《数据挖掘工程师面经》专题
-
 百度 数据研发工程师 面经
百度 数据研发工程师 面经一面: 无自我介绍环节,直接开问 1、聊实习项目,很细,聊了好久 2、yarn任务提交流程 3、spark的stage切分原理 4、spark任务提交流程 5、对比mr和spark,为什么都用spark 6、谈谈对hudi的理解 7、kafka的负载均衡原理 8、两道算法题,字符串相关的 9、反问 ps.好多过程不记得了 二面: 三个模块 开发 大数据 算法 不想回忆了,直接自闭,一点都不会 但是
-
 TCL实业 大数据工程师 面经
TCL实业 大数据工程师 面经9.11 一面 35min: 1.自我介绍 2.专业介绍 3.Mysql索引 4.Mysql事务并发导致的问题 5.Mysql两种引擎的对比 6.Hadoop运行模式 7.job tracker 作用 8.Hdfs小文件问题 9.Hadoop调度器 10.Hadoop脑裂出现的原因 11.Kafka 怎样保证不丢数据 12.Flink task和subtask 的区别 13.并行度和slot的关系
-
 数据分析建模工程师面经
数据分析建模工程师面经1.自我介绍 2.实习项目拷打 3.场景题,有一万条数据,但有一个类只有条数据,训练时要注意什么,我:构造数据;增加查全率。面试官:从模型方面讲讲。我:加入正则化项。面试官:损失函数的权重。 4.一个项目,反例比较少,选择一个模型评估方法。没答上来。面试官说AUC曲线,让我说说原因。也猜到了要答AUC曲线跟数量无关,但是有点印像,画曲线的时候是要使用正例反例数量的,不敢说话,疯狂道歉。 5.SQL
-
 美团 数据研发工程师 面经
美团 数据研发工程师 面经到店业务 有点久远一直忘了写,就记得这么多 一面: 1、自我介绍 2、比赛中遇到的难点 3、实习中做的项目,聊项目细节 (大部分时间都在问这个) 我好像很多面经都这么简略的写,这次写细点儿哈,里面涉及到的一些知识点,具体项目就不聊了 数仓模型设计方法 数据质量如何判断 如何保障下游查出时间 对于重要程度不同的任务如何合理分配资源 dwd层建模方法,考虑哪些东西 spark任务调参逻辑和常用参数 c
-
 metaApp 数据研发工程师 面试
metaApp 数据研发工程师 面试一面难绷,上来就问hashmap 我说先自我介绍吧,面试官说啊对对对 介绍完了,开始问项目,问实习, 全程听完之后,好,下一个问题哈,瞟一眼出题,然后八股,问了十几分钟 我也懒得答太详细了 就给我出题,反转链表 精彩部分来了,他不知道哪里把题目发给我,也不知道让我在哪里写,我说不用发题目给我,我在聊天框写,写了一会发现格式难调,他就让我口述,口述完之后,他就说你有什么想问的吗,我说我没什么想问的,
-
 minimax数据引擎工程师一面
minimax数据引擎工程师一面秋招第一次面试,以此留作纪念 1. 背景情况了解 2. 实验室项目介绍,cv项目里如何评估准确率。 3. 问最了解的经历介绍,没说实习,说了电商数仓。 4. 数仓如何分层。 5. ods,dwd,aws层,为什么要分这3层。 6. redis主要用的数据类型。项目里是怎么设计的。sortset主要用在什么场景。并发量多大 7. 缓存击穿 8. kafka如何保证生产者端不重复和不丢失。 9. my
-
 百度-大数据工程师一面
百度-大数据工程师一面#百度#面试官很好,总体感觉问的比较简单,但是好久不看八股感觉很多都忘记...理解还是比较浅层,一些实战方面的内容还比较欠缺...要努力了!!!
