《联想算法工程师》专题
-
 微步在线 机器学习算法工程师 二面面经
微步在线 机器学习算法工程师 二面面经地狱一样的理论问询,今年秋招最难的一场…… 数学问了中心极限定理,大数定理,Γ分布和κ分布关系…… 机器学习问了特征选择,特征归一化,马尔科夫链,gibbs采样,集成学习,选择性偏差,决策树并行计算,xgboost和adaboost样本权重…… 深度学习问了卷积原理,梯度传播稳定性,BN本质,torch和tensorflow的图理论…… 大模型问了很多工程上的问题,出现loss spike啦,波峰
-
 2025拼多多算法工程师笔试 0811拼多多笔试
2025拼多多算法工程师笔试 0811拼多多笔试1.旅游完所有景点需要的时间 第一行,一个整数N,表示有N个景点。第二行开始是景点信息,有三个整数,分别是优先级P(数字越小,优先级越高),首次预约日期X,允许再次前往的天数间隔D天(也就是预约时间变成:d+x*1/2/3)。输出要求,一个整数,表示完成旅游计划的天数。 Input 1: 3 3 2 3 1 3 2 2 2 2 output 1: 5 Input 2: 2 1 2 2 2 1 3
-
 快手秋招面经-视频策略模型算法工程师
快手秋招面经-视频策略模型算法工程师自我介绍 自己从简历上选一个与数据分析、建模有关的项目讲 (第一个项目:) 刚刚说到这是一个比赛,是kaggle的比赛吗 为什么选用XGBoost(隐含考察点:模型的使用场景) 提到样本倾斜的问题,应该怎么解决样本不均匀 (第二个项目:) 是直接用数据集里的特征进行建模(应该是想问有没有特征筛选) 有哪些特征筛选的方法 (实习)两份实习分别做什么 (知识点)有没有学过因果推断的课程或做过相关项目
-
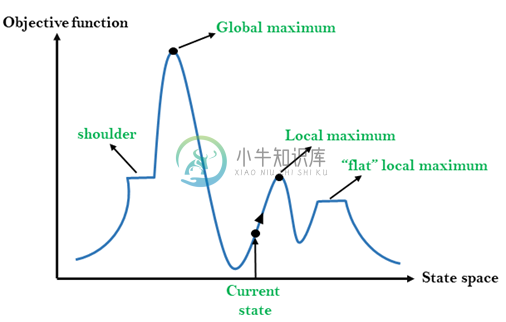 人工智能爬山算法
人工智能爬山算法主要内容:爬山算法的特点,爬山的国家空间图,状态的不同区域,爬山类型算法:,爬山算法存在的问题爬山(Hill Climbing)算法是一种局部搜索算法,它在增加高度/值的方向上连续移动,以找到山峰或最佳解决问题的方法。它在达到峰值时终止,其中没有邻居具有更高的值。 爬山算法是一种用于优化数学问题的技术。其中一个广泛讨论的爬山算法的例子是旅行商问题,其中我们需要最小化推销员的行进距离。 它也称为贪婪的本地搜索,因为它只关注其良好的直接邻居状态而不是超越它。爬山算法的节点有两个组成部分,即状态
-
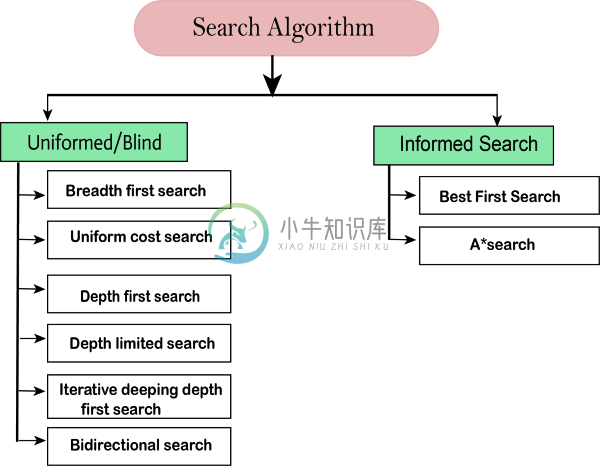 人工智能搜索算法
人工智能搜索算法主要内容:解决问题的代理,搜索算法术语,搜索算法的属性,搜索算法的类型搜索算法是人工智能最重要的领域之一。本主题将解释有关AI中搜索算法的所有信息。 解决问题的代理 在人工智能中,搜索技术是普遍的问题解决方法。AI中的合理代理或问题解决代理主要使用这些搜索策略或算法来解决特定问题并提供最佳结果。解决问题的代理是基于目标的代理并使用原子表示。在本主题中,我们将学习各种解决问题的搜索算法。 搜索算法术语 搜索:搜索是一个一步一步的过程,用于解决给定搜索空间中的搜索问题。
-
 25柳工AI算法研发
25柳工AI算法研发9.19:一面,自我介绍,问了问算法有没有工厂实际应用,问了问职业规划跟在公司工作看中什么。剩下就是了解基本情况,不涉及技术问题全程十五分钟 #柳工机械#
-
 联想 UI设计师 面试经验( 北京 )
联想 UI设计师 面试经验( 北京 )联想内部新组建的一个小组,工作职责是负责tob的网站设计。两个面试官,不是设计从业者,问问题的速度很快,在面试的时候不怎么看作品集,注重web经验,要懂一些交互知识。 1.自我介绍(面试官没看作品集和简历) 2.学校经历 3.web设计尺寸 4.你在做移动界面的时候用多大字 5.双平台设计差异 6.会针对不同系统做不同的设计么 7.设计规范异同 8.喜欢的设计师 9.喜欢的软件 10.最满意的作品
-
关联规则挖掘算法apriori原理?
