
使用水槽获取推文时出现问题

我可以用水槽获取推文,但是,流式传输的语言不是我想要的。下面是flume.conf文件
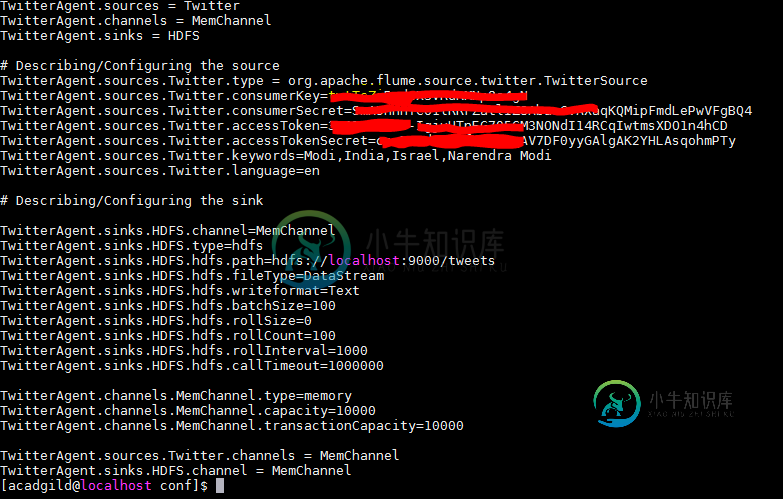
我收到的推文如下所示:

有人能建议我需要做的改变吗?
共有1个答案

Apache Flume中的<code>TwitterSource</code>目前不支持语言过滤。前面的问题描述了一个过程(当然很复杂),通过这个过程,您可以部署自己的代码补丁版本,并提供语言支持:
Flume-TwitterSource语言过滤器
我认为Apache Flume支持语言过滤将是一个有价值的增强。我鼓励你在FLUME项目中用Apache JIRA提交一个请求。
如果你感兴趣,也请考虑贡献一个补丁。我认为这只是将< code>configure方法中的“语言”设置从配置中提取出来,保存在成员变量中,然后在Twitter4J APIs中传递它。
-
我正在尝试使用hdfs水槽运行水槽。hdfs在不同的机器上正常运行,我甚至可以与水槽机器上的hdfs交互,但是当我运行水槽并向其发送事件时,我收到以下错误: 同样,一致性不是问题,因为我可以使用hadoop命令行与hdfs交互(水槽机不是datanode)。最奇怪的是,在杀死水槽后,我可以看到tmp文件是在hdfs中创建的,但它是空的(扩展名仍然是. tmp)。 关于为什么会发生这种情况的任何想法
-
我想从IBM MQ中读取数据,并将其放入HDFs。 查看了 JMS 的水槽源,似乎它可以连接到 IBM MQ,但我不明白所需属性列表中的“destinationType”和“destinationName”是什么意思。有人可以解释一下吗? 还有,我应该如何配置我的水槽代理 flumeAgent1(在与MQ相同的机器上运行)读取MQ数据——flumeAgent2(在Hadoop集群上运行)写入Hdf
-
我有一个看似简单的水槽配置,却给我带来了很多问题。让我先描述一下问题,然后列出配置文件。 我有 3 台服务器:服务器 1、服务器 2、服务器 3。 Server1:Netcat源代码/S Server2,3:Avro源内存通道Kafka接收器 在我的模拟中,服务器2模拟“生产”,因此不会出现任何数据丢失,而服务器3模拟“开发”,数据丢失是正常的。我的假设是,使用2个通道和2个源将使两个服务器相互解
-
这是我第一次体验提升::property_tree我找不到一种方法来重现从留档(如何访问属性树中的数据)之后的树中获取值的方法。这是我为尝试属性树而编写的简单代码: 这是输出: 如<code>树所示。get_value(“whather”)在树中不返回值。get_value(“null”)不引发异常,并且<code>get_optional 我的环境是:
-
当hdfs不可用时,是否有方法确保数据安全?场景是:kafka源,flume内存通道,hdfs接收器。如果水槽服务关闭了,它是否可以存储主题分区的偏移量,并在恢复后从正确的位置消费?
-
我们有自定义密钥类型的ignite缓存,即带有属性的Person key、人名和人姓以及自定义值类型的Person Info、带有属性的Person Address和Person Age等。这些类是在Java中定义的,缓存是在Bean文件中配置的,并使用CacheJDBCPOJO Store加载的。 由于这些类在节点js中不可用,我们如何使用cahe.put/cache.get.从节点js加载/提