《中邮消费金融有限公司》专题
-
spring-cloud-stream kafka消费者并发
使用Spring-Cloud-Stream的kafka绑定器,如何配置并发消息消费者(在单个消费者jvm中)?如果我没有理解错的话,在使用kafka时并发使用消息需要分区,但是s-c-s文档指出,要使用分区,您需要通过partitionKeyExpression或PartitionKeyExtractorClass在生成器中指定分区选择。Kafka博士提到循环分区。 s-c-s文档根本没有提到sp
-
Kafka只流一次消费群体
当我只打开一次处理时,我会得到以下错误。注意:我们的应用程序非常安全,我们只允许Kafka用户和消费者访问他们明确需要的资源。 只有一次处理kafka流是否在所有流任务中使用每个流任务的消费者组而不是消费者组?
-
OSGI:如何更新消费者包
我一直在试图理解一种奇怪的OSGI行为。希望有人能解释一下。这是我的设置 1)使用eclipse\plugins\org.eclipse.osgi_3.7.0.v20110613.jar 2) 我有一个导出服务的包(HelloworldService) 它在activator中注册服务 3) 我有一个“消费者”捆绑包,通过ServiceTracker使用该服务 现在,当我将这两个罐部署到OSGI(
-
Kafka--不同速度的消费者
我对Kafka有一个概念上的问题。 我们有许多机器在一个主题上充当消费者,有许多分区。这些机器运行在不同的硬件设置上,将会有比其他机器具有更高吞吐量的用户。 现在,使用者和一个或多个分区之间存在直接的相关性。
-
Kafka主题的多重消费者
然而,当在我的环境中测试此示例时,我得到了一个异常。
-
Kafka消费者再平衡算法
有人能告诉我Kafka消费者的再平衡算法是什么吗?我想了解分区计数和消费者线程是如何影响这一点的。 非常感谢。
-
春云流生产消费同题
我试图改变生产者和消费者配置的顺序,但没有帮助。 编辑:我已经添加了完整的application.yml。当我第一次引导服务时,这个主题在Kafka中是不存在的。 它感觉在生产者和消费者配置之间有冲突,我认为它说有3个分区的原因是消费者中的并发性是3,所以它首先创建有3个分区的主题,然后当它移动到生产者配置时,它不调整分区计数。
-
Apache Flume:kafka.consumer.消费者时间异常
我正在尝试使用Apache Flume构建管道:Spooldir- 事件毫无问题地进入kafka主题,我可以使用kafkacat请求看到它们。但是kafka通道无法通过接收器将文件写入hdfs。错误是: 等待来自 Kafka 的数据时超时 完整日志: 2016-02-26 18:25:17,125 (SinkRunner-PollingRunner-DefaultSinkProcessor-Sen
-
Kafka消费者Vs阿帕奇·Flink
我做了一个poc,其中我使用spark流从Kafka读取数据。但我们的组织要么使用ApacheFlink,要么使用Kafka消费者从ApacheKafka读取数据,作为标准流程。所以我需要用Kafka消费者或ApacheFlink替换Kafka流媒体。在我的应用程序用例中,我需要从kafka读取数据,过滤json数据并将字段放入cassandra中,因此建议使用kafka consumer而不是f
-
pact-jvm消费者协议测试
我是新来的。我的项目是Java项目。我通读了pact文档,找到了github项目https://github.com/dius/pact-jvm/tree/master/pact-jvm-consumer-junit,我将其导入到eclipse IDE中。我被困在这里了。1.首先运行哪个测试。ExampleJavaConsumerPactRuleTest还是ExampleJavaConsumerP
-
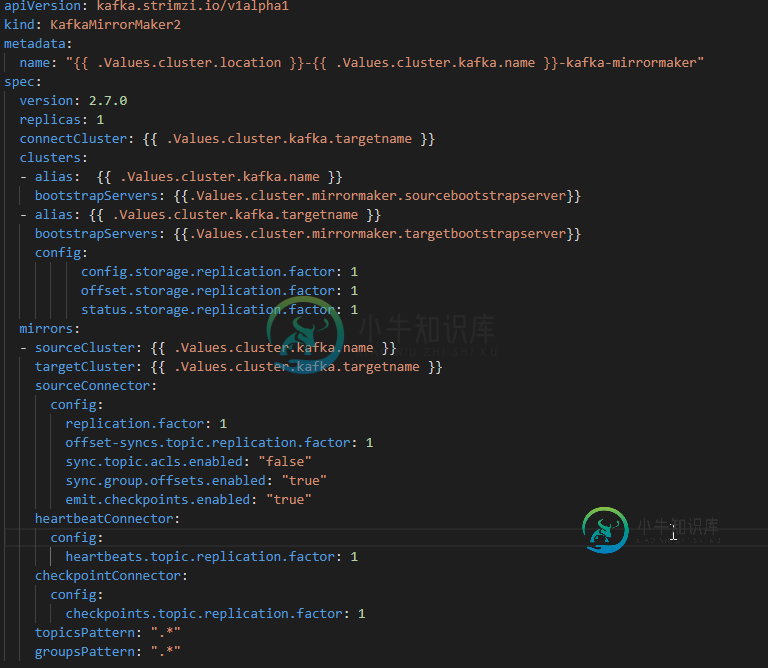 KafkaMirrorMaker2自动消费偏移同步
KafkaMirrorMaker2自动消费偏移同步我正在使用镜像制作器 2 进行灾难恢复。 Kafka 2.7 应支持自动消费者偏移同步 下面是我正在使用的yaml文件(我使用strimzi来创建它) 所有源群集主题都在目标群集中复制。还有…检查点。内部主题是在包含所有同步的源集群偏移量的目标集群中创建的,但我没有看到这些偏移量被转换为目标集群_consumer_offsets主题,这意味着当我在目标集群中启动消费者(同一消费者组)时,它将从一开
-
Kafka Rest代理消费者创建
假设我有一个服务,它通过kafka-rest-proxy来消费消息,并且总是在同一个消费者组上。我们还可以说,它正在消耗一个有一个分区的主题。当服务启动时,它在kafka-rest-proxy中创建一个新的使用者,并使用生成的使用者url,直到服务关闭。当服务重新启动时,它将在kafka-rest-proxy中创建一个新的消费者,并使用新的url(和新的消费者)进行消费。 > 因为kafka每个分
-
apache kafka消费者退避策略
当对骆驼使用Kafka组件时,从Kafka消费时有两种方法可以重试: null org.apache.kafka.clients.Consumer.internals.AbstractCoordinator[Consumer ClientID=Consumer-1,GroupID=2862121D-DDC9-4111-A96A-41BA376C0143]此成员将离开组,因为使用者轮询超时已过期。这
-
 Kafka消费者获取键值对
Kafka消费者获取键值对我目前正在与Kafka和Flink合作,我有kafka在我的本地PC上运行,我创建了一个正在消费的主题。 桌面\kafka\bin\windows 有没有办法进一步了解这条消息的细节?比如说时间?钥匙我查看了Kafka的文档,但没有找到关于这个主题的内容
-
Kafka-主题、分区和消费者
假设我有一个名为“MyTopic”的主题,它有3个分区P0、P1和P2。这些分区中的每一个都有一个leader,并且本主题的数据(消息)分布在这些分区中。 1.Producer将始终根据代理上的负载以循环方式写到分区的领导者。对吗? 2.制作人如何认识隔断的首领?