《求内推同程艺龙》专题
-
oracle在选择内部调用存储过程
问题内容: 我正在处理一个查询(一个SELECT),我需要将此查询的结果插入表中。在进行插入之前,我需要做一些检查,如果所有列都有效,我将进行插入。 该检查是在存储过程中完成的。在其他地方也使用相同的过程。因此,我正在考虑使用相同的过程进行检查。 程序进行检查并插入值都可以。 我试图在SELECT内调用该过程,但是它不起作用。 这种代码不起作用。 我认为可以使用游标完成此操作,但我想避免使用游标。
-
Spring Boot应用程序不提供Web内容
我有Spring Boot Web应用程序,最初是为内部Tomcat服务器构建的(有效)。然后我采用了该应用程序在Web Logic服务器上运行。我的应用程序编译并部署到服务器没有问题,但当它不服务MVC页面时。每次调用都会抛出404错误。从下面的错误看,它看起来像Spring调度程序servlet存在,但甚至区域设置都没有正确设置。我无法弄清楚这里有什么问题或缺失,但当我创建RestContro
-
在应用程序内使用部分地图
是否可以保存谷歌地图的一部分并将其添加到我的应用程序中并显示出来?因为我只需要有限的区域,我不想在应用程序中使用internet连接。或者有可能限制在线地图中的区域?
-
google应用程序引擎软内存错误
在python上的GoogleAppEngine中,我遇到了以下错误:在服务了总共2个请求后,超过了128 MB的软私有内存限制,达到了157 MB。我尝试使用以下命令来解决这个问题。上下文=ndb。获取上下文()和上下文。设置缓存策略(False)。我把这个方法放在appengine\u配置中。py,也在应该处理请求的处理程序中。我想知道是否还有其他地方可以放置这个命令,或者我是否应该总共使用一
-
Android应用程序内存堆持续增长
我一直在我的应用程序中随机(内存溢出)崩溃,所以我开始分析我的堆。我注意到,如果我从活动A到活动B,堆会从27 MB增加到35 MB(由于懒惰加载许多图像)。但是,当我完成()活动B返回到活动A时,堆大小保持不变,即使使用GC操作!! 令人讨厌的是,再次进入活动B会将堆增加到42 MB。我可以这样做,因为五月的时候,堆只会不断增加。 这是我正在使用的惰性图像加载库: LazyListhttps:/
-
制作Java应用程序的“内存转储”?
问题内容: 我有Java应用程序,不幸的是,它在一段时间后开始消耗大量内存。使事情复杂化的是,它不仅是Java应用程序,还是JavaFX 2应用程序。 我怀疑可能存在一些内存泄漏,甚至在底层JavaFX调用和本机库中也是如此。 理想的解决方案是在某个时刻获取所有java对象的转储(及其内存使用情况),然后分析该转储。有什么办法可以做到这一点? 问题答案: 有很多方法可以获取堆转储,从简单的工具(例
-
使用Python的内建模块collections的教程
本文向大家介绍使用Python的内建模块collections的教程,包括了使用Python的内建模块collections的教程的使用技巧和注意事项,需要的朋友参考一下 collections是Python内建的一个集合模块,提供了许多有用的集合类。 namedtuple 我们知道tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成: 但是,看到(1, 2),很难看出这个tuple是用
-
MySQL内存使用之线程独享介绍
本文向大家介绍MySQL内存使用之线程独享介绍,包括了MySQL内存使用之线程独享介绍的使用技巧和注意事项,需要的朋友参考一下 前言 在 MySQL 中,线程独享内存主要用于各客户端连接线程存储各种操作的独享数据,如线程栈信息,分组排序操作,数据读写缓冲,结果集暂存等等,而且大多数可以通过相关参数来控制内存的使用量。 线程栈信息使用内存(thread_stack) 主要用来存放每一个线程自身的标识
-
Tomcat中的Quartz调度程序内存泄漏
我使用石英版和Spring Boot版。它表现正常,一切正常。但是当我试图关闭这个应用程序时,问题出现了。日志显示有内存泄漏... 我的石英配置; 我有两个班,执行如下工作; 另一个班也同样做着不同的事情。 调度器工厂Bean如下; 我得到了像下面这样的tomcat日志; 查阅了quartz文档,并在properties中添加了以下内容:; 第一条线程消息消失了,但关于worker-2的第二条消息
-
通过注释性内部类创建线程
我正在开发创建线程的代码,但没有扩展thread类或实现runnable接口,即通过匿名内部类。。 现在请告诉我,我可以用同样的方法创建子线程吗...!!我尝试的是... 但是其中有两个run()方法,我认为这不实用。。请建议。。!