本文向大家介绍关联规则挖掘算法apriori原理?相关面试题,主要包含被问及关联规则挖掘算法apriori原理?时的应答技巧和注意事项,需要的朋友参考一下 一个频繁项集的子集也是频繁项集,针对数据得出每个产品的支持数列表,过滤支持数小于预设值的项,对剩下的项进行全排列,重新计算支持数,再次过滤,重复至全排列结束,可得到频繁项和对应的支持数。 作者:@小黑 以下是自己的理解,如果有不对的地方希望各位
-
 23届校招 联影智能算法岗
23届校招 联影智能算法岗8月27号下午突然打电话通知面试,刚睡醒还在刷抖音呢,直接措手不及。 1面 电话面试 30min 1、自我介绍 2、yolo中正样本和负样本如何定义的 3、如何提高模型的泛化能力 4、C++中,指针和引用 5、如何解决长尾分布(数据不平衡) 6、concat和add区别 各自使用场合 7、Transformer中为何使用多头 8、LN和BN的区别 为何Transformer中使用LN 9、sif
-
使用Apriori算法进行关联分析
关联分析 关联分析是一种在大规模数据集中寻找有趣关系的任务。 这些关系可以有两种形式: 频繁项集(frequent item sets): 经常出现在一块的物品的集合。 关联规则(associational rules): 暗示两种物品之间可能存在很强的关系。 相关术语 关联分析(关联规则学习): 从大规模数据集中寻找物品间的隐含关系被称作 关联分析(associati analysis) 或者
-
 tp普联通信算法(杭州)一面
tp普联通信算法(杭州)一面面试时间 6月5号 时长 30分钟 基本信息 项目 两个通信八股 自我介绍蠢了说了意向地成都🤣不知道有没有影响
-
 2025届秋招 联影医疗算法岗
2025届秋招 联影医疗算法岗投递岗位:软件算法工程师(智能语音方向) 时间节点: 8.12 投递简历 8.15 电话约面试 8.16 电话面试 8.16 邮件通知下周二面 一轮面试内容: 第一轮是电话面试,过程持续近40分钟,提前一天约了,当天有事所以约到第二天,并且开始没听清楚公司名字,第二天面的时候还不知道对面是哪家公司,一开始有点尬。 主要流程:自我介绍-介绍项目并询问细节(算法细节、项目难点、如何解)-介绍实习工作(
-
 tplink联洲 通信算法三面 深圳
tplink联洲 通信算法三面 深圳6.6笔试测评,6.9一面,6.13二面,6.27线下三面,6.28心理测评通过。感觉和别人不太一样,我的三面其实还是技术面,基本没有闲聊。 1、自我介绍。家在哪。 2、本科成绩,双学位情况,考研情况。 3、详细问了简历的两个项目,但没有问具体的技术细节,只是讲算法实现了什么功能,遇到了什么问题,为什么会有这样的问题。持续15分钟+ 4、没有反问环节。 没有反问环节我是没想到的,也没什么闲聊,以为
-
k-means算法流程
本文向大家介绍k-means算法流程相关面试题,主要包含被问及k-means算法流程时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 从数据集中随机选择k个聚类样本作为初始的聚类中心,然后计算数据集中每个样本到这k个聚类中心的距离,并将此样本分到距离最小的聚类中心所对应的类中。将所有样本归类后,对于每个类别重新计算每个类别的聚类中心即每个类中所有样本的质心,重复以上操作直到聚类中心不变为止。
-
 常规算法教程
常规算法教程大家好,今天我们开始学习一个新专题 — 算法(Algorithm)。关于算法,我们日常开发中有很多应用,介绍算法的书籍也有很多,其中涉及到的知识点和信息量都很庞大,这个专题我们重点针对基于 Java 语言实现的算法设计和应用进行讲解,读者也可以自己将其扩展到其他语言的实现。