《副业》专题
-
adb无法识别设备[副本]
-
创建我的对象的副本
我是个初学者,我想知道以下几点。 假设我有一个类并创建了一个对象并将一些数据放入其中: 然后我想创建另一个对象,并使其具有与相同的内容(但不是相同的内存位置)。我能做到以下几点吗? 或者这只是将和设置为相同的内存地址,而我只是在内存中的单个对象上有效地获得了两个句柄? 我读过关于克隆物体的书,它看起来太复杂了。我觉得自从我在打算复制整个内容,而不仅仅指向第一个。是这样吗? 所以我的问题是:为什么不
-
Java POI自动大小columun[副本]
Auossize大部分时间都工作得很好。对于一些单元格,如果使用粗体或较大的字体,则不起作用。 有人知道避免这个问题的方法吗?我在网上没有找到任何东西,我想这是Lib的问题。
-
增强图形和精神[副本]
谁能解释一下这最后一行吗?我需要最终确定两个顶点是否相连。
-
Java日期更改格式[副本]
但这对对象没有任何影响,它还是用旧格式的,不能真正理解它为什么会那样。
-
我找不到硒元素[副本]
我试图运行下面的selenium代码,但我得到了一个异常: 封装演示; Selenium试图在单击登录名webelement之前找到webelement的电子邮件ID。请帮忙。
-
Python Pandas数据帧到CSV[副本]
你好,我有一个pandas系列的数据文件名“boilerinfo”来自一个API请求,我想创建一个CSV文件的数据。我该怎么做? python可以在这个目录中创建一个CSV文件吗?C:\users\lingbart\documents\python\wb Data
-
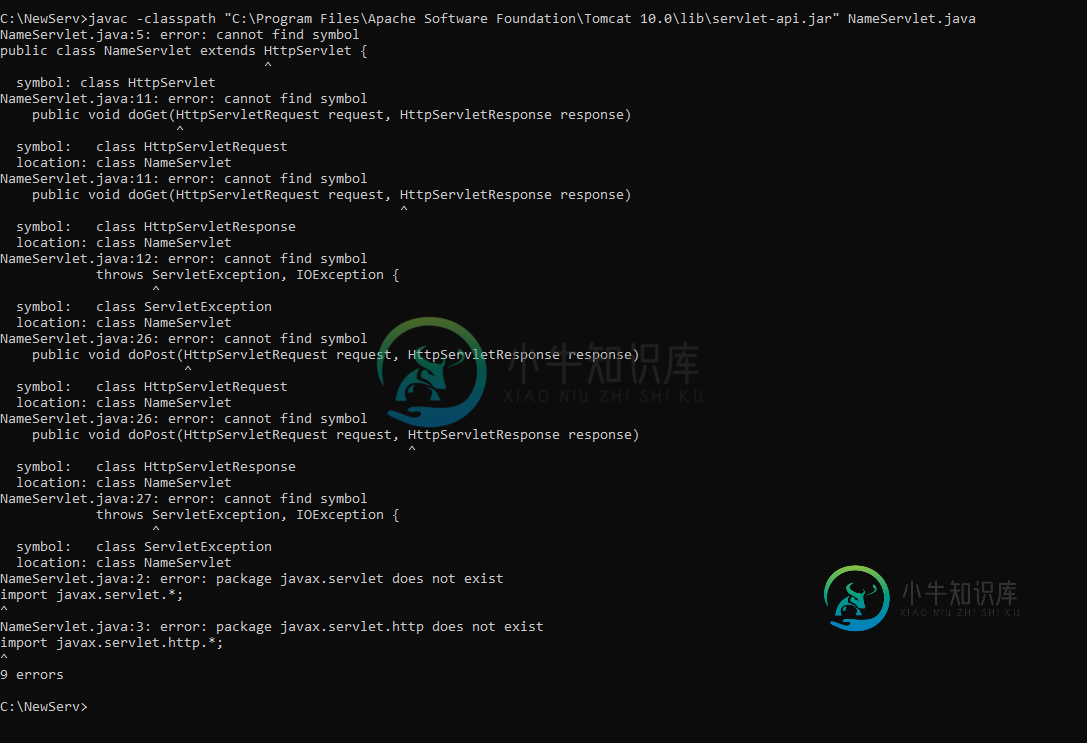 如何安装Java EE SDK?[副本]
如何安装Java EE SDK?[副本]我在上大学的时候写了一章关于servlet的内容。书中要求我复制一段代码并在cmd中运行。它不会在cmd中运行,本章含糊地解释了如何安装Java EE。下面是代码和错误:
-
Android Studio、Java 8和函数[副本]
我在Mac上安装了最新的Java8和最新的Android Studio。在Android Studio中我找不到java.util.function。这使我相信它没有使用Java8。我已经搜索了一个日志时间,我的Mac上唯一的Java是Java8。我还检查了项目结构,它指向Java8。我重新安装了Android Studio,创建了一个新项目,但我仍然无法导入java.util.function。
-
什么会更快,>=还是>?[副本]
我想知道>是否比>=更快?我试着对其进行基准测试,但要么需要0ms,要么需要永远。我知道差别会很小,但我必须在很多像素上操作。有人能告诉我什么更快吗?
-
直接从ActiveMQ Artemis副本使用
如果考虑到可伸缩性,让所有使用者调用一个负责管理特定队列的节点意味着所有流量都流向一个节点。 Kafka允许使用者从最近的节点获取数据,如果该节点包含leader的副本,那么ActiveMQ上有类似的内容吗?
-
Java SE8中parallelStream的优点[副本]
除了我的代码运行在单个核心机器上(此时我假设JVM会将所有工作分配给单个core,从而不会破坏我的程序)之外,到处使用parallelStream()是否有任何缺点?
-
Pycharm Selenium Geckodriver路径问题[副本]
我已经尝试了其他帖子中找到的解决方案,但没有任何成功。 谢谢。
-
并行处理数据帧[副本]
我有一个进程,它要求处理dataframe的每一行,然后向每一行追加一个新值。这是一个很大的数据帧,一次处理一个数据帧需要几个小时。 如果我有一个将每一行发送到一个函数的迭代罗循环,我可以并行处理以加快速度吗?行的结果不相关 基本上我的代码是这样的 有没有一种简单的方法可以这样做来加快处理速度?
-
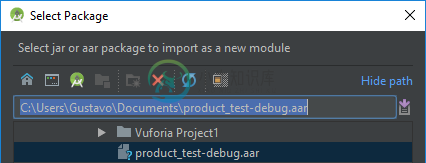 在android Studio中导入.aar[副本]
在android Studio中导入.aar[副本]我对Android Studio不是很有经验,我尝试过无数种方法来解决这个问题,但都没有成功。 目标:将文件作为库导入到Android Studio应用程序中。 问题: null null 在所有这些步骤之后,我尝试同步gradle,但它仍然不识别.aar。以下是错误: 我尝试将.aar文件放入libs文件夹,并将build.gradle(Project:MyApplication)中的这个函数修