《高德》专题
-
高级用户交互
入门 高级用户交互API提供了一个更新更完善的机制来定义并描述用户在一个网页上的各种操作。这些操作包括:拖拽、按住CTRL键选择多个元素等等。 快速上手 为了生成一连串的动作,我们使用Actions来建立。首先,我们先配置操作: Actions builder = new Actions(driver); builder.keyDown(Keys.CONTROL) .click(someE
-
常用高阶函数
常用高阶函数 1.map 对于原始集合里的每一个元素, 以一个变换后的元素替换之形成一个新的集合 1.1 flatmap 对于元素是集合的集合, 可以得到单级的集合 let results = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] let allResults = results.flatMap{ $0.map{ $0 * 10 } } let passMarks =
-
4.1.1.1.3-PostgreSQL_XL高可用性
(1)GTM不可用导致整个Postgresql集群不可用。 (2)对于Coordinator,不一定需要需要实现高可用。 (3)对于DataNode,实现高可用的方式,外部使用统一IP访问,所以需要实现VIP。 (4)数据分库后,对于使用Postgresql单机进行存储的数据库,需要实现Postgresql服务高可用。 (5)防止出现脑裂,实现高可用的服务,在同一时刻仅有一台物理节点提供服务。对于
-
高并发测试-ConcurrencyTester
由来 很多时候,我们需要简单模拟N个线程调用某个业务测试其并发状况,于是Hutool提供了一个简单的并发测试类——ConcurrencyTester。 使用 ConcurrencyTester tester = ThreadUtil.concurrencyTest(100, () -> { // 测试的逻辑内容 long delay = RandomUtil.randomLong(
-
高级发布机制
目前你应该对发布和订阅交互模式有一个不错的掌握了。因此,我们废话少说,来看几个更高级的情景。 多次发布一个集合 在我们第一个关于发布的附录中,我们看到了一些更普遍的发布和订阅模式,同时我们学习了 _publishCursor 函数,如何让它们非常容易地实现在我们的站点上。 首先,让我们回忆 _publishCursor 到底为我们做了什么:它将整理所有的文档以匹配一个给定的游标(cursor),并
-
高级的响应性
虽然需要你自己写代码来跟踪依赖变量的情况十分罕见,了解依赖变量的工作流程还是十分必要的。 设想我们现在需要跟踪一下 Microscope上,当前用户的 Facebook 朋友在 “like” 某一篇帖子的数量。 让我们假设我们已经解决了 Facebook 用户认证的问题,运用了正确的 API 调用,而且也解析了相关数据。 我们现在有一个异步的客户端函数返回 like 的数量,getFacebook
-
 高途测开一面
高途测开一面10-7日 1.自我介绍 2.问我学校的项目 3.问我为这个项目带来了哪些改进 4.问我觉得自己最有成就感的事儿 5.最挫败的事情 6.三年内的职业规划 7.输入一个网址后发生什么 8.TCP连接 三次握手 9.数据库增删改查 右连接 10.linux的常用命令 怎么关闭端口(不会 11.python虚拟环境的一些常用命令 12.讲一下我的科研方向 13.为什么不做算法 来做测试 14.讲一下测试
-
 C++面试高频(一)
C++面试高频(一)1.new和malloc的区别(使用和原理)⭐ new的定义: new是C++的关键字,用于动态分配内存并创建对象。它可以根据类型自动计算所需内存空间,并调用对象的构造函数进行初始化。在使用new分配内存后,需要使用delete来释放这些内存空间,以防止内存泄漏。 malloc的定义: malloc是C语言的库函数,用于动态分配一块指定大小的内存块,并返回其地址。需要注意的是,使用malloc分配
-
