《一致性》专题
-
保持颜色一致
关于 Adobe 应用程序中的色彩管理 Adobe 色彩管理可以帮助您在不同的源之间保持图像的色彩一致,编辑文档并在 Adobe 应用程序间转换文档,以及输出已完成的合成图像。此系统基于国际色彩协会 (ICC) 开发的协定,该组织负责实现配置文件格式和程序的标准化,旨在通过一个工作流程获得准确和一致的颜色。 默认情况下, Adobe 应用程序中的色彩管理是打开的。如果您购买了 Adobe Crea
-
为什么MongoDB一致不可用和Cassandra可用不一致?
蒙戈 从这一资源中,我理解了为什么mongo不是基于以下陈述的 MongoDB支持“单主”模型。这意味着您有一个主节点和多个从节点。如果主人倒台,其中一个奴隶被选为主人。这个过程会自动进行,但需要时间,通常为10-40秒。在新领导人选举期间,您的副本集已关闭,无法进行写入 是否出于同样的原因,Mongo被称为(因为写入没有发生,所以返回系统中的最新数据),但不是(不适用于写入)? 在重新选择和写入
-
Protege标记本体不一致,但Hermit和Pellet Reasoner不一致
我试图在不一致的本体上运行一致性检查,Pellet和Hermit Reasoner没有给出不一致性。然而,Protege成功地标记了不一致的类。具体来说,我正在将SBVR规则更改为OWL2.0。所以我的规则是租车必须至少用3张信用卡投保;租车必须由至少5张信用卡投保; 相应的本体是 Hermit和Pellet将本体论标记为一致的,而AsProtege将这两个类标记为不一致的。 现在,如果我把我的S
-
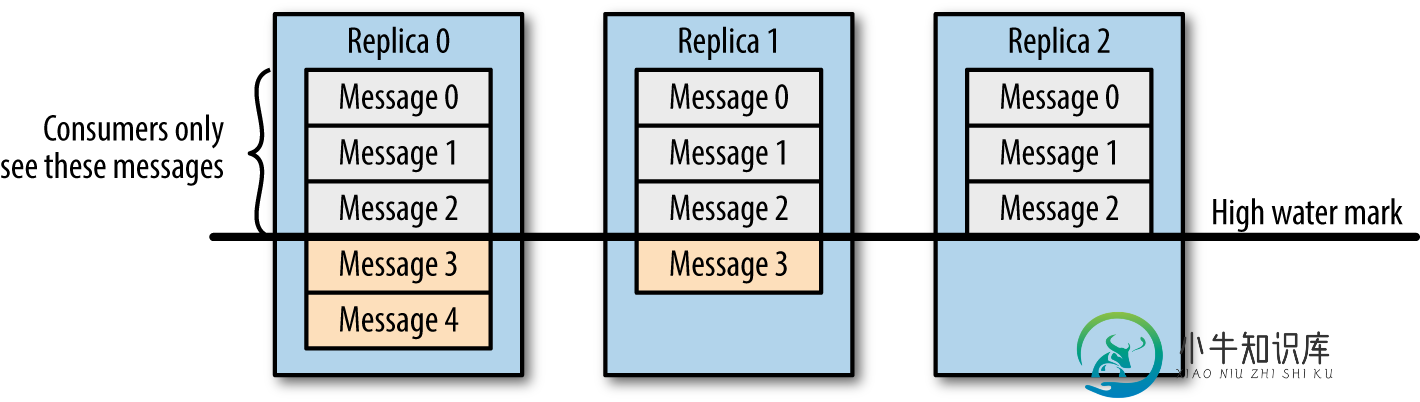 请谈一谈 Kafka 数据一致性原理?
