《运筹优化》专题
-
闭站保护(升级优化中)
什么是闭站保护 由网站自身原因(改版、暂停服务等)、客观原因(服务器故障、政策影响等)造成的网站较长一段时间都无法正常访问,百度搜索引擎会认为该站属于关闭状态。站长可以通过闭站保护工具进行提交申请,申请通过后,百度搜索引擎会暂时保留索引、暂停抓取站点、暂停其在搜索结果中的展现。待网站恢复正常后,站长可通过闭站保护工具申请恢复,申请审核通过后,百度搜索引擎会恢复对站点的抓取和展现,站点的评价得分不会
-
8.3. 推荐算法优化试验
推荐算法优化试验 推荐算法和AppAdhoc A/B Testing 许多网站或APP都涉及到推荐系统,比如电商产品会涉及在结算月推荐“购买了此商品房的用户也购买了…”,比如新闻资讯类的首页动态推荐Feed流,影视和音乐类的产品会在最显著的地方有推荐板块等等。。。 无论是基于内容,基于协同过滤,或是基于标签的算法模型,都会面临同样的问题:如何衡量算法模型的好坏?很多时候,只能凭感觉,实际效果往往差
-
8.1. 购物流程优化试验
购物流程优化试验 试验场景 本例介绍的试验场景是购物流程的优化,即在流程中某一个环节进行AB测试,进而统计流程中关键环节的转化,从而进行优化决策。本例使用方法同样适用于如投资流程、注册流程的优化等等。本例的目的是为了展示当试验涉及多个页面时,如何进行试验操作。 试验方案 对于某电商网站首页,对轮播图进行AB测试: 原始版本 试验版本 试验指标 关注的指标是: 1.首页轮播图转化 2.在产品浏览页,
-
9.2 娃娃机 webview 配置优化
Android 版本大于4.4,需要将自动播放权限打开 参考代码: WebView.getSettings().setMediaPlaybackRequiresUserGesture(false) 参考链接: https://developer.android.com/reference/android/webkit/WebSettings.html#setMediaPlaybackRequire
-
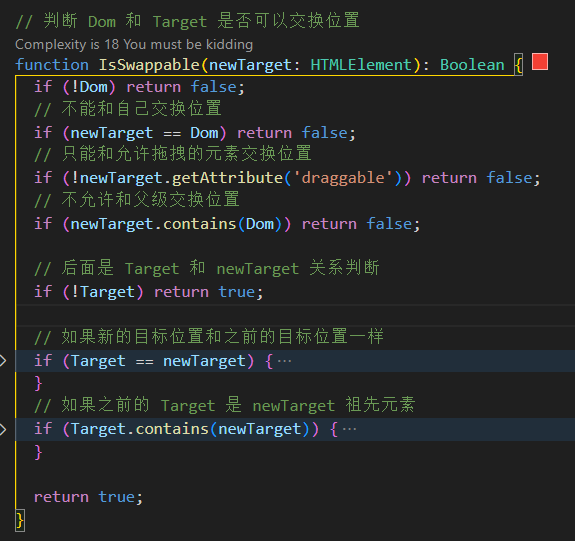 函数模块化,如何优化?
函数模块化,如何优化?这样一堆 if 合理吗?后面还会加判断,会更多。 再拆分的话感觉不太好,有更好的方法吗?
-
mysql sql语句优化的问题?
mysql数据库里面一个商品表;商品表有200多个字段,有2000万条数据,可是商品分页的时候,sql语句老是出现在慢查询日志里,请教高手如何优化? select * from d_shop order by id DESC limit 200, 220
-
你觉得优酷网的综艺频道怎么运营算是成功呢?
