《我要进大厂》专题
-
如何在MySQL上进行SQL区分大小写的字符串比较?
问题内容: 我有一个函数,返回大小写混合的五个字符。如果我对此字符串进行查询,则无论大小写都将返回该值。 如何使MySQL字符串查询区分大小写? 问题答案: http://dev.mysql.com/doc/refman/5.0/en/case- sensitiveivity.html 默认字符集和排序规则为latin1和latin1_swedish_ci,因此默认情况下非二进制字符串比较不区分大
-
线程,进程,然后线程创建有很大开销,怎么优化?
本文向大家介绍线程,进程,然后线程创建有很大开销,怎么优化?相关面试题,主要包含被问及线程,进程,然后线程创建有很大开销,怎么优化?时的应答技巧和注意事项,需要的朋友参考一下 考察点:多线程 可以使用线程池。
-
MySQL中使用innobackupex、xtrabackup进行大数据的备份和还原教程
本文向大家介绍MySQL中使用innobackupex、xtrabackup进行大数据的备份和还原教程,包括了MySQL中使用innobackupex、xtrabackup进行大数据的备份和还原教程的使用技巧和注意事项,需要的朋友参考一下 大数据量备份与还原,始终是个难点。当MYSQL超10G,用mysqldump来导出就比较慢了。在这里推荐xtrabackup,这个工具比mysqldump要快很
-
Java程序以区分大小写的顺序对数组进行排序
本文向大家介绍Java程序以区分大小写的顺序对数组进行排序,包括了Java程序以区分大小写的顺序对数组进行排序的使用技巧和注意事项,需要的朋友参考一下 可以使用java.util.Arrays.sort()方法以区分大小写的顺序对数组进行排序。在这种情况下,此方法仅需要单个参数,即要排序的数组。演示此的程序如下所示- 示例 输出结果 现在让我们了解上面的程序。 首先定义数组arr []。然后打印未
-
如何将大型二进制字符串转换为字节数组Java?
问题内容: 我有一个很大的二进制字符串“ 101101110 …”,并且正在尝试将其存储到字节数组中。最好的方法是什么? 可以说我有largeString =“ 0100111010111011011011000000001000110101” 我正在寻找的结果: [78,187,96,17,21] 01001110 10111011 01100000 00010001 10101 我试过的 但是
-
为什么Rust中没有任意大小的二进制整数类型?
Rust有二进制文字、二进制格式化程序和大量整数类型,但没有显式的二进制数字类型。 的确,在通用机器中,无符号整数的预期实现是一个大/小端二进制数。然而,这与高级语言的语法相去甚远。例如,如果我有一个八位二进制数,我想在语法上把它当作一个基本的数字类型来处理,我有两个问题:(1)数字的字符表示,和(2)数字的类型声明。如果我决定坚持使用,我必须添加一层字符串操作(在Rust中)或一层向量操作(例如
-
如何在C中快速将大缓冲区写入二进制文件?
我正试图将大量数据写入我的SSD(固态驱动器)。我指的是80GB。 我浏览了网页寻找解决方案,但我想出的最好的办法是: 使用Visual Studio 2010编译并进行全面优化并在Windows7下运行,该程序的最大容量约为20MB/s。真正让我困扰的是,Windows可以以150MB/s到200MB/s之间的速度将文件从其他SSD复制到此SSD。所以至少快了7倍。这就是为什么我认为我应该能够走
-
如何从大型xlsx文件中加载pandas数据帧的进度条?
