《导师》专题
-
intellij中的PDFBox导入错误
还尝试了文件->无效缓存\restart。
-
在neo4j中导入csv文件?
我尝试使用Neo4j工具和导入csv文件。 我有个问题。我的csv文件是清晰的,但是,在neo4j浏览器。
-
neo4j中的大数据导入
我正在导入大约1200万个节点和1300万个关系的数据。 是否可以在短时间内直接从sql导入这些数据,因为neo4j以其快速处理大数据而闻名?有什么建议或帮助吗? 以下是CSV使用的加载(数字上的索引(num)):
-
neo4j使用关系导入CSV
-
JAVAlang.NoSuchMethodError:javax。验证。引导配置。getClockProviderClassName
JDK:1.80_131 Tomcat:8.0.27.0 Hibernate验证程序:6.0.7。最终下载的所有依赖项:Hibernate Validator 6 代码在,例外情况如下: 看起来使用了错误的jar文件,但我不知道是哪一个。
-
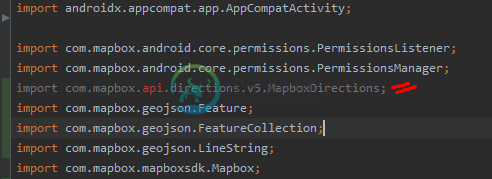 导入Mapbox方向API失败
导入Mapbox方向API失败依赖关系{实现文件树(dir:'libs',include:['*.jar']) 我得到了这个错误:无法获取“https://api.mapbox.com/downloads/v2/releases/maven/com/mapbox/navigation/ui/1.1.0/ui-1.1.0.pom”。从服务器收到状态代码403:禁止禁用分级“脱机模式”和同步项目
-
如何平衡Kafka领导层?
我的Kafka版本是。集群中有两个代理,4个主题,每个主题有4个分区。 当我跑的时候 对于所有主题/分区,我认为Broker1是领导者。 如何平衡领导的负载? 例如,对于主题1和主题2,代理1作为领导者,而对于主题3和主题4,代理2作为领导者。
-
ES6:意外的令牌导入
在设置Javascript Dev环境时,我遇到了以下错误。 我想使用代替。 我用了巴别塔。 我从以下方法尝试了许多解决方案,但是,不起作用或我。 节点错误:语法错误:意外的令牌导入 Node.js -语法错误:意外的标记导入 srcServer.js 。巴伯尔克
-
Java导入外部jar文件
说我已经试过了。java在~/jar中/ 然后我输入: 我想将这个类导入到~/src/中的另一个源文件中: 我尝试了两种方法: 1. 编译期间可以,但当我尝试运行它时,会出现错误: 2. 我尝试在我的. bashrc和. profile中包含以下命令(我没有.bash_profile或.bash_login): 和: 但这一次,它仍然是错误的: 我应该如何包含外部 jar 文件? 编辑:整个项目只
-
谷歌云SQL导出权限
我们每天都在运行从谷歌云SQL到谷歌云存储(跨项目)的自动化完整数据库导出,使用云函数触发导出。(见本文) 从4天前开始,我们收到一个403错误,日志显示:“服务帐户没有bucket所需的权限。” 我们还没有进行任何权限更改,运行:仍然显示,我们的谷歌云SA具有我们预期的“编写者”角色。 从我们的角度来看,似乎我们已经随机失去了此工作流的权限。有没有人对如何调试这个并让这个工作流重新工作有什么建议
-
将mysql数据库导入mariadb
尝试将数据库备份(.sql)从docker容器MySQL:5.6导入到我的本地MySQL(MariaDB)中。 下面是我使用的命令: 也想试试mysqlimport,但我总是遇到同样的错误。 第1行错误1064(42000):您的SQL语法中有错误;查看与您的MariaDB服务器版本相对应的手册,以了解在第1行“MySQL Ver 14.14 Distrib 5.6.33,for Linux(x8
-
MySQL:导入时忽略错误?
我正在导入一个相当大的数据库。文件中几乎有1,000,000行。问题是我在尝试导入数据库时遇到语法错误。上面写着: 第8428420行错误1064(42000):您的SQL语法中有错误;检查与您的MySQL server版本相对应的手册,以获得在“ 致命错误:中超过600秒的最大执行时间”附近使用的正确语法 通常我会打开.sql文件并修复错误。但我的电脑真的很难打开这个文件。 在导入MySQL数据
-
 将hadoop源代码导入intellij
将hadoop源代码导入intellij有没有人知道该怎么做?我在IntelliJ IDEA中读到了导入Maven依赖项,但它并不起作用。谢谢
-
netty引导连接被拒绝
我的/etc/hosts文件如下所示: 不确定该怎么办?字面上假设我可以传递localhost和port,它应该可以工作。
-
在NEO4J中导入csv文件
然后我试着用斜线。