《副业》专题
-
Python(FLASK)有像nodaemon这样的想法吗?[副本]
使用nodaemon时,代码更改将在不重新启动服务器的情况下显示,Python(FLASK)有这样的事情吗?
-
如何将输入数据视为变量?[副本]
如何使用例如
-
熊猫:子索引数据帧:副本与视图
假设我有一个数据帧 我从我的数据子集创建另一个数据帧: 是否保存了中这些元素的副本?有没有办法创建该数据的?如果是这样,如果我尝试修改此视图中的数据会发生什么情况?Pandas是否提供任何类型的写时拷贝机制?
-
需要在R中生成5000个均值[副本]
我有一个标准差,平均值和样本量。我需要创建一个循环,将产生5000个样本的意思 我该怎么做?
-
Android中的service和intentService有什么区别?[副本]
Android中的和有什么区别?
-
用`or`b布尔值查询数据帧?[副本]
我有一个简单的熊猫数据框架。 我想保留数据帧的某些行。让我们说所有的“瑞秋”和“杰夫斯”。我尝试了: 结果是只有的数据帧。有没有组合查询的方法?
-
如何为firebase firestore创建搜索功能?[副本]
原始关闭原因未解决 我只找到了有关实时数据库而不是fiRecovery的答案,我希望能够让用户搜索名称并取回所有匹配的文档。我正在使用一个文本字段来调用文本字段文本的函数onChange(也限制为每2秒调用一次以减少调用量)。 这就是同一集合中每个文档的建模方式。我只想获取字段“name”与文本字段搜索文本匹配的文档。到目前为止,我已经尝试过: 我可以让代码工作的唯一方法是使用Anywhere F
-
 更改TextField(JavaFX)的颜色而没有副作用
更改TextField(JavaFX)的颜色而没有副作用但是该文本字段上的上下文菜单将具有相同的颜色。 如何解决?
-
正在以块形式加载csv文件[副本]
在那里我得到了多个chunksize部分,我试图做一些操作,比如 对于操作,它选择任意一个块体部分,并执行它的所有操作。那剩下的部分呢?如何在没有内存错误的情况下对完整的数据进行操作。
-
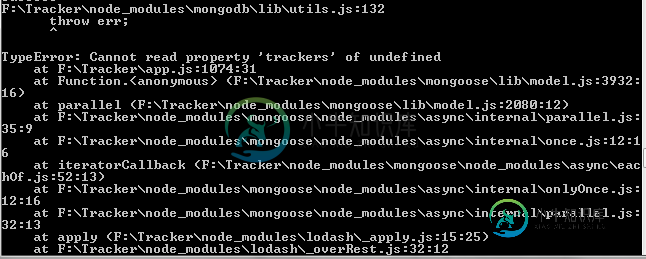 如何修复未定义的mongoose模式?[副本]
如何修复未定义的mongoose模式?[副本]我有一个包括几个子模式的用户模式。我有两个相似的子模式,其中一个是可以识别的,但另一个是一直未定义的。我的用户架构如下: 在上面的模式中,我有一个项目在post路线中工作得很好。表单已正确发布、保存和显示,但无法发布跟踪器的相同路由,并给出“跟踪器未定义”错误: 项目后路由: 以下是追踪者的帖子: 请注意,项目模式和跟踪器模式都保存在一个模型文件夹中,并且在app.js中是必需的
-
火花2。x数据帧或数据集?[副本]
我的理解是Spark 1之间的一个重大变化。x和2。x是从数据帧迁移到采用更新/改进的数据集对象。 但是,在所有Spark 2. x文档中,我看到正在使用,而不是。 所以我问:在Spark 2. x中,我们是否仍在使用,或者Spark人员只是没有更新那里的2. x文档以使用较新的推荐的?
-
反应:状态的意思写成…状态[副本]
我是React的新手,你能告诉我这是什么意思吗?
-
setContentView(R.Layout.Activity_Main)处的oncreate中出错;在Android Studio[副本]
android studio中的货币转换器应用程序不停地停止,所以我对堆栈溢出进行了一点点搜索,为什么会出现这种情况,主要是因为一些小的错误,并且了解了如何检查堆栈跟踪,但是我没有能力解决这个问题。 在堆栈跟踪中,我看到错误位于OnCreat中的setContentView(r.layout.activity_main)。请帮我解决一下。我将在下面附加mainactivity.java和activ
-
如何将Django文件上载到AWS ec2?[副本]
我使用PyCharm社区创建了我的网站。 我在上,现在我希望在上部署该站点。 但是我不知道在创建实例之后如何继续。 有人能指导我如何上传我的文件使用和。 先谢谢你
-
这两个python if语句是否相同?[副本]
有人问这两者是否相同,我更喜欢哪一个。我告诉他他们是一样的,但他似乎对答案不满意。那么,它们是不同的还是相同的,你更喜欢哪一个?