《吉利》专题
-
后期利用简介
现在我们已经学会了如何访问目标机器。在本节中,我们将学习在获得计算机访问权限后可以完成的许多事情。无论我们如何获得对目标计算机的访问权限,我们都会关注它们。 在上一节中,当我们从目标获得反向Meterpreter会话时,我们总是停下来。但在本节中,我们将从Meterpreter会话开始。我们将学习,获得访问后我们可以做些什么。我们将讨论如何保持对目标计算机的访问,即使目标重新启动计算机或用户卸载易
-
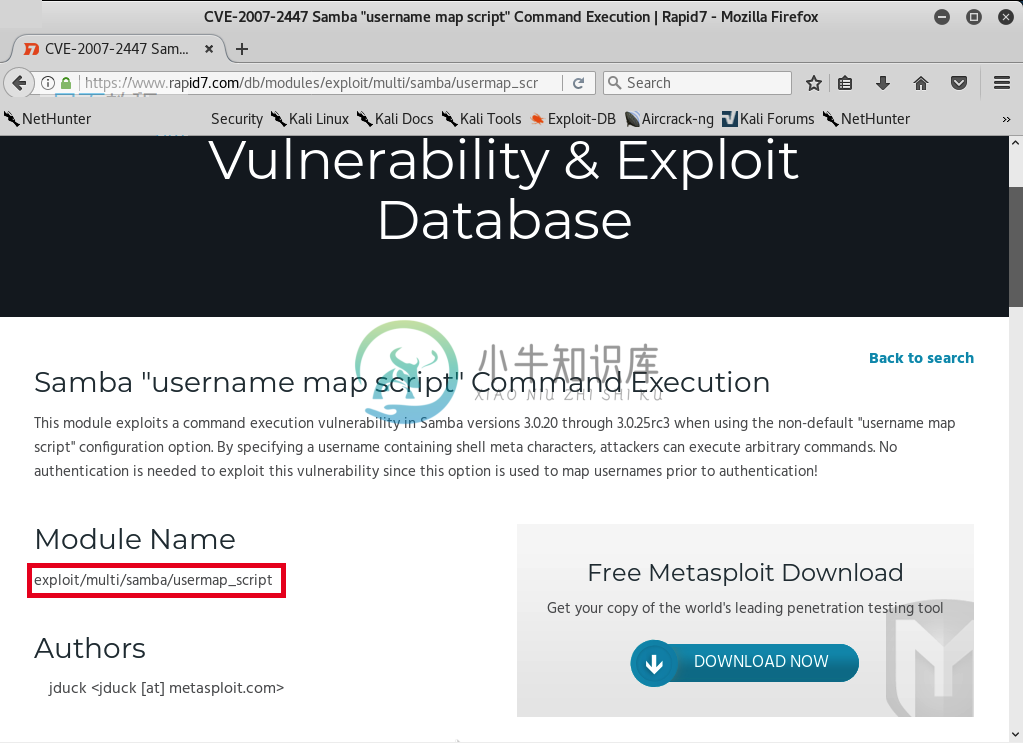 利用代码执行漏洞
利用代码执行漏洞在本节中,我们将更加深入地了解Metasploit,我们将看到如何使用它来利用某个服务中存在的漏洞。这是一个代码执行漏洞,可以让我们完全访问目标计算机。回到我们在Nmap中的结果,我们将做与以前一样的事情。复制服务名称,看看它是否有任何漏洞。现在我们查看端口139,它的Samba服务器版本为,就像上一节一样,在Google搜索Samba 3.X漏洞。我们将看到有很多结果,但主要是关于Rapid7方
-
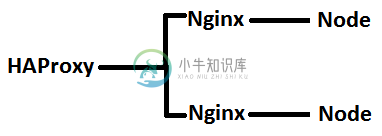 Nginx和Node.js-充分利用服务器
Nginx和Node.js-充分利用服务器出于实验/学习目的(假设我的应用程序有很多持久/并发流量),我有一个运行docker的虚拟机。对于docker,我有以下设置: 所有东西都有自己的容器,并与端口通信。我试图模拟两个不同的服务器(Nginx),通过HAProxy实现负载平衡。 现在它工作得很好,但是据我所知,节点仍然只在单线程中运行。 Nginx包含的唯一配置是作为节点的反向代理(其他所有配置都是默认配置)。每个Nginx服务器只处
-
利用Docker主机名实现两个微服务之间的通信
它现在是如何工作的: 微服务X用静态ip向微服务Y发出REST API请求 我试图通过在docker-compose中创建一个已使用的定义网络来实现这一点: 例如,我可以从容器X ping到容器Y,但不能Curl。我该如何解决这个问题,或者这不是实现我想要的最好的方法。
-
利斯科夫替换原则和PHP接口
以下代码是否直接违反了Liskov替换原则: 子类不应破坏父类的类型定义。 结果如下: 致命错误:b::baz(Foo $foo)的声明必须与a::baz(Baz $baz)兼容
-
利用Java实现环面平面上的包含/排除
我写了一个程序来解决以下问题: 在一个环形平面上实现扩散限制聚集模拟,其中种子是随机产生的,粒子是随机移动的。如果粒子没有落在种子或粒子附近,它们就会移动。其中用户输入种子(红色像素),粒子(黑色像素),步骤(无或迭代),平面大小。 我的代码很慢。我怎样才能让它更快? 我随机创建x和y坐标并绘制红色像素(种子),然后随机创建x和y为黑色像素(粒子),如果一个黑色像素降落在有红色或黑色像素的地方,它
-
对百分比和利息计算有困难[副本]
包括一个额外的用户投入,即每年增加额外捐款的百分比。例如,假设用户希望在第一年贡献$1000,每年增加2%。在第一年结束时,1000美元将增加到帐户中。在第二年年底,额外的金额增长2%,因此1020美元将增加到帐户。在第3年结束时,额外的金额又增长了2%,所以1040.40美元将被添加到帐户中,等等。我有麻烦与附上的代码,谁能帮助我吗? 编辑:当运行输入为100、7.5、10、1000、5的代码时
-
利用GraphQL和Mongoose
