《运维工程师》专题
-
 腾讯数据工程凉经
腾讯数据工程凉经讲一讲项目 clickhouse的存储结构 说一说你对数仓的理解 B+树和B树的理解: 复杂度,能支持的查询类型,存储方式,并发性。 MySQL的两个引擎的区别 ClickHouse的插入和删除 数仓的建设 MergeTree的引擎 sql 找出昨天每个城市中的消费top10 的uid 数仓的岗位,感觉不是很匹配,30分钟结束…
-
 三战腾讯 数据工程
三战腾讯 数据工程占个坑先,谢谢面经攒人品。 前两次面鹅都挺难绷的,一点大数据没问 第一次光子测开不知道怎捞了我,人生第一面,估计是我一开始就问为啥捞我到测开?就随便问了点,速度面完秒挂 0.自我介绍,项目(估计不相干,所以讲完就过了) 平常如何自我提升技能 1.session和cookies的区别 2.get和post的区别 2.5元组和列表的区别 3.讲讲数据库的索引 4.什么时候用索引什么时候不用 5.进程和
-
工作流程结构、促销优惠流程
非常感谢您的帮助,在实施细节方面,以及我下面的两个澄清问题: 背景: 创建优惠促销工作流程。优惠有截止日期(我们在优惠被接受后开始倒计时。) 用户可以选择拒绝报价(工作流程随后停止)一旦报价被接受,他们将有7天的时间尝试兑换返现积分。一旦他们满足返现积分要求,我们将把积分记入他们的账户 第一个问题:下面的逻辑正确吗?我正在使用信号。 我是如何考虑编写工作流的(然而,当我尝试发出不同的信号时,我似乎
-
 摩尔线程c++软件开发工程师一二面(已oc)
摩尔线程c++软件开发工程师一二面(已oc)9.21 摩尔线程一面 讲一讲两种字节序 如何判断大端还是小端字节序 讲一讲联合体的空间占用特点 修改其中一个成员的值,其他变量会受影响吗 讲一讲malloc和new的区别 new和malloc需要指定申请的字节数吗 讲一讲sizeof sizeof一个指针是什么结果 为什么32位的指针是4个字节 指针和引用的区别 都有什么类型创建的时候必须初始化吗 传参传引用和传指针的区别 讲一讲socket编
-
新的Vaadin 14应用程序无法运行,错误“无法确定'节点'工具。” 缺少Node.js和npm工具
问题内容: 选择“ 纯Java Servlet” 选项后,我使用“ 入门” 页面创建了一个新的Vaadin 14应用程序。 __ 该网页成功下载了我解压缩的文件,并使用IntelliJ Ultimate Edition 2019.2。打开。我等了几分钟,Maven才开始做,下载并重新配置了项目。最终,我进入了IntelliJ中的Maven面板,并运行了项目和。 我在控制台上收到以下错误消息。 参见
-
ES在运维监控领域的其他玩法 - 时序数据库
之前已经介绍过,ES 默认存储数据时,是有索引数据、_all 全文索引数据、_source JSON 字符串三份的。其中,索引数据由于倒排索引的结构,压缩比非常高。因此,在某些特定环境和需求下,可以只保留索引数据,以极小的容量代价,换取 ES 灵活的数据结构和聚合统计功能。 在监控系统中,对监控项和监控数据的设计一般是这样: metric_path value timestamp (Graphit
-
 秋招回顾5-字节提前批系统架构运维面试
秋招回顾5-字节提前批系统架构运维面试7.14提前批面试,属于面的比较早的一波了~ 先自我介绍一下 然后问技术问题: haproxy,keepalived实现原理 VIP和IP有啥区别 K8S网络了解吗 POD间的通信如何实现 FLANNEL了解多少,处理网络连接,-> 网络连接具体包括哪些工作呢? iptables规则你了解多少 calico 原理 iptables链
-
运维 - 如何屏蔽WGCLOUD主机登录信息的告警通知?
