《规控》专题
-
ArrayList及HashMap的扩容规则讲解
本文向大家介绍ArrayList及HashMap的扩容规则讲解,包括了ArrayList及HashMap的扩容规则讲解的使用技巧和注意事项,需要的朋友参考一下 1、ArrayList 默认大小为10 最大容量为2^30 - 8 扩容规则为:oldCapacity*1.5 2、HashMap 默认大小: 16 最大容量为:2^30 扩容规则为:大于oldCapacity的最小的2的n次方整数 总结
-
 培养自己的php编码规范
培养自己的php编码规范本文向大家介绍培养自己的php编码规范,包括了培养自己的php编码规范的使用技巧和注意事项,需要的朋友参考一下 为什么我们要培养自己的编码规范? 我们写代码的时候,一个好的编码规范,对我们来说能够起到很多意向不到的效果。至少会有一下的好处: 1、提高我们的编码效率。整齐划一的代码方便我们进行复制粘贴嘛! 2、提高代码的可读性。 3、显示我们专业。别人看到了我们的代码,发现整个代码的书写流程都整齐划
-
什么是猫鼬(Nodejs)复数规则?
问题内容: 我是Node.js,Mongoose和Expressjs的新手。我试图通过以下代码在MongoDB中使用Mongoose创建一个表“ feedbackdata”。但是它被创建为“ feedbackdata * s *”。通过谷歌搜索,我发现猫鼬使用了复数规则。任何人都可以帮助我删除复数规则吗?或“ feedbackdata”表的代码应如何? 下面是我的代码: }); 问题答案: 该文件
-
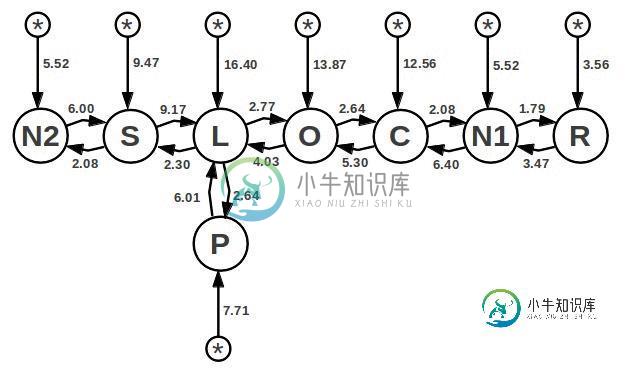 详解SQLite中的查询规划器
详解SQLite中的查询规划器本文向大家介绍详解SQLite中的查询规划器,包括了详解SQLite中的查询规划器的使用技巧和注意事项,需要的朋友参考一下 1.0 介绍 查询规划器的任务是找到最好的算法或者说“查询计划”来完成一条SQL语句。早在SQLite 3.8.0版本,查询规划器的组成部分已经被重写使它可以运行更快并且生成更好的查询计划。这种重写被称作“下一代查询规划器”或者“NGQP”。 这篇文章重新概括了查询规划的重
-
了解Elasticsearch的write_consistency和仲裁规则
问题内容: 根据elasticsearch文档,write_consistency级仲裁的规则是: 仲裁(> replicas / 2 + 1) 使用ES 0.19.10,在具有16个分片/ 3个副本的设置中,我们将获得16个主分片48个副本 运行2个节点,我们将有16个(主)+ 16个(副本)= 32个活动分片。 为了满足仲裁规则,仲裁> 48/2 + 1 = 25个活动分片。 现在,进行测试证
-
Guice和常规应用程序配置
问题内容: 对于用Java编写的监视软件,我考虑使用Google Guice作为DI提供程序。项目需要从外部资源(文件或数据库)加载其配置。该应用程序旨在以独立模式或servlet容器运行。 目前,该配置不包含用于依赖项注入的绑定或参数,仅包含某些全局应用程序设置(JDBC连接定义和关联的数据库管理/监视对象)。 我看到两个选择: 使用另一个库,例如Apache Commons Configura
-
规避原产地政策的方法
问题内容: 同一原产地政策 我想制作有关HTML / JS 同源策略的社区Wiki,以希望能帮助任何人搜索此主题。这是关于SO的最热门搜索主题之一,并且没有统一的Wiki,所以我在这里:) 相同的来源策略可防止从一个来源加载的文档或脚本从另一个来源获取或设置文档的属性。该策略可以追溯到Netscape Navigator 2.0。 您采用哪种最喜欢的方式处理同源政策? 请保持详细示例,并最好也链接
-
Java:说说Java Bean的命名规范
