《百度笔试机器学习》专题
-
机器学习:知道哪些传统机器学习模型
本文向大家介绍机器学习:知道哪些传统机器学习模型相关面试题,主要包含被问及机器学习:知道哪些传统机器学习模型时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 常见的机器学习算法: 1).回归算法:回归算法是试图采用对误差的衡量来探索变量之间的关系的一类算法。回归算法是统计机器学习的利器。 常见的回归算法包括:最小二乘法(Ordinary Least Square),逐步式回归(Stepwis
-
 百度笔试—9.13研发B卷(1:ac,2:ac,3:91%)
百度笔试—9.13研发B卷(1:ac,2:ac,3:91%)1. 统计baidu型字符串(AC) 2. 打怪(AC) 有n个怪物排成一排,第i个怪物的血量为ai。有两个技能可以打怪: 1.强力攻击,消耗1mp,对一只怪物造成1点伤害。 2.踏前斩,消耗5mp,对当前怪物造成1的伤害,同时剑气将波及后两个怪物,对下一个怪物造成 2点伤害,对下下个怪物造成3点伤害。 如果一个怪物受伤后血量小于等于0,则怪物死亡。死亡后怪物的尸体依然占据一个位置,会被踏前斩的剑
-
 百度 深度学习框架开发实习生(12.25)
百度 深度学习框架开发实习生(12.25)我太菜了,C++需要恶补才行,面试完基本上就知道自己寄,面试官特别好给我说了很多,也让我充分认识到自己的不足 如果是项目的话,会问你项目背景以及项目最终的实现结果等等 如果是自己学习的项目的话,会问你对这个项目的学习心得 最后问对C++对掌握程度 实现vector
-
笔试-度小满-180913
机器学习研发 选择 30,编程 2 火车站台 思路 求区间最大重叠数 暴力法(36%) n = int(input()) tmp = dict() mx = 0 for _ in range(n): x, y = list(map(int, input().split())) for i in range(x, y): if i in tmp:
-
 字节-机器学习平台-编排调度 一面
字节-机器学习平台-编排调度 一面记录一下字节处女面 2024.07.23 1. 自我介绍 2. 简历从上到下拷打(30 min) 3. os中进程调度方式 4. os中进程的元信息放置在哪里 5. docker中unionFS、namespace、cgroup 6. cgroup中如何在进程调度中体现 7. 介绍一个k8s中你最熟悉的组件(kube-scheduler) 8. 做题:二叉树两个节点的最短边 总体回答的一般般,项目
-
使用Scikit学习的机器学习
从sklearn加载流行数字数据集。数据集模块,并将其分配给可变数字。 分割数字。将数据分为两组,分别命名为X_train和X_test。还有,分割数字。目标分为两组Y_训练和Y_测试。 提示:使用sklearn中的训练测试分割方法。模型选择;将随机_状态设置为30;并进行分层抽样。使用默认参数,从X_序列集和Y_序列标签构建SVM分类器。将模型命名为svm_clf。 在测试数据集上评估模型的准确
-
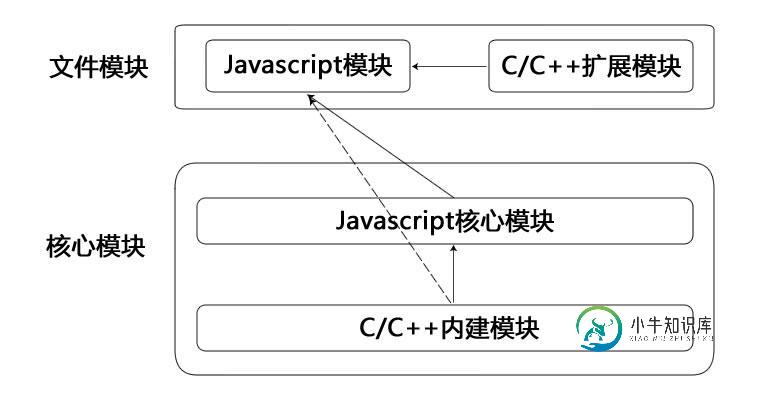 Node.js中的模块机制学习笔记
Node.js中的模块机制学习笔记本文向大家介绍Node.js中的模块机制学习笔记,包括了Node.js中的模块机制学习笔记的使用技巧和注意事项,需要的朋友参考一下 Javascript自诞生以来,曾经没有人拿它当做一门编程语言。在Web 1.0时代,这种脚本语言主要被用来做表单验证和网页特效。直到Web 2.0时代,前端工程师利用它大大提升了网页上的用户体验,JS才被广泛重视起来。在JS逐渐流行的过程中,它大致经历了工具类库、组
-
