张叫做“测试”的照片。jpg(817KB)位于,甚至在 这张图片属于用户和
-
 使用ServletContext返回图像
使用ServletContext返回图像我试图用ServletContext返回一个图像,但出现500个错误,控制台显示: java.lang.NullPointerException: null at org.apache.commons.io.IOUtils.copyLarge(IOUtils.java:2146) 在 org.apache.commons.io.io.ioUtils.copy(IOUtils.java:2102)
-
Tesseract错误-图像太大
我收到了来自tesseract的5 MB大小图像的以下错误。 Tesseract开源OCR引擎v3.01与Leptonica第0页图像太大:(39667,56133)处理过程中出现错误。 文件大小是否有限制,或者是否有解决此问题的参数。 感谢您的帮助。
-
 改装-Spring图像上载
改装-Spring图像上载我有一个问题上传文件到服务器(春季启动)从Android-改版。 这是我在Spring Boot中的代码。 这是在Android中 这是Spring Boot中的错误消息 但是,当我用邮递员的时候,它做得很好。 请告诉我问题是什么,如何解决
-
JPG与JPEG图像格式
(摘自那里的第一个答案)。那么两款加长版有没有大的区别呢?如果是的话,是什么?
-
 脚手架背景图像
脚手架背景图像我想把图像设置为脚手架的背景色。当设置一个AppBar和bottom bar时,使用容器的装饰作为脚手架的主体并不能覆盖整个屏幕。 我想为全屏显示背景。下面是我的脚手架代码:
-
 Android:如何扭曲图像?
Android:如何扭曲图像?我想像这样扭曲图像: 2013年4月8日新增:我使用了此代码,但无法正常工作: