《字节游戏》专题
-
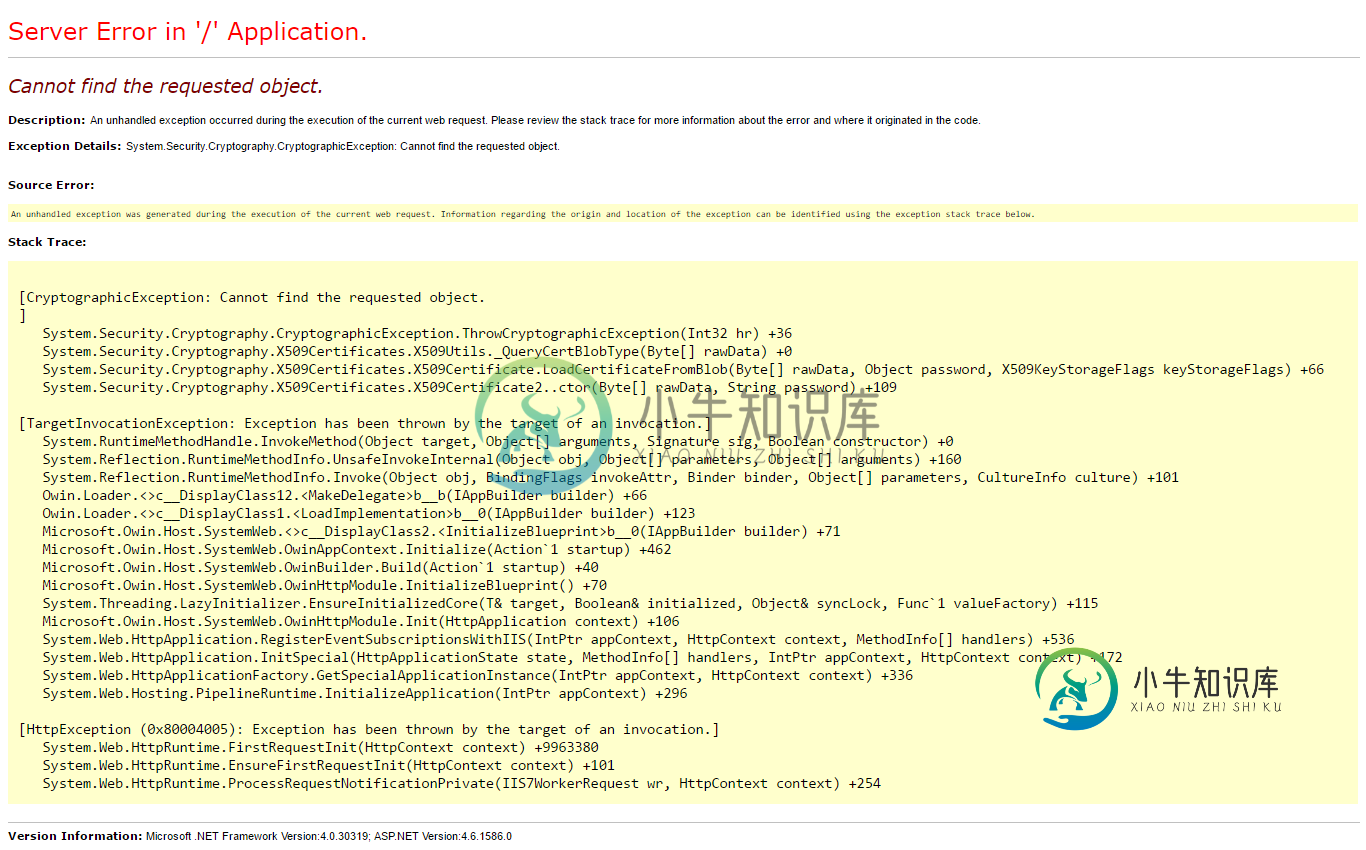 无法从字节数组实例化X509Certificate2
无法从字节数组实例化X509Certificate2我正在尝试使用自签名证书配置IdentityServer3,我使用openssl创建了一个x509证书,如下所示:openssl req-X509-SHA256-Days 365-key key.pem-in CSR.CSR-out certificate.pem然后使用:pkcs12-export-in My-Cert.pem inkey My-Key.pem-out Xyz-Cert.pfx合
-
计算HTTP请求Post的字节大小
我正在使用JMeter测试超文本传输协议服务器并在正文中发送不同大小的负载。我正在发布内容类型的JSON对象并发送非常大的文件,有时是小文件。 在请求中,内容长度会根据我设置的内容而变化,但无论出于何种原因,无论json对象的大小和内容长度的不同值如何,以字节为单位的大小始终是277。为什么字节大小不随发送的正文大小的变化而变化?这会弄乱Jmeter中正在计算的KB/sec值,因为每次消息的字节数
-
Java应用程序中的分配字节
有没有办法找到Java应用程序中分配了多少字节?如果可能,在不更改代码的情况下?谢谢
-
Java中字节移位的怪异行为
为什么在Java中字节的位移位行为是这样的?