本文向大家介绍你觉得优酷网的综艺频道怎么运营算是成功呢?相关面试题,主要包含被问及你觉得优酷网的综艺频道怎么运营算是成功呢?时的应答技巧和注意事项,需要的朋友参考一下 1 首先,要抓住“泛文化”这个市场新增量,不断拓展内容视角,满足用户“千人千面”的需求。真人秀、脱口秀、轻综艺、真人秀+脱口秀、甚至是纪录片等综艺类型节目都可以成为“泛文化”的表达形式,在综艺的定义上摆脱束缚,采用用户偏好的方式去创
-
运行时对象指针的C优先级队列错误为无效堆
我已经尝试在c中实现一个优先级队列大约5个小时了。 我不相信我的比较仿函数在做它应该做的事情,但是对我来说,我不知道为什么。 在我的Node类的底部,我有一个结构CompareNode,Node类有一个返回int成员变量的函数。 在我的main.cpp我声明优先级队列。 我得到一个调试断言失败错误,无效堆。 在调试时,我调用openList时似乎是这样。top()它没有返回正确的节点。
-
除了运算符优先级外,外圆括号什么时候起作用?
C中的括号在许多地方使用:例如,在函数调用和分组表达式中以覆盖运算符优先级。除了非法的额外括号(例如在函数调用参数列表周围)之外,C的一般(但不是绝对)规则是额外的括号永远不会受到伤害: 5.1主表达式 5.1.1概述[初步概述] 6括号表达式是其类型和值与封闭表达式相同的主表达式。括号的存在不影响表达式是否为左值。括号表达式可以在与可以使用封闭表达式的上下文完全相同的上下文中使用,并且具有相同的
-
如何获得运行线程的优先级?(How to get the priorities of running threads?)
问题描述 (Problem Description) 如何获得运行线程的优先级? 解决方案 (Solution) 以下示例使用setPriority()方法打印正在运行的线程的优先级。 public class SimplePriorities extends Thread { private int countDown = 5; private volatile double d =
-
为什么要使用三方比较运算符()而不是双向比较运算符?这样有优势吗?
我知道,如果操作数为整型,运算符将返回类型的prvalue。我还知道,如果操作数是浮点类型,运算符将生成类型的prvalue。 但是为什么要使用三方比较运算符而不是双向运算符(,,,,,)?这会给我带来什么好处吗?
-
 深度优先生成树和广度优先生成树
深度优先生成树和广度优先生成树主要内容:非连通图的生成森林,深度优先生成森林,广度优先生成森林前面已经给大家介绍了有关 生成树和生成森林的有关知识,本节来解决对于给定的无向图,如何构建它们相对应的生成树或者生成森林。 其实在对无向图进行遍历的时候,遍历过程中所经历过的图中的顶点和边的组合,就是图的生成树或者生成森林。 图 1 无向图 例如,图 1 中的无向图是由 V1~V7 的顶点和编号分别为 a~i 的边组成。当使用 深度优先搜索算法时,假设 V1 作为遍历的起始点,涉及到的顶点和边
-
Repast Symphony调度方法优先级和代理优先级
我有一个(我希望)简单的问题要问那些有就餐交响乐经验的人。 基于注释的调度允许设置优先级。如果我为此使用了SchduleParameters.FIRST_PRIORITY和SchduleParameters.LAST_PRIORITY参数,如果每个代理在每个滴答处执行这些方法,则整体调度程序如何解释这一点? > 首先,所有代理都使用ScheduleParameters执行该方法。首先是优先级,然后
-
在Pytorch中使用自定义损失的培训模型如何设置优化器并运行培训?
我是pytorch的新手,我正在尝试运行我找到的github模型并对其进行测试。因此,作者提供了模型和损失函数。 像这样: 数据加载 假设我想训练这个模型15个时代。这就是我到目前为止所做的:我正在尝试设置优化器和训练,但我不确定如何将自定义丢失和数据加载绑定到模型,并正确设置15个历元训练。 有什么建议吗?
-
从运行流中无限个元素的数组中返回最大k个元素的优化算法
我有一个运行的整数流,如何在任何时间点从这个流中获取最大的k个元素。