《算法岗》专题
-
算法 - 算法分析
数学模型 1. 近似 2. 增长数量级 3. 内循环 4. 成本模型 注意事项 1. 大常数 2. 缓存 3. 对最坏情况下的性能的保证 4. 随机化算法 5. 均摊分析 ThreeSum 1. ThreeSumSlow 2. ThreeSumBinarySearch 3. ThreeSumTwoPointer 倍率实验 数学模型 1. 近似 N3/6-N2/2+N/3 ~ N3/6。使用 ~f(
-
算法题 - hash表算法
第一部分:Top K 算法详解 问题描述 百度面试题: 搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。 必备知识 什么是哈
-
算法
算法 我注意到从第一章开始,容器就占据了STL喝彩声中最大的一份。在某种意义上,这是可以理解的。容器有着非凡的造诣,它们使大批C++程序员每天的基本生活变得简单。尽管如此,STL算法的权利也很重要,一样有能力减轻程序员的负担。事实上,有超过100个算法,很容易证明比起容器,它们提供给程序员更精巧的工具集(起码一样强)。也许它们的数量是一部分问题。搞清八种截然不同的容器类型明显比记住70个算法的名字
-
算法
排序 排序算法 平均时间复杂度 最差时间复杂度 空间复杂度 数据对象稳定性 冒泡排序 O(n2) O(n2) O(1) 稳定 选择排序 O(n2) O(n2) O(1) 数组不稳定、链表稳定 插入排序 O(n2) O(n2) O(1) 稳定 快速排序 O(n*log2n) O(n2) O(log2n) 不稳定 堆排序 O(n*log2n) O(n*log2n) O(1) 不稳定 归并排序 O(n*
-
算法
算法
-
算法
目录 排序算法 检索算法
-
 8.20算法岗
8.20算法岗#做完网易2023秋招笔试题,我裂开了# #网易笔试# 求讨论思路! 第一题:求最小交换次数,让排列是非递减(思路:答案就是逆序对的数量) 第二题:求只含r e d字符的字符串中,所含三个元素数量相等的子串数量 第三题:求n个数中k个数的按位与结果最大 第四题:第一项a,第二项b, 之后每一项都是前两项乘积的平方
-
链接挖掘算法之 PageRank 算法和 HITS 算法
参考资料:http://blog.csdn.net/hguisu/article/details/7996185 更多数据挖掘算法:https://github.com/linyiqun/DataMiningAlgorithm 链接分析 在链接分析中有2个经典的算法,1个是PageRank算法,还有1个是HITS算法,说白了,都是做链接分析的。具体是怎么做呢,继续往下看。 PageRank算法 要
-
 Java算法之递归算法计算阶乘
Java算法之递归算法计算阶乘本文向大家介绍Java算法之递归算法计算阶乘,包括了Java算法之递归算法计算阶乘的使用技巧和注意事项,需要的朋友参考一下 本文为大家分享的java算法计算阶乘,在学习Java课程时经常会遇到求阶乘问题,今天接跟大家一起探讨一下 代码如下: 运行结果:
-
贪婪算法与硬币算法
首先,是的,这是我的硬件,我觉得很难,所以我真的很感激一些指导。 我需要证明对于当
-
 2022.08.10 zoom 算法笔试算法题
2022.08.10 zoom 算法笔试算法题1. 不用库函数求sqrt(xxxx). 要求c / c++ 二分 2. 大意:给你n个点以及颜色,只有两种颜色红和蓝,给你n个边(无向图), 节点的权重为该节点到根节点的红蓝两种颜色数量差,问这个树的权重和为多少? dfs 超时 bfs 超时 层次遍历超时。 据说用并查集 但是还没想明白。 3. 大意: 给你n个人,每个人会关注mi个股票。 设计一个推荐系统,推荐规则为:如果i人和j
-
Spark FP Tree算法和PrefixSpan算法
在Spark MLlib中,也只实现了两种关联算法,即我们的FP Tree和PrefixSpan,而像Apriori,GSP之类的关联算法是没有的。而这些算法支持Python,Java,Scala和R的接口。由于前面的实践篇我们都是基于Python,本文的后面的介绍和使用也会使用MLlib的Python接口。 Spark MLlib关联算法基于Python的接口在pyspark.m
-
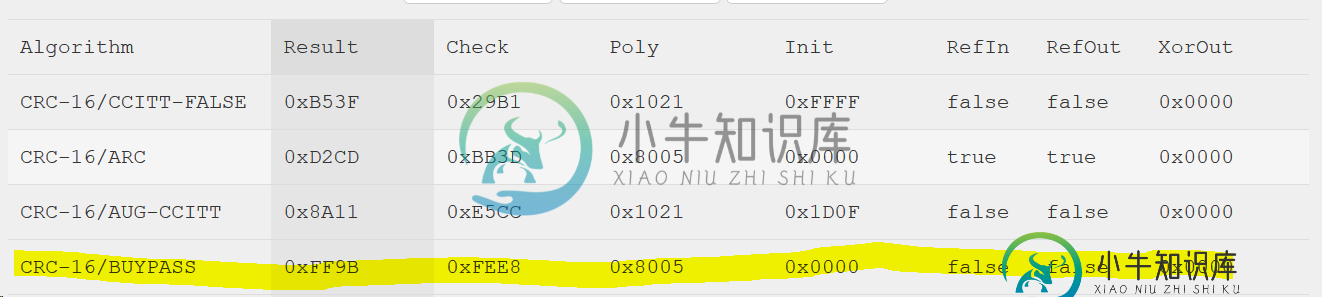 CRC16(ModBus)-计算算法
CRC16(ModBus)-计算算法我正在使用ModBus RTU,并试图找出如何计算CRC16。我不需要代码示例。我只是对机制很好奇。我已经了解到,基本的CRC是数据字的多项式除法,根据多项式的长度,用零填充。下面的测试示例应该检查我的基本理解是否正确: 数据字:01001011 多项式:1001(x3+1) 由于最高指数x3而被填充3位 计算:0100 1011 000/1001->余数:011 计算。 null 第二次尝试:由
-
算法篇
本书的 GitHub 地址:https://github.com/todayqq/PHPerInterviewGuide 算法可以说是大厂的必考题,对于算法,一定要理解其中的精髓、原理。 冒泡排序 冒泡排序的原理:一组数据,比较相邻数据的大小,将值小数据在前面,值大的数据放在后面。 function bubble_sort($arr) { $count = count($arr);
-
KM算法?
本文向大家介绍KM算法?相关面试题,主要包含被问及KM算法?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 匈牙利算法:求最大匹配,那么我们希望每一个在左边的点都尽量找到右边的一个点和它匹配。我们依次枚举左边的点x的所有出边指向的点y,若y之前没有被匹配,那么(x,y)就是一对合法的匹配,我们将匹配数加一,否则我们试图给原来匹配y的x’重新找一个匹配,如果x’匹配成功,那么(x,y)就可以