 高途-数分-一面
高途-数分-一面发一发最近的面经 大概20分钟,感觉有点水,最后应该是把我挂了 1、自我介绍 2、选择岗位、行业、企业的时候会考虑哪些因素 3、问tx实习的时候有什么最难的项目,是怎么解决的,有什么产出 4、数分项目中主要关注哪些数据指标、如何拆解、如何量化 5、输出了哪些数据报告,有什么结论和产出 6、工作中,导师对你的意义是什么? 7、场景提问,网课老师授课一学期,然后会有部分学生会转入下学期,期间会产生一系
-
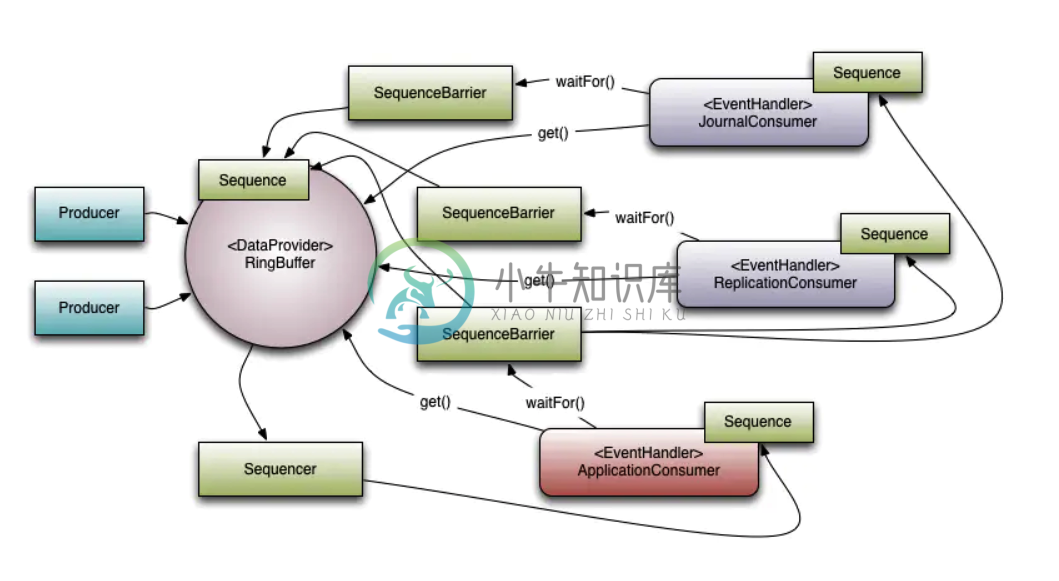 高并发框架 Disruptor
高并发框架 Disruptor主要内容:1.Disruptor介绍,2.Disruptor 的核心概念,3.demo1.Disruptor介绍 Disruptor是一个开源的Java框架,它被设计用于在生产者—消费者(producer-consumer problem,简称PCP)问题上获得尽量高的吞吐量(TPS)和尽量低的延迟。 从功能上来看,Disruptor 是实现了“队列”的功能,而且是一个有界队列。那么它的应用场景自然就是“生产者-消费者”模型的应用场合了。 其实Disruptor与其说是一个框架,不
-
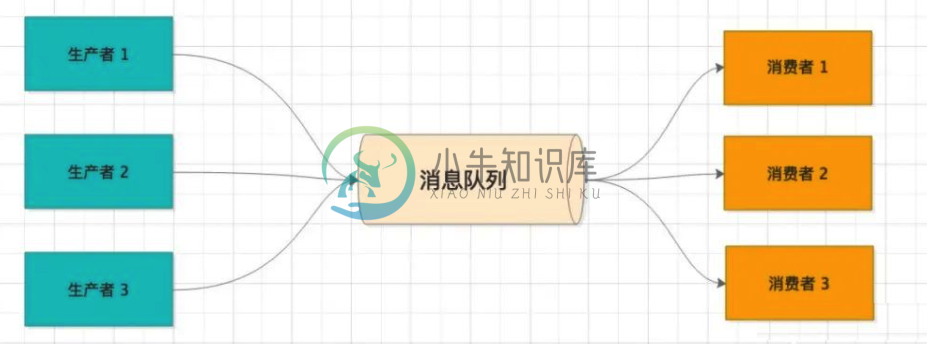 高可用的技巧
高可用的技巧主要内容:1.系统拆分,2.解耦,3.异步,4.重试,5.补偿,6.备份,7.多活策略,8.隔离,9.限流,10.熔断,11.降级1.系统拆分 微服务架构,将一个复杂的业务域按DDD的思想拆分成若干子系统,每个子系统负责专属的业务功能,做好垂直化建设,各个子系统之间做好边界隔离,降低风险蔓延。 2.解耦 高内聚、低耦合。小到接口抽象、MVC 分层,大到 SOLID 原则、23种设计模式。核心都是降低不同模块间的耦合度,避免一处错误改动影响到整个系统。 就以开闭原则为例,对扩展是开放的,对修改是关
-
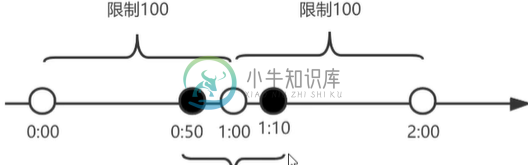 高并发之限流
高并发之限流主要内容:1.算法,2.单机限流器,3.分布式限流器,4.接入层限流器1.算法 计数器 漏桶算法 令牌桶算法 滑动窗口算法 1.1 计数器法 实现简单, 就是临界值问题 指在指定的时间里累加访问量,达到阈值后,触发限流策略,在下一周期访问数量清除 使用redis的incr和key过期 问题:在相邻的一个时间段20s内,请求超过100。 这个算法通常用于QPS限流和统计总访问量,对于秒级以上的时间周期来说,会存在一个非常严重的问题,那就是临界问题。 假设1min内服务
-
高级事件统计
6.8.1 概述 高级事件统计 与 (简单)事件统计均属于用户与网站的交互事件统计。 与简单事件统计相比,高级事件统计可统计更多维度、指标的数据, 常见场景如表单信息的统计,包括汽车预约试驾表单,化妆品的申领使用等。 6.8.2 对比 高级事件统计 与(简单)事件统计 对比 统计维度 统计指标 附属系统默认指标 高级事件统计 可统计至多20个维度 可统计至多20个指标 事件次数、事件唯一访问量、事
-
高级知识用法
高级知识用法 1.高级知识类型 知识库除了普通问答以外,系统还提供多种知识展现形式,方便通过组合不同形式的知识形成多轮对话及多维知识体系,高级知识类型总体包括以下类型: 智能录入-问题链接/条件答案:通过设定问题的进一步链接和条件,帮助用户点击下一个答案。 智能录入-动态答案/变量答案:通过在答案中添加动态变量,在多个问题中添加统一变量,并且针对变量进行变更时,会将所有变量进行变更。 智能录入-随
-
基本语法高亮
既然已经移除前进路上的绊脚石,是时候开始为我们的Potion插件写下一些有用的代码。 我们将从一些简单的语法高亮开始。 在你的插件的repo中创建syntax/potion.vim。把下面的代码放到你的文件里: :::vim if exists("b:current_syntax") finish endif echom "Our syntax highlighting code wil