《中邮消费金融有限公司》专题
-
熊猫和雅虎金融如何获得“美元兑日元”(汇率)?
我正在学习和使用熊猫和蟒蛇。 今天,我想制作一张外汇汇率表,但我在获取美元兑日元的价格时遇到了麻烦。 当我得到‘欧元/美元’的价格时,我会这样编码。 它起作用了。 但是当我写的时候 错误消息如下所示: ---------------------------------------------------------------------------()中的IOError回溯(最近一次调用)---
-
 京东科技金融策略增长数分-24校招1面经
京东科技金融策略增长数分-24校招1面经开场互相自我介绍。 首先是10min盘问实习中的分析。主要围绕1、背景是什么;2、为什么这个问题需要分析; 3、发现了什么问题以及这个发现怎么去推动业务;几点展开询问。问的不深。还问了一些边角问题比如策略实施谁排版、和搜推团队如何合作、你觉得你们的业务有什么可以改进的点。主要考察业务了解。 接下来是案例题一整套。接下来让你说一个你常用的软件。分析他和竞品之间的优劣势,讲讲你认为怎么该从竞品中胜出。
-
 8月5号腾讯金融科技CDG提前批测开一面
8月5号腾讯金融科技CDG提前批测开一面bg酸非本,2段实习 秋招第一面,拿腾讯练手😂😋😋 1. 自我介绍 2. 我看你简历上也有2个自己开发的项目,你觉得哪个更复杂一些?难度更高一点? 3. 详细说一下你是怎么设计的,以及架构是怎么样子 4. 后台这一块,你的登录做了什么处理? 5. 使用的是已有的技术,没有再增加什么吗? 6. jwt有做什么校验呢? 7. 用户传用户名和密码是用什么协议? 8. 会不会有密码泄漏的风险? 9.
-
ABP公共结构 - 邮件发送(MailKit集成)
2.8 ABP公共结构 - 邮件发送(MailKit集成) 2.8.1 简介 几乎所有的应用都有一个发送电子邮件的功能。ABP提供了一个基本的基础设施,它可以简单的发送邮件,并且将邮件服务的配置从发送邮件的功能中分离了出来。 2.8.2 IEmailSender IEmailSender 是一个邮件发送服务接口,使用它你不需要知道详细信息就可以简单的发送邮件。如下所示: public class
-
FCM免费版本使用限制[已关闭]
我正在考虑FCM来推送消息,并拥有相当大的用户群,一周内有100万-200万用户使用。我有以下关于免费FCM用法的查询 > 每天/周/月调用firebase的次数,在免费FCM使用中是不是不受限制的? 我可以对我的FCM服务器帐户进行的并发调用有限制吗? 数据有效载荷能否超过4KB? 可以创建的设备组是否有限制?
-
香港费率可以限制每个endpoint吗?
我可以配置Kong的速率限制插件,以便它在给定API中对每个endpoint实施限制,如下所示: 但是,我想为每个endpoint配置不同的速率限制。例如,我想允许: 使用每IP每秒5个请求的速率限制 这对香港有可能吗?我看到了一个与此相关的开放问题,但是否有任何解决方法?
-
 大唐移动通信设备有限公司通信测试工程师面经
大唐移动通信设备有限公司通信测试工程师面经3个人一起面试、两位面试官、先是挨个做自我介绍、没有时间限制、然后面试官开始提问、同一个问题三个人依次回答、大部分问题都是围绕业务开展的,还有因为本人跨专业,所以被问到为什么不去医药公司,希望做什么职位等等。最后提问结束后,面试官叫我们提问,我们问她们回答,然后面试结束,等待面试结果。 问题整理: 1、为什么不做自己的医学方面的工作? 2、为什么要报? 3、接受岗位调整嘛? 4、你们认为培训生是做
-
如何从Apache Nifi中最后提交的偏移量读取消费者中的Kafka消息?
