《计算机视觉》专题
-
 百度视觉设计面试:在面试中提升自己
百度视觉设计面试:在面试中提升自己一面: 当时一下午通过了两个人的面试,第一个是一个男生第二个是个女生,年龄都跟我差不了多少的样子,都很随和。当然问得问题其实都差不多。 问题汇总: 自我介绍,看作品集,针对作品集提问。 然后问最近在看什么书啊,平时有什么爱好啊,性格怎么样啊,在团队中喜欢扮演什么样的角色,为什么要来这里面试,未来的预期,有没有工作经验干什么工作等等。 然后第二个女生面完用的时间比较短,她当时出去之前说去问问老板现在
-
 百度视觉设计面试:在面试中提升自己
百度视觉设计面试:在面试中提升自己一面: 一面是5月份,当时一下午通过了两个人的面试,第一个是一个男生第二个是个女生,年龄都跟我差不了多少的样子,都很随和。当然问得问题其实都差不多。 问题汇总: 自我介绍,看作品集,针对作品集提问。 然后问最近在看什么书啊,平时有什么爱好啊,性格怎么样啊,在团队中喜欢扮演什么样的角色,为什么要来这里面试,未来的预期,有没有工作经验干什么工作等等。 然后第二个女生面完用的时间比较短,她当时出去之前说
-
 视觉设计师|今年失败的大厂面试经历
视觉设计师|今年失败的大厂面试经历【字节】问的很多都是网上能搜到的很多那种模版式的问题 1.最满意的作品是哪个为什么?2.认为自己最大的优势是什么?3.如何确定自己的设计是正确的? 这些问题虽然提前准备了,但答案也不理想,因为其实最满意的作品是练习稿,而工作项目都好一般,但是讲练习稿没有落地又很没有说服力。而最大的优势,自己其实什么都会点,可是却又没有一个特别突出的,一面挂 【吉比特】面试十分短暂,工作强度无法达成一致,面试官说有
-
gPRC文档 - gRPC动机和设计原则
注: 官网文档 gRPC Motivation and Design Principles, 我原来自己写了一份简单的读书笔记,后来发现有同学全文翻译了这篇文章,就放弃了自己的内容直接转载了. 文档地址 gRPC Motivation and Design Principles:英文原文 GRPC的产生动机和设计原则: 此文的中文翻译版本 读后感 注:以下是个人的一点感触 2015年3月的某一天,
-
Gupshup whatsapp机器人预计实现时间
大家好,我们是一个小团队,希望实现一个Gupshup/WhatsApp机器人。 我们想知道这种机器人需要多长时间才能安装并正常工作? 如果道歉不是一个技术问题,但我们不知道还有什么地方可以问。
-
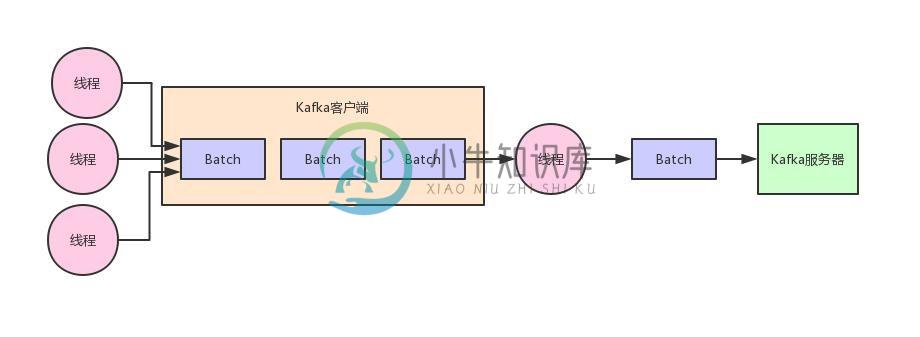 Kafka为何要设计缓冲池机制?