 Coursera 深度学习教程中文笔记
Coursera 深度学习教程中文笔记这些课程专为已有一定基础(基本的编程知识,熟悉 Python、对机器学习有基本了解),想要尝试进入人工智能领域的计算机专业人士准备。介绍显示:深度学习是科技业最热门的技能之一,本课程将帮你掌握深度学习。 在这5堂课中,学生将可以学习到深度学习的基础,学会构建神经网络,并用在包括吴恩达本人在内的多位业界顶尖专家指导下创建自己的机器学习项目。Deep Learning Specialization对卷
-
 百度(23届秋招)前端笔经
百度(23届秋招)前端笔经9.13 19:00 笔试 没投正式批,百度是提前批没过的自动转入正式批流程了 平台:牛客;时间:120min;总分120min 题型:单选14*3分=42分;不定项6*3分=18分;编程10分+15分+15分=40分 最近笔试太多了,选择题记不太清了,简单列一下知识点 一、单选题 1、关于cookie和session? A.关闭浏览器后会话cookie会存在一段时间 B.ses
-
 百度2024届暑期实习后台开发笔试题-Go解法
百度2024届暑期实习后台开发笔试题-Go解法第一题 题目描述 给定一个字符串,判断是否可以排列为“Baidu” 输入描述 输入一个字符串 输出描述 如果能排列为“Baidu”,输出“Yes”,否则输出“No” Go代码 第二题 题目描述 要求构造一个包含n个回文子串的仅由red三个字母组成的字符串。 题目分析 这道题当时在纸上画了画,想到一个思路,首先只用r填满字符串。一个r包含一个回文串,rr包含3个回文串,rrr包含6个回文串... 说
-
机器学习:使用Python
Scikit-learn (http://scikit-learn.org/) 是一个机器学习领域的开源套件。整个专案起始于 2007年由David Cournapeau所执行的Google Summer of Code 计画。而2010年之后,则由法国国家资讯暨自动化研究院(INRIA, http://www.inria.fr) 继续主导及后续的支持及开发。近几年(2013-2015)则由 IN
-
KStreams+Spark Streaming+机器学习
但我在Kstreams那边。现在我糊涂了!!! 问题: 1。Spark流媒体和Kafka流媒体有什么区别? 2。我怎样才能把KStreams+Spark Streaming+机器学习结合起来? 3。我的想法是连续训练测试数据,而不是批量训练。
-
机器学习框架:TensorFlow
有关TensorFlow与其他框架的详细对比可以阅读: https://zhuanlan.zhihu.com/p/25547838 01 TensorFlow的编程模式 编程模式分为两种:命令式编程与符号式编程 前者是我们常用的C++,java等语言的编程风格如下 命令式编程看起来逻辑非常清晰,易于理解。而符号式编程涉及较多的嵌入和优化,如下 执行相同的计算时c,d可以共用内存,使用Tenso
-
机器学习:多分类
每次将一个类别作为正类,其余类别作为负类。此时共有(N个分类器)。在测试的时候若仅有一个分类器预测为正类,则对应的类别标记为最终的分类结果。 【例】当有4个类别的时候,每次把其中一个类别作为正类别,其余作为负类别,共有4种组合,对于这4中组合进行分类器的训练,我们可以得到4个分类器。对于测试样本,放进4个分类器进行预测,仅有一个分类器预测为正类,于是取这个分类器的结果作为预测结果,分类器2预测的结果是类别2,于是这个样本便属于类别
-
 美团机器学习岗
美团机器学习岗一面4.3 问了下GNN相关的知识(由于我是graph背景) 以及机器学习的基础知识 二面4.10 问了下实习的项目以及之前做过一深度学习相关的东西 特别细 #你收到了团子的OC了吗# offer4.17