来自https://pypi.org/project/tqdm/: 我获取了这段代码并对其进行了编辑,以便从load_excel创建数据帧,而不是使用随机数: 这给了我一个错误,所以我将df.progress_apply改为: 这是最终代码: 这会产生一个进度条,但它实际上并不显示任何进度,而是加载进度条,当操作完成时,它会跳到100%,从而达到目的。 我的问题是:如何让这个进度条工作? prog
-
LUW DB2用于在IBM大型机上使用DB2进行生产测试
有没有可能,或者有没有人创建了一个过程,通过这个过程,他们使用DB2的LUW实例来进行测试数据、本机和cobol过程,同时实际使用DB2的大型机版本来运行他们的生产软件?也许另一个很好的问题是,这样做会不会是一件聪明的事情? 现在,我们的测试系统问题的一些显而易见的解决方案将是花费资源使大型机更快,或者甚至有一个专用的测试大型机(显然不必那么强大)。但是,正如所有与IBM共事的人都知道的那样,那些
-
Aws在一个GraphQL API中使用多个Cognito用户池进行放大
我是AWS放大器的新成员,我正在尝试制作简单的项目。 我有两个不同的前端(react)项目。其中一个是博客读者,另一个是编辑。对于这两个应用程序,我希望使用相同的DynamoDB表(并使用graphqlapi)。但是我想为每个项目使用不同的用户池。我如何实现这一点? 我在读这篇文章-https://medium.com/@fullstackpho/aws-amplify-multi-auth-gr
-
Gitlab阻止用户在ldap dn中进行区分大小写的判断
当我尝试登录时,用户所在的base_dn是ou=people,dc=dominio,dc=com,所有工作都很好,直到Gitlab进行同步并阻止用户,因为在Gitlab数据库中base_dn是以小写形式保存的。 LDAP帐户“uid=user1,ou=people,dc=dominio,dc=com”不再存在,阻止GitLab用户“usuario”(user1@dominio.com) Gitla
-
如何插入到实现为二叉树的二进制最大堆中?
在作为二叉树实现的二进制最大堆中(其中每个节点存储指向其父节点、左子节点和右子节点的指针),如果有指向堆根的指针,将如何实现插入操作?应该发生的是节点首先作为最后一行的最后一个元素被插入。对于基于数组的实现,您可以添加到数组中,但是对于基于树的实现,您如何找到正确的位置呢?
-
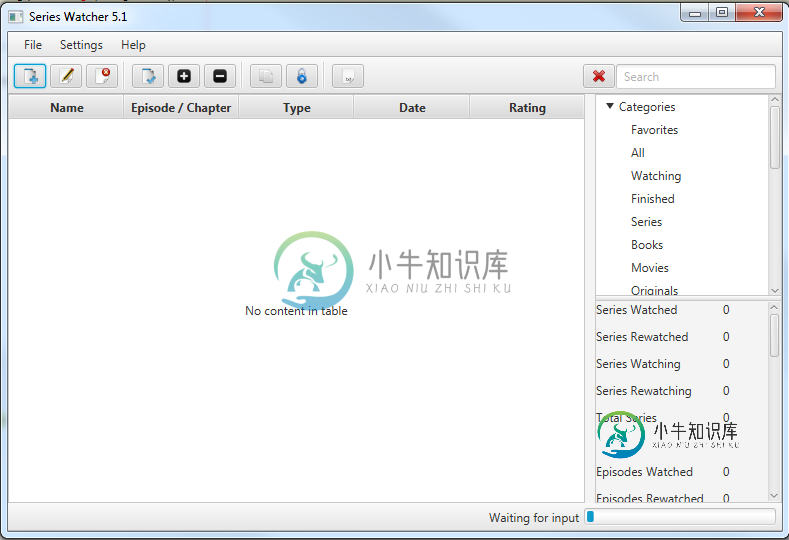 JavaFX 进度条在调整大小后导致严重的窗口滞后
JavaFX 进度条在调整大小后导致严重的窗口滞后问题 我有一个大小适中的javaFX窗口,看起来运行良好,直到我调整应用程序中任何窗口的大小。调整后,具有下拉或类似操作的所有组件(即。,,)变得非常慢。 原因 我已经把问题缩小到一个进度条,如果我从场景中删除进度条,我可以随心所欲地调整窗口大小,如果我添加它,那么任何窗口都会调整大小,它们开始变得没有反应大约半秒钟;如果我做了很多调整大小,有时会长达两秒钟。 窗口 窗口视图,以便您可以看到所有组
-
在mac上使用python子进程获取目录大小而不是OS.Walk
我对python和子流程模块比较陌生。 我正在尝试使用mac OSX上的子进程来获得python的目录大小。os.walk对于大型目录需要很长时间。我希望通过shell命令得到子进程来完成这一操作,并加快结果。这个shell命令对我有效,但我不能从子进程中使它工作? (cd/test_folder_path&ls-nr grep-v“^D”awk“{total+=$5}END{print tota
-
如何根据地图集合值的大小对地图进行排序?