我已经开始让我的制作人向Kafka发送数据,也让我的消费者提取相同的数据。当我在ApacheNIFI中使用ConsumerKafka处理器(kafka版本1.0)时,我脑海中很少有与kafka consumer相关的查询。 Q.1)当我第一次启动ConsumeKafka处理器时,我如何从开始和当前消息中读取消息? 问题2)以及在Kafka消费者关闭的情况下,如何在最后一条消费信息之后阅读信息? 在
-
詹金斯扩展电子邮件通知-电子邮件内容作为附件
使用Jenkins1.499和版本2.25的Jenkins电子邮件扩展插件。当电子邮件被发送时,电子邮件的内容显示为通知的附件,而不是在电子邮件的正文中。事实上,邮件正文是空白的。更改电子邮件的内容类型没有任何效果。我们使用Exchange/Outlook,这可能是问题所在吗?有什么想法可以在邮件的正文中获得邮件的内容吗?
-
什么是访问令牌与访问令牌秘密和消费者密钥与消费者秘密
我使用Oauth已经有一段时间了,但从来没有完全确定这四个术语之间的区别(以及每个术语的功能)。我经常看到(例如在Twitter公共API中) 消费者秘密: 和 但我从来都不知道他们到底在干什么。我知道Oauth有能力授权应用程序(让它们代表用户行事),但我不理解这四个授权条款之间的关系,希望得到解释。 基本上,我不确定访问令牌或令牌密钥是如何生成的,它们存储在哪里,以及它们之间或与使用者密钥和密
-
生产者/消费者:一个生产者,多个消费者,每个人处理相同的数据
我有一个生产者/消费者场景,我不希望一个生产者交付产品,多个消费者消费这些产品。然而,常见的情况是,交付的产品只被一个消费者消费,而其他消费者从未看到过这个特定的产品。我不想实现的是,一个产品被每个消费者消费一次,而没有任何形式的阻碍。 我的第一个想法是使用多个BlockingQueue,每个消费者使用一个,并使生产者将每个产品按顺序放入所有可用的BlockingQueues中。但是,如果其中一个
-
我可以让一个组的所有消费者都使用来自Kafka主题所有分区的消息吗?
假设在Kafka中,我有一个主题“A”的4个分区,并且我有20个消费者组“AC”的消费者。我不需要任何排序,但我想通过扩展我的消费者实例来更快地处理消息。请注意,所有消息都是独立的,可以独立处理。 我查看了消费者配置分区。分配策略,但不确定是否可以根据消息可用性实现消费者到分区的动态分配。
-
GROUP_CONCAT有限制
问题内容: 我有表-s在许多一对多的关系与-s 目标是通过单个查询列出球员及其“前三项技能”。 小提琴 查询: 正如您在小提琴中看到的那样,查询结果仅缺少3个技能的限制。 我尝试了子查询的几种变体..联接等等,但是没有任何效果。 问题答案: 一种比较古怪的方法是对结果进行后处理: 当然,这是假设您的技能名称不包含逗号,并且数量很少。 小提琴 一个功能请求用于支持一个明确的条款是可惜还是没有得到解决
-
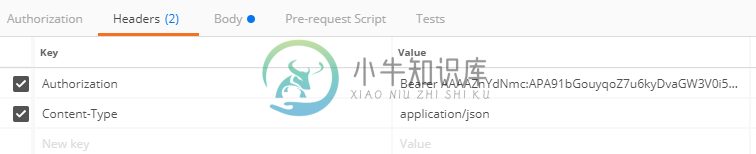 Firebase云消息传送-通过邮递员发送消息
Firebase云消息传送-通过邮递员发送消息我正在尝试为Web设置Firebase云消息传递。我成功地对其进行了正确初始化并获得了令牌: manifest.json与gcm_sender_id 我可以看到我在控制台中得到令牌,所以我试图验证它,并通过邮递员发送我的第一个通知-这里是留档。 发布网址:https://fcm.googleapis.com/v1/projects/PROJECTID/messages:发送授权:无授权 标题 Bo
-
 .NET微信公众号开发之公众号消息处理
.NET微信公众号开发之公众号消息处理本文向大家介绍.NET微信公众号开发之公众号消息处理,包括了.NET微信公众号开发之公众号消息处理的使用技巧和注意事项,需要的朋友参考一下 一.前言 微信公众平台的消息处理还是比较完善的,有最基本的文本消息,到图文消息,到图片消息,语音消息,视频消息,音乐消息其基本原理都是一样的,只不过所post的xml数据有所差别,在处理消息之前,我们要认真阅读,官方给我们的文档:http://mp.wei