《水木未来》专题
-
如何在水豚和硒中打开浏览器
不仅浏览器没有打开,而且测试失败,输出如下:
-
AWS EMR(带有胶水目录),显式指定catalogId
有没有办法在EMR配置中显式指定一个Glue catalogId? https://docs.aws.amazon.com/emr/latest/releaseguide/emr-hive-metaxore-glue.html
-
带滑块的360°slerp水平旋转摄像机
我正在尝试创建一个脚本,允许我通过水平滑块在0°-360°(y轴)范围内旋转相机,带有Slerp效果。相机只沿着一个轴旋转(我在一个房间的中间,我必须使用水平滑块转身) 我制作了两个脚本:第一个应用于参考立方体以获得旋转,第二个应用于腔室以获得Slerp效果,同时跟踪立方体的旋转。 360°立方体旋转脚本: 具有Slerp效果的摄像机旋转脚本: 它可以工作,但有一些问题:如果我从左(0°)到右(3
-
如何使用apache-poi水平合并单元格
我要做一个垂直合并使用这个函数: 但我不能用类似的函数进行水平合并: 谢谢!
-
使用反应性生菜流水线Redis命令
我使用spring boot webflux以非阻塞方式连接和查询Redis。我已经用LettuceConnectionFactory配置了reactivedistemplate。spring文档指出,将管道与reactivedistemplate一起使用的唯一方法是使用execute( 所以我的问题是,在使用Spring ReactiveRedisTemplate时,是否可以对命令进行管道连接?
-
问题开始为火星控制台包水平
我刚刚将一个旧的OSGi项目迁移到当前的equinox版本(开普勒SR1)。在使用gogo控制台时,我在使用start level 1启动gogo捆绑包时遇到了一个问题(这是我通常对所有相关框架捆绑包所做的)。尽管四个捆绑包都处于活动状态并正在运行,但gogo控制台不会启动。键入help将导致NullPointerException。解决方案是以默认启动级别启动所有gogo捆绑包。我错过了什么吗?
-
如何在水平进度条中设置进度
我想让水平进度条从0移动到100。我在布局中添加了这段代码。我应该怎么做才能移动这个进度条?
-
水槽以不一致的方式下沉数据
我有一个问题。我使用apache flume从txt文件中读取日志,并将其存储到hdfs中。不知何故,一些记录在阅读时被跳过了。我正在使用fileChannel,请检查以下配置。 请帮帮忙。
-
水槽加载csv文件Excels到hdfs接收器
我已将Flume源配置为Spooldir类型。我有很多CSV文件,.xl3和.xls,我希望我的Flume代理将所有文件从假脱机程序加载到HDFS接收器。然而,水槽代理返回异常 这是我对水槽源的配置: 和我的HDFS接收器:
-
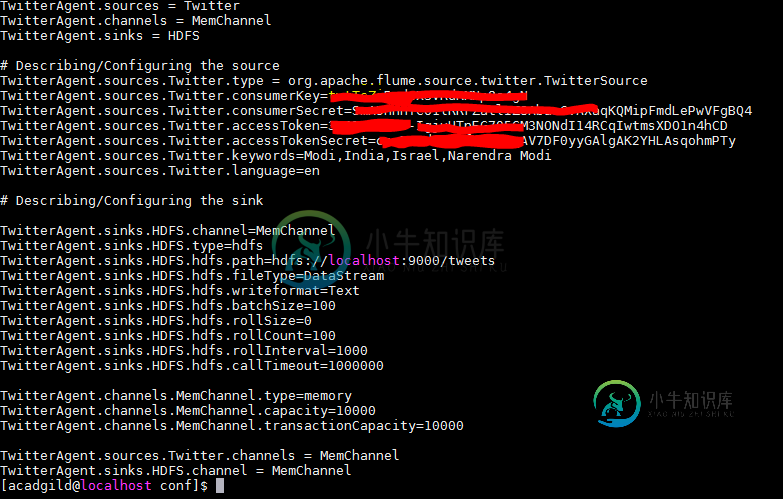 使用水槽获取推文时出现问题
使用水槽获取推文时出现问题我可以用水槽获取推文,但是,流式传输的语言不是我想要的。下面是flume.conf文件 我收到的推文如下所示: 有人能建议我需要做的改变吗?
-
只有一个文件从kafka到hdfs与水槽
我正在尝试通过水槽从kafka将数据放入hdfs中。kafka_producer每10秒发送一条消息。我想在hdfs上的一个文件中收集所有消息。这是我使用的水槽配置,但它在hdfs上存储了许多文件(一个用于消息): 附言我从一个文件开始.csv。kafka 生产者获取文件并选择一些感兴趣的字段,然后每 10 秒发送一个条目。Flume将条目存储在Hadoophdfs上,但存储在许多文件中(1个条目
-
在哪里运行写入 HDFS 的水槽代理?
我有25-20个代理将数据发送给几个收集代理,然后这些收集代理必须将数据写入HDFS。 在哪里运行这些收集器代理?在Hadoop集群的Data节点上还是集群外?每种方法的优点/缺点是什么?人们目前是如何运行它们的?
-
如何使用水平滚动android显示图像
我正在使用Recyclerview显示项目列表。现在每次都可以有一些照片/多张照片,我需要在一行中水平滚动显示。 我目前正在使用画廊小部件来显示照片,但因为它现在已被弃用,所以我想用一些其他的东西来显示与画廊相同的功能水平图像。你能帮帮我吗? 非常感谢你的帮助。
-
水平缩放spring kafka消费者应用程序
我想知道什么是相对于最大水平扩展实例数配置分区数量的好方法。 假设我有一个有6个分区的主题。 我有一个应用程序,它使用的与的6.这意味着我将有6个KafkaMessageListenerContainer,每个都使用一个线程,并且均匀地消耗来自所有分区的消息。 如果以上是正确的,那么我想知道如果我通过添加另一个实例水平缩放应用程序会发生什么?如果新实例具有相同的配置,并发为6,当然也具有相同的消费
-
CMOV是如何提高CPU流水线性能的?
我知道当一个分支很容易预测时,最好使用IF语句,因为分支是完全自由的。我了解到,如果分支不容易预测,那么CMOV会更好。但是,我不太明白如何实现这一点? 问题域肯定还是一样的——我们不知道下一条要执行的指令的地址?因此,我不明白在整个管道中,当执行CMOV时,它是如何帮助指令获取器(过去有10个CPU周期)选择正确的路径并防止管道暂停的? 有人能帮我了解一下CMOV是如何改进分支的吗?