是否可以同时利用GraphQL和Mongoose? 到目前为止,我已经能够集成GraphQL和Mongoose来处理填充数据库,但是我很难理解这如何工作来检索数据,特别是具有嵌套引用的数据。 考虑这个模式: Bar模式本质上是相同的,只有一个“名称”字段。 是否可以运行GraphQL查询,用“bar”中的引用填充数据? 目前,我们正在使用GraphQL工具创建TypeDef、突变和查询,如下所示:
-
利用AT命令在GSM上发送多部分短信
我有一个windows应用程序发送短信连接到GSM调制解调器。我只使用AT命令连接到端口和发送文本。 下面是ExecCommand方法
-
如何利用NodeJs MySql2库Async/Await捕获连接错误
NPM和GitHub上的文档没有显示如何在建立连接时捕获异常。我在猜测,根据查询方法的工作原理。那么,作为一个新图书馆的新手,我必须阅读代码来弄清楚它吗?还是我缺少了一些常见的标准做法?我故意输入了一个坏密码,只是为了测试错误处理。 我应该执行try/catch,还是期望返回一个err对象?如果他们在查询方法上返回一个err对象,而不是在连接方法上返回一个err对象,这是不一致的吗? 使用亚马逊A
-
利用keras保持空间信息的图像预测二维矩阵
我想训练CNN使用Keras从图像预测矩阵(热图)。我的想法是微调keras提供的预训练网络(resnet、Exception、vgg16等)。 第一步是用预先训练好的顶层替换满足问题约束的顶层。我试图预测数值范围为0到1的热图图像。因此,我希望网络的输出为矩阵。我相信如果我使用,然后使用层,我将失去我不想要的空间信息(对吧?)。 我希望我的代码是灵活的,能够独立于正在使用的预训练体系结构运行(我
-
利用ViewModel获取Android片段中的实时数据
我需要观察Modelview中的livedata更改来更新片段(将列表添加到RecycerView中)。 该实现工作正常,但在片段之间切换时面临问题。 并试图将观察者移除为:或或或尝试在
-
利用每日观察预测医院床位需求
基本上,我未来3个月的任务是预测医院急诊科的床位需求和其他几个变量。这些数据是这些变量的5年每日观测值。数据完整,无缺失值。 目标是提高当前工具(Excel工作簿)的预测精度。 到目前为止,我在大学里还没有参加过任何时间序列或优化课程——所以,当我意识到我不知道如何处理这个项目,而且我将完全独自工作时,想象一下我的恐惧吧。我被告知部门里没有人有任何经验,也没有人能帮助我。我正在使用RStudio,
-
利用通用存储库接口
我见过存储库模式的各种用法。我倾向于一种我很少看到的模式,我想知道这是否有充分的理由。 例子: 利益 构造函数将是内部的,只能通过工厂模式访问,所以我不担心这里的复杂性。 IPerson 强制实现 Save() 方法,但教师不需要知道它是如何持久化的 工作原理类似于实体框架代理对象 我可以在 Iperson 对象上调用 Save(),而无需知道它是老师 应用- 欺骗 > 业务对象不再是普通的旧C#
-
PHP不工作后MacOS更新到高塞拉利昂
php5_module /usr/local/Cellar/php56/5.6.31_7/libexec/apache2/libphp5.so 以下是apache错误日志: [Tue Sep26 23:59:38.600410 2017][mpm_prefork:通知][pid 980]AH00169:捕获SIGTERM,关闭[Tue Sep26 23:59:38.622998 2017][cor