-
 携程数据仓库工程师一面凉经
携程数据仓库工程师一面凉经1 . 自我介绍 2.面试官,你们有教过大数据技术吗?应该没教过吧? 2.spark为什么比MapReduce快 3.spark算子链 4.问项目 5.Sql调优 6数据倾斜 6.一道sql题,思路,之前笔试做过,但只过了2/3 7.有接触过flink实时计算框架吗? 8.MySQL索引是越多越好吗?索引类型?什么时候用聚簇索引,什么时候用非聚簇索引 9.反问。 面试官挺好的,是我太菜了,一些没答
-
 联想 - 数据分析工程师一面面经
联想 - 数据分析工程师一面面经8月31日一面,两位面试官,2V1,时长约1小时,两位面试官都很温和,整体的面试体验感觉很好,面试氛围超好 自我介绍 针对所修专业开始提问 你的专业做数据分析相比于统计学/数学有什么特殊之处? 你的专业做数据分析有什么优势? 介绍其中一段实习经历 实习中使用到的一个预测模型处理的数据大约有多少条记录?时间跨度有多长?用的训练集占多少? 对于这个项目,当时是怎么分工的? 有遇到什么问题,是怎么解决的
-
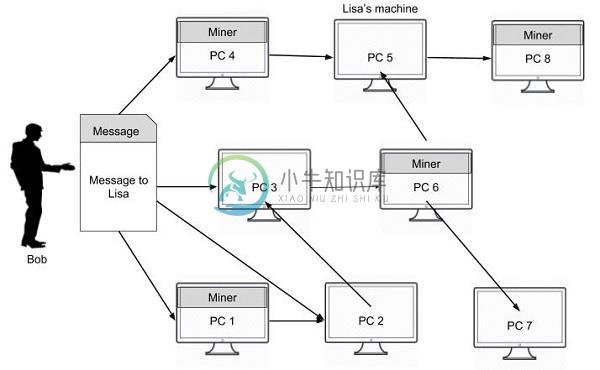 比特币矿挖掘
比特币矿挖掘主要内容:比特币挖掘,比特币矿工的角色,比特币区块链是如何建造的?要了解比特币矿工的作用,我们首先了解比特币挖掘。 比特币挖掘 比特币挖掘是将交易记录添加到比特币过去交易的公共分类账的过程。过去交易的分类账称为区块链,因为它是一系列区块。比特币挖掘用于保护和验证交易到网络的其余部分。 示例 当Bob为Lisa创建购买请求时,他不会单独将其发送给Lisa。请求消息在他所连接的整个网络上广播。Bob的网络以图像形式描绘。 消息将传递到所有连接的节点(计算机)。图中的
-
挖掘 FreeRADIUS 的 man page
下面的命令可以被用来指导首先决定哪些FreeRADIUS包被安装了和临时决定包中包含哪些文件. dpkg系统 显示所有FreeRADIUS安装的包: $> dpkg -l | grep radius 使用
-
 值得买 数据开发工程师 面经
值得买 数据开发工程师 面经一面: 全程围绕简历展开问 1、自我介绍 2、聊聊印象最深刻的一次竞赛经历 (简历写了) 针对这个竞赛内容抠细节 3、问实习经历中做的事情 挑了其中几个细问 这个答了好久,从事情的背景,到思考链路 4、一道算法题 一个数组先升序再降序,求最大值 5、hadoop数据的存储格式 6、spark里job、stage、task的概念 7、问flink、hudi这个有没有经验 因为简历上写了,回答说学习的
-
 知乎 大数据开发工程师 面经
知乎 大数据开发工程师 面经一面: 感觉一上来就是主管面,主业务面,考验业务能力和沟通能力 介绍下专业的课程,说说最喜欢哪一门,为什么 直接问实习经历 实习中的项目,扣细节(大部分时间都在问这个) 在同程做了什么业务 广告业务数仓负责哪些东西 广告投放的指标,如曝光、转化等等 广告有哪些类型 聊聊广告投放流程,投前、投中、投后 投中的过程每一轮具体的事情 对比hive和spark 为什么业界都用spark不用mr了 聊聊fl
-
 百度-大数据研发工程师面经
百度-大数据研发工程师面经一面 redis: RDB和AOF的区别 AOF中记录的是什么,RDB中记录了什么 过期数据的删除策略 使用这些删除策略可能会出现哪些问题 定期删除是所有数据删除吗 内存淘汰机制 allkeys详细说说 redis使用场景 redis和memcached有什么区别 为什么用单线程不用多线程 clickhouse(实习里用的主要是这个): 简单介绍一下clickhouse,说说为什么用这个 说一下R
-
Web抓取,屏幕抓取,数据挖掘技巧?
问题内容: 我正在做一个项目,我需要做很多屏幕抓取工作,以尽可能快地获取大量数据。我想知道是否有人知道任何好的API或资源来帮助我。 顺便说一下,我正在使用Java。 到目前为止,这是我的工作流程: 连接到网站(使用来自Apache的HTTPComponents) 网站包含一个带有一堆我需要访问的链接的部分(使用内置的Java HTML解析器来弄清楚我需要访问的所有链接是什么,这很烦人且凌乱的代码