-
在c(多字节)中进行hwid登录
大家好,我试图为一个应用程序进行hwid登录。问题是,当我编译所有代码时,我会出现这个错误。 错误C2676二进制“==”:“std::basic\u字符串,std::分配器
-
未知的116字节ECDSA私钥格式
iOS 13的CryptoKit框架为ECDSA公钥和私钥提供了值。我一直在尝试对 反向工程,以便在它和 JWK 之间进行转换。从公钥表示的 64 字节长度来看,它似乎是一个简单的 串联。我猜想私钥将是,但事实似乎并非如此,因为这样做应该产生一个96字节的字符串,而实际的是144字节。它似乎也不是有效的 DER/ASN.1 字符串。我还没有设法找到一个与我得到的实际值一致的规范。 正如你所猜测的,
-
签名字节范围在Acrobat中无效
我正试图使用我们正在制作的库来制作PDF文档的时间戳。我在PDF文档中添加了一个新的部分。我为签名和包含实际签名的签名对象添加了新的注释对象,并为新部分添加了新的外部参照表。当我检查外部参照条目时,一切似乎都正常。 当我尝试在Acrobat中验证我的签名时,我收到以下错误消息“此签名中包含的信息格式存在错误(签名字节范围无效)”。 但是,当我检查字节范围时,一切似乎都是正确的。我从文档的开头到Co
-
JNI:如何从字节数组加载类?
如何从JNI中JAR文件的字节数组加载所有类<我的代码 我需要读取JAR文件的字节,将它们转换成jbytes并从这些字节加载所有java类 比如java中的代码
-
如何仅替换1字节的4位?
我知道我可以在1字节内存储和检索2个4位数字,如下所示: 但是,我如何在不触及最后4位(15)的情况下覆盖这两个数字中的一个(比如第一个(10))?
-
AES解密不工作超过16字节
我在Java中使用AES加密/解密时遇到了一个非常奇怪的问题。如果我加密/解密的字符串小于16字节,则密码可以正常工作,但如果我向密码提供大于16字节的任何内容,则会出现错误“给定最终块未正确填充”。我构建了一些小代码作为示例: 当byte[]消息为“Hello”时,加密/解密工作正常,但当我将其更改为“hellomybabyhellomydright”时,它抛出异常。有人知道我做错了什么吗?
-
C#1D字节数组到2D双数组
我正在处理C#并发队列和多线程在套接字编程TCP/IP 首先,我已经完成了套接字编程本身。这意味着,我已经完成了关于客户机、服务器和通信本身的编码 到目前为止,我已经实现了putting_data到queue1(Thread1)和全部出列(Thread2),其速度大约是700Mbps 我使用两个concurrent_queue的原因是,我希望通信和类型转换工作在后台处理,而不考虑有关控制的主要过程
-
在字节码级别上理解Java8流
为了使之具体化,请考虑下面的示例,在这里我需要查找所有名称中包含“fish”一词的鱼,然后将每个匹配的鱼的第一个字母大写。(是的,我知道哈格鱼不是真的鱼,但我没有匹配的鱼名了。) 对于这两种方法在字节码级别的本质上可能存在的差异,您可能有的任何洞察力都是很好的。一些实际的字节代码就更好了。
-
无法将字节放入scala中的DirectByteBuffer
我最近在scala代码中使用DirectByteBuffer时遇到了一个问题。下面是我的代码。 在整个循环中,ByteBuffer.remance()总是返回40,看起来“put()”调用从未起作用。因此,在执行“get()”时,缓冲区的内容始终为0。 即使get()调用也根本不移动索引。
-
将字节数组转换为 Java 类型
我有一个非常具体的要求。我有一个java应用程序,在这里我必须将字节数组转换为具有int、String等java类型的消息。消息的结构在c中定义如下- 我在java应用程序中收到的是字节数组。我不知道c应用程序是否使用proto缓冲区或任何其他方式来转换为字节数组。但是,如果我逐个字节地解析数组,我可以得到值。例如- 这一行将返回正确的id值(结构中的第一个属性是int)。 我的问题是——如果我为
-
从字节[]实时调整音频音量?
我试图写一个简单的应用程序,播放声音,可以改变音量的声音在任何时候播放。我通过将声音字节数组中的每对字节转换成一个整数,然后将这个整数乘以音量的增加或减少,然后将它们写回为两个字节(即1个样本)。然而,这导致了声音的极度失真。有没有可能我把位移错了?我的声音格式是: 这段代码的基础是:audio:改变字节数组中样本的音量,而asker正试图在其中执行相同的操作。然而,使用了他的问题中的代码(我认为