Kafka为何要设计缓冲池机制?主要内容:1、Kafka的客户端缓冲机制,2、内存缓冲造成的频繁GC问题,3、Kafka设计者实现的缓冲池机制,4、总结一下这篇文章,同样给大家聊一个硬核的技术知识,我们通过Kafka内核源码中的一些设计思想,来看你设计Kafka架构的技术大牛,是怎么优化JVM的GC问题的? 1、Kafka的客户端缓冲机制 首先,先得给大家明确一个事情,那就是在客户端发送消息给kafka服务器的时候,一定是有一个内存缓冲机制的。 也就是说,消息会先写入一个内存缓冲中,然后直到多条消息组成了一个Batch,才会一
-
 思谋面经 24算法实习生(智能视觉方向)
思谋面经 24算法实习生(智能视觉方向)一面 60min: 问项目、问了一个我研究方向的八股、问了损失函数等DL基础知识 手撕了一道题:根据IOU划分簇,没考虑到连通簇的情况,面试官提醒了一下,写出来了 一面面试官应该是视觉算法工程师,一线程序员,没什么架子,并且了解的面很广 二面 50min: 问项目,问了许多项目,很细节,问多久可到岗,实习到多久 二面第二天问了HR,反馈是通过了,并约了下周HR面 期待第二个Offer
-
 OPPO 视觉算法开发工程师面经 (二面已挂)
OPPO 视觉算法开发工程师面经 (二面已挂)OPPO 计算机视觉算法开发工程师(camera方向) 一面(8.9): 着重介绍一下就是说这个项目里面你这段实习经历里面他有什么需要解决的一个任务,然后遇到了些什么难点,你是怎么解决这些问题的? 怎么提升模型服务CPU和GPU的利用率的? 神经网络是否会出现预测错误的情况,如何改善? 问了一个项目中的损失函数的目的是什么 介绍一下知识蒸馏,不同的蒸馏方法的优劣势 手撕:二叉树按层输出节点(层序遍
-
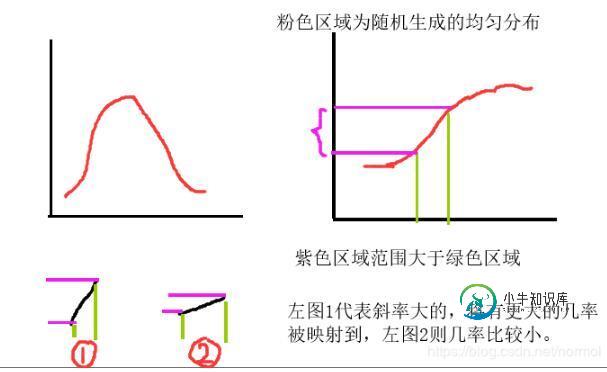 python 计算概率密度、累计分布、逆函数的例子
python 计算概率密度、累计分布、逆函数的例子本文向大家介绍python 计算概率密度、累计分布、逆函数的例子,包括了python 计算概率密度、累计分布、逆函数的例子的使用技巧和注意事项,需要的朋友参考一下 计算概率分布的相关参数时,一般使用 scipy 包,常用的函数包括以下几个: pdf:连续随机分布的概率密度函数 pmf:离散随机分布的概率密度函数 cdf:累计分布函数 百分位函数(累计分布函数的逆函数) 生存函数的逆函数(1 - c
-
如何根据php中的小计和运费计算总金额?
我在做购物车。我能根据数量计算产品价格。 现在我计算的总额取决于小计和运费与产品价格。 当我增加产品数量时,它会计算产品价格,但不会计算小计和总金额。 或者有没有其他安全的方法来处理这个问题? 你能帮我解决这个问题吗?
-
如何按组计算计数,然后每组只保留一个
有没有一种方法可以简化或使R代码更优雅?
-
为什么RDD计算计数需要花费这么多时间
(英语不是我的第一语言,所以请原谅任何错误) 我使用SparkSQL从hive表中读取4.7TB的数据,并执行计数操作。做那件事大约需要1.6小时。而直接从HDFS txt文件读取和执行计数,只需要10分钟。这两个作业使用相同的资源和并行性。为什么RDD计数需要这么多时间? 配置单元表大约有30万列,序列化可能代价高昂。我检查了spark UI,每个任务读取大约240MB的数据,执行大约需要3.6
-
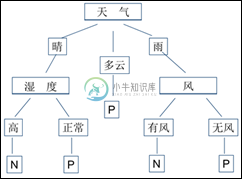 Python机器学习之决策树算法
Python机器学习之决策树算法本文向大家介绍Python机器学习之决策树算法,包括了Python机器学习之决策树算法的使用技巧和注意事项,需要的朋友参考一下 一、决策树原理 决策树是用样本的属性作为结点,用属性的取值作为分支的树结构。 决策树的根结点是所有样本中信息量最大的属性。树的中间结点是该结点为根的子树所包含的样本子集中信息量最大的属性。决策树的叶结点是样本的类别值。决策树是一种知识表示形式,它是对所有样本数据的高度概括
-
 oppo机器学习算法实习面经
oppo机器学习算法实习面经前言: 岗位:机器学习算法实习 笔试情况:无笔试 一面 1.自我介绍(非科班硕,一份水实习); 2.介绍项目,并由此引出一系列八股文: 介绍gbdt算法的原理与实现 说说xgboost对于gbdt所做的主要优化 3.介绍实习工作 简单介绍resnet及其主要改进(shortcut连接,BN层),说说这些改进为什么work 介绍transformer及self-attention机制实现方式 了解哪
-
分解机(Factorization Machines)推荐算法原理