请谈一谈 Kafka 数据一致性原理?本文向大家介绍请谈一谈 Kafka 数据一致性原理?相关面试题,主要包含被问及请谈一谈 Kafka 数据一致性原理?时的应答技巧和注意事项,需要的朋友参考一下 一致性就是说不论是老的 Leader 还是新选举的 Leader,Consumer 都能读到一样的数据。 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop 假设分区的副本为3,
-
第九章:一致性与共识
好死不如赖活着—— Jay Kreps, 关于Kafka与 Jepsen的若干笔记 (2013) [TOC] 正如第8章所讨论的,分布式系统中的许多事情可能会出错。处理这种故障的最简单方法是简单地让整个服务失效,并向用户显示错误消息。如果无法接受这个解决方案,我们就需要找到容错的方法—— 即使某些内部组件出现故障,服务也能正常运行。 在本章中,我们将讨论构建容错分布式系统的算法和协议的一些
-
使用get_or_insert实现强一致性
我有一个这样的模型: 由于以上字段都不是唯一的,所以电子邮件也不是唯一的,因为许多人可能没有电子邮件ID。因此,我使用以下逻辑创建字符串id 我使用get_or_insert插入实体。 虽然添加用户不会经常发生,但任何冲突都会是灾难性的,这意味着竞争的可能性较小,但其影响非常大。 我的问题是: PS:出于几个原因,我不能将所有用户实体保留在同一个实体组中。
-
分布式一致性 Raft 与 JRaft
分布式共识算法 (Consensus Algorithm) 如何理解分布式共识? 多个参与者 针对 某一件事 达成完全 一致 :一件事,一个结论 已达成一致的结论,不可推翻 有哪些分布式共识算法? Paxos:被认为是分布式共识算法的根本,其他都是其变种,但是 paxos 论文中只给出了单个提案的过程,并没有给出复制状态机中需要的 multi-paxos 的相关细节的描述,实现 paxos 具有很
-
副本一致性使用说明
简介 副本一致性提供主从副本在短时间内达到数据一致的功能。 具体请求流程如下: 1,客户端请求到主分片上 2,主分片同步请求到一定个数(replication-num)从分片上 3,主接收到一定个数(consensus-level)的从反馈ACK 4,数据落盘,返回客户端请求 注意 目前副本一致性功能只能在分片模式下运行。 由于成员变换的功能暂时不支持,不建议在主从关系建立之后更换新的从副本。 关
-
去SQL查询不一致
问题内容: 我在执行查询时遇到了一些非常奇怪的不一致,并且想知道是否有人知道为什么。 想象一下,我有一个结构定义如下: 以及具有以下列的MySQL表: 我想执行的查询: 从表WHERE A =“ a”中选择A,B,C,D 可以执行的第一种方式: 第二种可以执行的方式: 我遇到的不一致情况如下:以第一种方式执行查询时,Bfield的类型为。但是,第二次执行查询时为。 例如,当B为1时,就会出现这种结
-
Python中的SyntaxError不一致?
问题内容: 考虑以下两个片段: 。 在第二种情况下,将打印“第二个异常..”语句(捕获到异常),而在第一种情况下,则不会打印。 第一个异常(我们称其为“ SyntaxError1”)与第二个异常(“ SyntaxError2”)有什么不同吗? 有什么办法可以捕获SyntaxError1(从而抑制编译时错误)?在其中包装大量代码是不令人满意的;) 问题答案: 在第一种情况下,异常是由编译器,这是运行
-
不一致py-AFK命令
上面的代码正在运行。 我没有得到任何错误,但我也希望机器人显示他们是afk的原因,当他们提到。有人能帮忙吗?
-
卡桑德拉不一致
我们运行的cassandra集群有3个节点,复制因子为2。 我们的nodejs服务器是查询这个集群的唯一地方。 是否有其他任何地方的参数设置可能导致不一致的查询? cassandra v2.2.4 nodejs驱动程序v3.0.0 编辑-添加我正在做的事情的示例: 1)检查用户名是否被占用 2)创建用户
-
声纳报告不一致
我用两种方法对一个项目进行了声纳分析 > 作为maven的目标,使用(Java1.8)和(java 1.6) 两次扫描都产生了两份不同的报告。我不知道为什么会这样。 下面是我的开发环境配置 Maven: 3.0.5声纳方块: 3.0.1声纳转轮: 2.4日食:开普勒Java: 1.6
-
保护语句不一致
//在guard语句中首先执行let,然后执行bool检查,会导致编译错误 //先执行布尔检查,然后让它工作 上面的两种说法似乎与我的说法相同。为什么在第一种情况下它不起作用?
-
InvalidQueryException:此操作不支持一致性级别LOCAL_ONE。支持的一致性级别为:LOCAL_QUORUM
有人能帮助我如何通过datastax.cassandraconnector设置一致性吗?