-
log4j线程上的Tomcat内存泄漏问题
我在log4j v1中面临内存泄漏的问题。如何解决这个内存泄漏问题。此方法是定期检查log4j.properties文件在我的类中的更新。 PropertyConfigutaror.ConfigureandWatch(time_ms); 但是在关机期间,tomcat内存泄漏问题就来了。日志如下: 提前致谢
-
Spark Java:无法更改驱动程序内存
spark-defaults.conf中没有任何内容,以编程方式初始化spark上下文的代码是: 在所有这些之后,Spark UI的Environment选项卡的Spark.driver.maxResultSize为10G,Spark.driver.memory为20G,但是驱动程序的存储内存的executors选项卡显示为0.0B/4.3GB。 (请注意:我以前的Spark.Driver.Mem
-
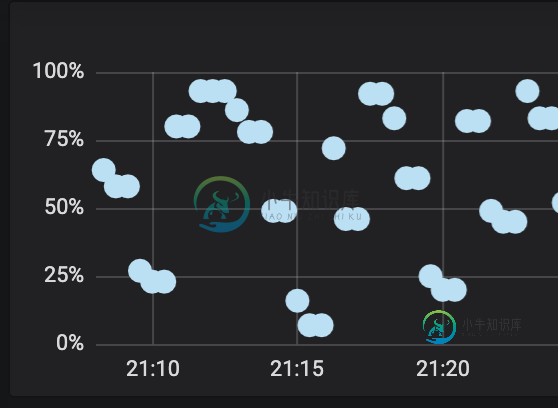 JVM-XMX限制与进程消耗的内存
JVM-XMX限制与进程消耗的内存关于Java应用程序使用的驻留内存,我有两个问题。 一些背景细节: 我用-xms2560m-xmx2560m设置了一个java应用程序。 