《强化学习》专题
-
 iOS指纹验证TouchID应用学习教程
iOS指纹验证TouchID应用学习教程本文向大家介绍iOS指纹验证TouchID应用学习教程,包括了iOS指纹验证TouchID应用学习教程的使用技巧和注意事项,需要的朋友参考一下 指纹验证这个功能现在在一些app中经常常见,常常与数字解锁,手势解锁联合起来使用。前几天接到说实现一个指纹验证的功能,捣鼓了挺久,然后今天,我就简单的介绍下指纹验证,会做个简单的demo实现一下基本的功能。 支持系统和机型:iOS系统的指纹识别功能最低支
-
Swift学习教程之SQLite的基础使用
本文向大家介绍Swift学习教程之SQLite的基础使用,包括了Swift学习教程之SQLite的基础使用的使用技巧和注意事项,需要的朋友参考一下 前言 在我们的日常开发中,经常会遇到用户断网或者网络较慢的情况,这样用户在一进入页面的时候会显示空白的页面,那么如何避免没网显示空白页面的尴尬呢?答案就是:先在网络好的时候缓存一部分数据,这样当下次网络情况不好的时候,至少用户可以先看到之前缓存的内容,
-
java基础学习笔记之类加载器
本文向大家介绍java基础学习笔记之类加载器,包括了java基础学习笔记之类加载器的使用技巧和注意事项,需要的朋友参考一下 类加载器 java类加载器就是在运行时在JVM中动态地加载所需的类,java类加载器基于三个机制:委托,可见,单一。 把classpath下的那些.class文件加载进内存,处理后成为字节码,这些工作是类加载器做的。 委托机制指的是将加载类的请求传递给父加载器,如果父加载器找
-
 vue mint-ui学习笔记之picker的使用
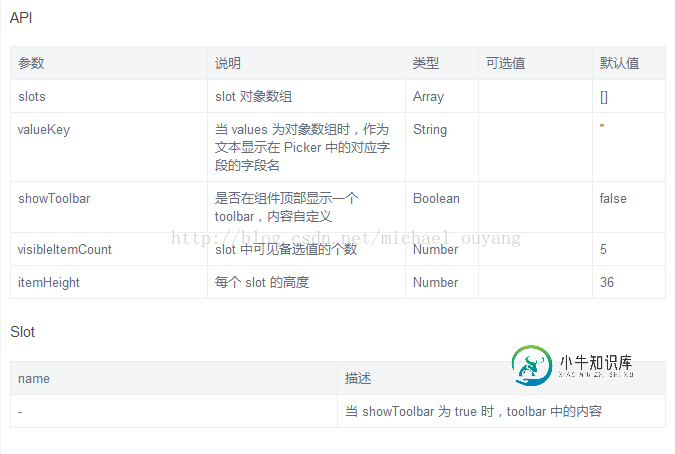
vue mint-ui学习笔记之picker的使用本文向大家介绍vue mint-ui学习笔记之picker的使用,包括了vue mint-ui学习笔记之picker的使用的使用技巧和注意事项,需要的朋友参考一下 本文介绍了vue mint-ui picker的使用,分享给大家,也给自己留个学习笔记 Picker的使用 API 示例一:picker的简单使用 xxx.vue: show: picker显示出来了 分析: pincker的显示,会在
-
 vue学习之Vue-Router用法实例分析
vue学习之Vue-Router用法实例分析本文向大家介绍vue学习之Vue-Router用法实例分析,包括了vue学习之Vue-Router用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了vue学习之Vue-Router用法。分享给大家供大家参考,具体如下: Vue-router就像一个路由器,将组件(components)映射到路由(routes)后,通过点击<router-link>它可以在<router-view
-
 python学习教程之Numpy和Pandas的使用
python学习教程之Numpy和Pandas的使用本文向大家介绍python学习教程之Numpy和Pandas的使用,包括了python学习教程之Numpy和Pandas的使用的使用技巧和注意事项,需要的朋友参考一下 前言 本文主要给大家介绍了关于python中Numpy和Pandas使用的相关资料,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧。 它们是什么? NumPy是Python语言的一个扩充程序库。支持高级大量的维度数组
-
 Bootstrap路径导航与分页学习使用
Bootstrap路径导航与分页学习使用本文向大家介绍Bootstrap路径导航与分页学习使用,包括了Bootstrap路径导航与分页学习使用的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Bootstrap路径导航与分页的具体代码,供大家参考,具体内容如下 效果图: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
 javascript Promise简单学习使用方法小结