WGCLOUD如何屏蔽主机登录信息的告警信息
-
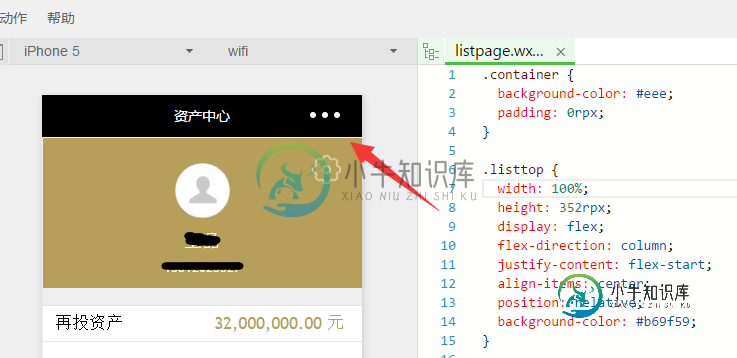 微信小程序 二维码canvas绘制实例详解
微信小程序 二维码canvas绘制实例详解本文向大家介绍微信小程序 二维码canvas绘制实例详解,包括了微信小程序 二维码canvas绘制实例详解的使用技巧和注意事项,需要的朋友参考一下 微信小程序 二维码canvas绘制 上面直接放在一个js中吧方法暴露出来就可以了,顺便说一下关于 样式的问题,因为没必要再去写一篇了,样式:padding , 以前在html页面上我有时候习惯padding:0px,这样设置为0,但是在小程序中写成pa
-
PHP基于phpqrcode类库生成二维码过程解析
本文向大家介绍PHP基于phpqrcode类库生成二维码过程解析,包括了PHP基于phpqrcode类库生成二维码过程解析的使用技巧和注意事项,需要的朋友参考一下 phpqrcode类库官网下载地址: https://sourceforge.net/projects/phpqrcode/ 1.我们先看看php是怎么生成二维码的 1.首先我们先下载一下 phpqrcode 类库。 2.下
-
DP:最长递增子序列思维过程及解法
对于最长的子序列递增问题,我设想保持一个总是有序的DP数组,将最大值保持在最远端。看起来像这样的东西: 我得出第一个不正确的解决方案的思路是,我们想从第一个元素开始查看整个数组,计算LIS,然后在数组末尾递增地添加一个值。在执行此操作时,我们将DP数组中的LIS增量计算为旧子数组加上我们添加的新元素的LIS。这意味着在数组的索引处存在长度为的子数组的LCS值。 更清楚地说 2.)对原始输入数组进行
-
使用工作流程插件多次并发工作
问题内容: 我正在尝试使用工作流插件同时执行一项作业5次。这是代码段: 此代码段导致test_job仅运行一次。我需要同时运行5次。 谢谢! 问题答案: 除了缺乏对脚本错误的诊断之外,这里的工作流中没有错误。在Groovy中,循环计数器是在封闭范围内定义的,并且已被更改,因此在每次关闭运行时,它具有相同的值:5.在Jenkins之外,您可以看到此值以及该修复程序的概念: 在您的情况下,Jenkin
-
threadpoolexecutor中工作线程和工作队列的用途
根据我的理解,ThreadpoolExecitor有两个主要的数据结构(工人,workQueue)用于管理tasks.worker(Set)有线程,这些线程将一直运行到执行器关闭,workerQueue将所有任务保留到执行器。但是根据代码,我没有看到所有任务都被添加到workQ中ueue.task仅在第1361行添加到队列中,不会在每种情况下都执行。
-
没有工作线程时fork-connect有工作要做?
我有一个错误,现在在生产中出现了两次,其中一个分叉/连接池停止工作,尽管它有工作要做并且正在添加更多工作。 这是我到目前为止得出的结论,以解释为什么要执行的任务队列被填满并且任务结果流停止。我有线程转储,其中我的任务生产者线程正在等待fork/连接提交完成,但是没有ForkJoinpool工作线程对此做任何事情。 不管我在做什么,这都不应该发生,对吗?线程转储来自检测到初始条件后的许多小时。我还有
-
多线程如何在Cadence/Temporal工作流中工作?
在Cadence/Temoral工作流编程中: < li >不允许使用本机线程库。例如,在Java中,线程必须通过< code>Async.procedure或< code>Async.function创建,而在Golang中,线程必须通过< code>workflow创建。去吧。那为什么呢? < li >有没有类似使用本机线程的竞争条件?例如,为了线程安全,应该使用< code>Hashtabl