java应用程序在容器中运行。k8s允许容器最多消耗4GB. 堆:应用程序的工作方式似乎是使用所有内存,然后释放,然后使用等等。 这张快照说明了这一点。Y列是空闲堆内存。(由应用程序通过)提取) 我还可以使用HotSpotDiagnosticMXBean来确认它
-
内存泄漏的java堆和线程分析
我的WebLogic服务器配置了16GB的堆空间,但当大多数用户开始工作时,90%的堆空间在生产使用1小时内就被使用了。我观察到每当这种情况发生时,都有几条线卡住了。 我已经检查了线程转储,没有“等待锁定”对象线程,线程类似于如下所示,线程没有明显的原因被卡住。
-
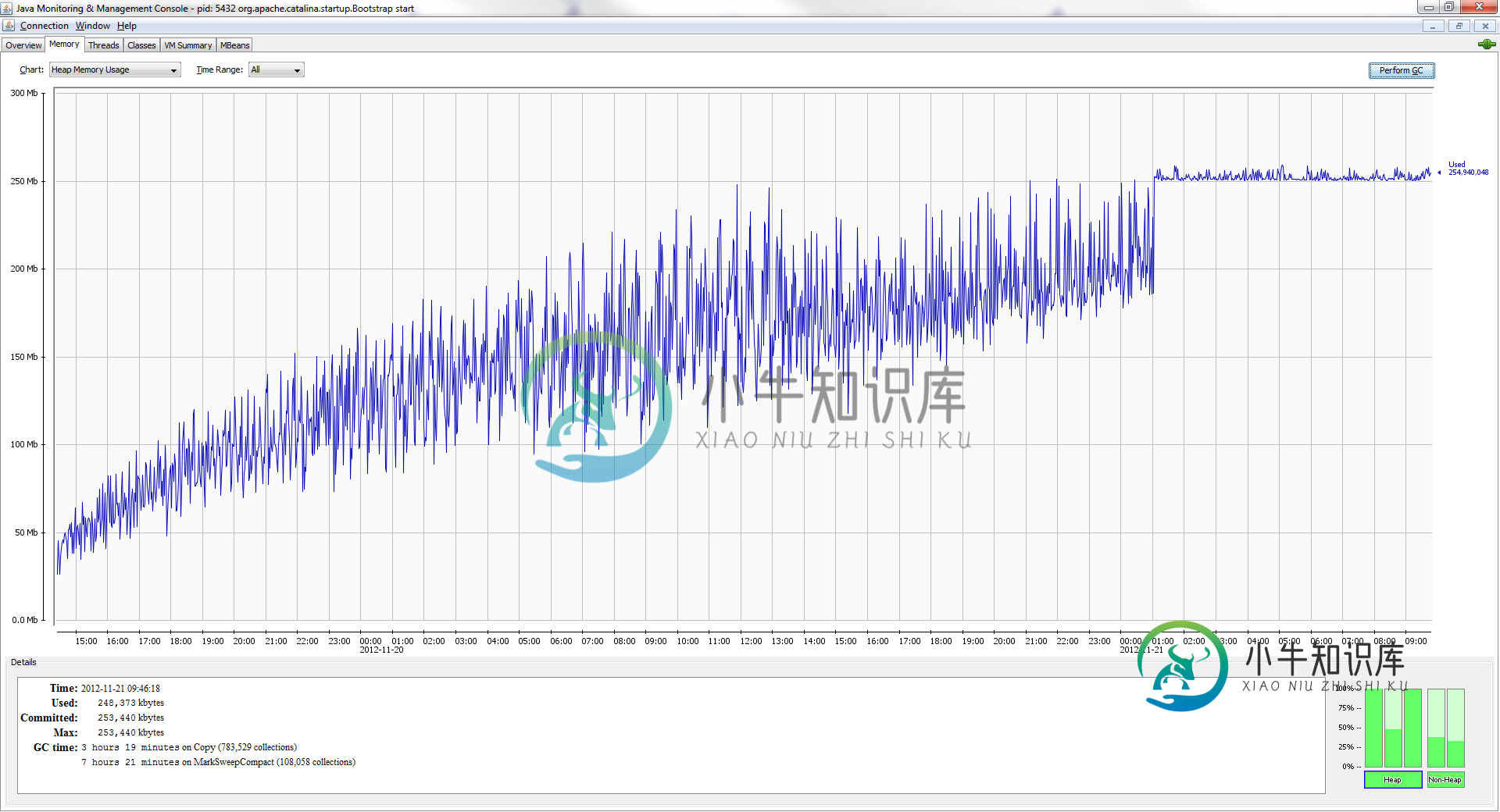 Java web应用程序中的内存泄漏
Java web应用程序中的内存泄漏我有一个运行在Tomcat7上的Java web应用程序出现内存泄漏。在负载下(使用JConsole确定),应用程序的平均内存使用量随时间线性增加。在内存使用达到稳定期后,性能会显著下降。响应时间从大约100ms到[300ms,2500ms],所以这实际上导致了真正的问题。 使用VisualVM,我看到至少一半的内存被字符数组(即char[])使用,而且大多数字符串(每个实例的数量大致相同,为30