javascript Promise简单学习使用方法小结本文向大家介绍javascript Promise简单学习使用方法小结,包括了javascript Promise简单学习使用方法小结的使用技巧和注意事项,需要的朋友参考一下 解决回调函数嵌套太深,并行逻辑必须串行执行,一个Promise代表一个异步操作的最终结果,跟Promise交互的主要方式是通过他的then()方法来注册回调函数,去接收Promise的最终结果值 Promise相关的协议有P
-
 Bootstrap学习笔记之css样式设计(2)
Bootstrap学习笔记之css样式设计(2)本文向大家介绍Bootstrap学习笔记之css样式设计(2),包括了Bootstrap学习笔记之css样式设计(2)的使用技巧和注意事项,需要的朋友参考一下 首先,很感谢各位朋友对我的支持,关于bootstrap的学习总结,我会持续更新,如果有写的不对的地方,麻烦各位给我指正出来哈。关于上篇文章,固定布局和流式布局很关键,如果还不太清楚的可以再看看我写的:Bootstrap学习笔记之css样式设
-
 Bootstrap学习笔记之css样式设计(1)
Bootstrap学习笔记之css样式设计(1)本文向大家介绍Bootstrap学习笔记之css样式设计(1),包括了Bootstrap学习笔记之css样式设计(1)的使用技巧和注意事项,需要的朋友参考一下 由于项目需要,所以打算好好学习下bootstrap框架,之前了解一点,框架总体不难,但涉及到的东西还是很多,想要熟练掌握它,还是要多练练。 一、bootstrap是什么? bs是什么? 即前端页面搭建的标准化框架工具,已经写好了css.js
-
我的Node.js学习之路(四)--单元测试
本文向大家介绍我的Node.js学习之路(四)--单元测试,包括了我的Node.js学习之路(四)--单元测试的使用技巧和注意事项,需要的朋友参考一下 通过NPM安装: npm install nodeunit -g 支持命令行,浏览器运行. 各种断言。 在node.js下模块化对于方法导出exports, 如果是对象导出module.exports,模块儿是单元测试的基础,看下面的nod
-
Scikit中跨多列的标签编码-学习
我正在尝试使用Scikit-Learn的来编码字符串标签的pandas。由于dataframe有许多(50+)列,我希望避免为每个列创建对象;我宁愿只有一个大的对象,它可以跨我的所有数据列工作。 将整个抛入会产生以下错误。请记住,我在这里使用的是虚拟数据;实际上,我正在处理大约50列字符串标记的数据,因此需要一个不引用任何列名称的解决方案。 回溯(最近一次调用):文件“”,第1行,在文件“/use
-
Azure机器学习(预览)到客户洞察
我正在尝试将MS Dynamics Customer Insights(CI)与我在新的Azure机器学习(designer)中构建的模型集成。目前,我看到CI和Azure机器学习工作室(classic)之间只有一个集成。 我已经在新Azure机器学习中的web服务(REST)后面部署了我的模型,但是它在CI中没有得到重视。但是,我能够使用Python脚本从API中评分/生成预测。 请推荐一种集成
-
开始学习节点群集获取错误
工人11056是在线工人11057是在线工人11058是在线工人11059是在线事件。JS:141抛ER;//未处理的“错误”事件^ 错误:在object.exports._errnoException(util.js:870:11)在exports._exceptionWithHostPort(util.js:893:20)在cb(net.js:1302:16)在rr(cluster.js:59
-
weka中的机器学习分类与预测
我对机器学习很陌生。对不起,如果我的英语有任何错误。 我使用weka J48分类来预测是真是假。我有将近999K的训练套件,我用来训练模型。我使用了3倍的交叉验证方法来训练模型,使我的准确率达到了约84%。 现在在存储模型之后。我试着在50k数据集上测试它。结果非常糟糕,其中50%是不匹配的。我有11个属性,包括名词和数字字段。 我不知道为什么会这样。 我有两个问题。 我怎样训练才能在测试集中表现