JavaBean 类必须是一个公共类,并将其访问属性设置为 public JavaBean 类必须有一个空的构造函数:类中必须有一个不带参数的公用构造器,此构造器也应该通过调用各个特性的设置方法来设置特性的缺省值。 一个javaBean类不应有公共实例变量,类变量都为private 持有值应该通过一组存取方法(getXxx 和 setXxx)来访问:对于每个特性,应该有一个带匹配公用 getter
-
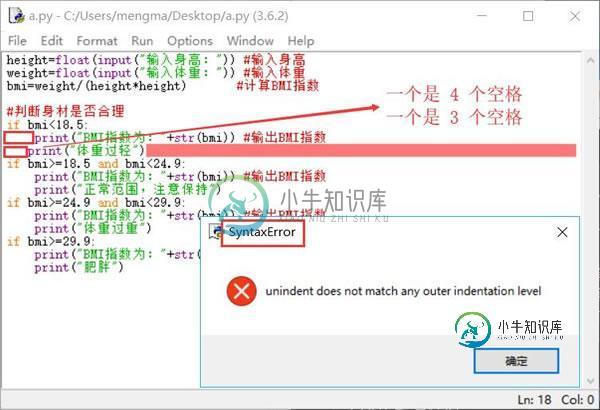 Python缩进规则(包含快捷键)
Python缩进规则(包含快捷键)和其它程序设计语言(如 Java、C 语言)采用大括号“{}”分隔代码块不同, Python 采用代码缩进和冒号( : )来区分代码块之间的层次。 在 Python 中,对于类定义、函数定义、流程控制语句、异常处理语句等,行尾的冒号和下一行的缩进,表示下一个代码块的开始,而缩进的结束则表示此代码块的结束。 注意,Python 中实现对代码的缩进,可以使用空格或者 Tab 键实现。但无论是手动敲空格
-
SELinux策略规则查看的方法
我们知道,当前 SELinux 的默认策略是 targeted,那么这个策略中到底包含有多少个规则呢?使用 seinfo 命令即可查询。命令如下: [root@localhost ~]# seinfo -b #还记得-b选项吗?就是查询布尔值,也就是查询规则名字 Conditional Booleans:187 #当前系统中有187个规则 allow_domain_fd_use allow_ftp
-
常规日志移动另一个表
使用MYSQL,我想在每一个数据处立即将我的数据从服务器A上的general_log表记录到服务器B上的一个表中,并在一天结束时从服务器A中删除数据。我试图为此使用触发器,但general_log不允许我编写触发器,因为它看到系统文件。或者,当我使用Fedareted表时,当我删除服务器A上的数据时,服务器B上的数据也会被删除。事先谢谢你的帮助。
-
用spring cli运行Spock规范测试
我在看一个例子,从沃尔的春靴在行动书。它是一个用Groovy编写的简单web应用程序。该项目使用Spring CLI构建、运行和测试,不使用gradle构建文件,并使用grabs.groovy文件提供H2和Thymeleaf依赖项。有两个测试班。第一个是JUnit测试,第二个是Spock规范。JUnit测试文件是: 我不擅长编写Spock测试,所以我不确定问题是什么。
-
关闭特定文件的eslint规则
是否可以关闭整个文件的eslint规则?某事,如: (类似于eslint-disable-line。)我经常遇到这样的情况,在某个文件中,我在许多地方违反了特定的规则,这对该文件来说是可以的,但我不想为整个项目禁用该规则,也不想为该特定文件禁用其他规则。
-
常规故障处理 - 缺失依赖
在默认状态下,Maven 在 build 的时候不会包含所依赖的 jar 包。当运行一个 Spark 任务,如果 Spark worker 机器上没有包含所依赖的 jar 包会发生类无法找到的错误(ClassNotFoundException)。 有一个简单的方式,在 Maven 打包的时候创建 shaded 或 uber 任务可以让那些依赖的 jar 包很好地打包进去。 使用 <scope>pr
-
10.1 典型插件的目录规范
10.1 典型插件的目录规范 学 VimL 脚本的终极目标是写插件按需扩展 vim 的功能。在开始着手写插件之前,有必 要先了解一下典型的、功能较齐全的插件,应该如何组织目录结构,按 vim 的习惯将不 同类别的功能放在相应的子目录下。 10.1.1 vim 运行时目录 插件的目录,可参考 vim 本身安装的运行时目录。所谓运行时目录,顾名思义,就是在 vim 运行时如果要加载 *.vim 脚本,