《陕西联通》专题
-
 中国联通上海分公司--软件开发
中国联通上海分公司--软件开发2022-11-27 一面: 1.自我介绍 2.对于学前端的规划 3.项目是怎么做的(挖得不深,自由发挥即可) 4.对于工作地点的看法,你是哪里人 5.在校获得过奖学金吗,班级排名多少 6.班上担任什么职务或者参加过学校社团吗(我还蛮爱打篮球所以面试官还问了我身高) 7.如果让你去售前或者客户经理你愿意吗(好巧不巧这两个我之前都投递过,就说了说我对这两个岗位的看法) 没了,然后说后续关注公众号可以
-
如何通过多个联接加快MySQL查询
问题内容: 这是我的问题,我正在选择并执行多个联接以获取正确的项目…它吸引了相当多的行,超过100,000。当日期范围设置为1年时,此查询将花费5分钟以上的时间。 我不知道是否可能,但恐怕用户会将日期范围扩展到10年左右并使其崩溃。 有人知道我可以如何加快速度吗?这是查询。 我不是MySQL方面的佼佼者,因此不胜感激! 提前致谢! 更新 这是您要求的解释 我还为table5行和table4行添加了
-
通过一对一关联连接spring data jpa表
我试图通过使用spring data JPA一对一关联来连接两个表并显示其结果。下面我要添加我的模型和存储库类,我的第一个模型类用户是, 而我需要加入的下一个模型类是: “意外标记:来自第1行附近的第74列[SELECT u.username FROM com.central.model.users u inner join p.privi_name FROM com.central.model.
-
使用bot将内联消息发送到通道
是否可以通过机器人自动向频道发送
-
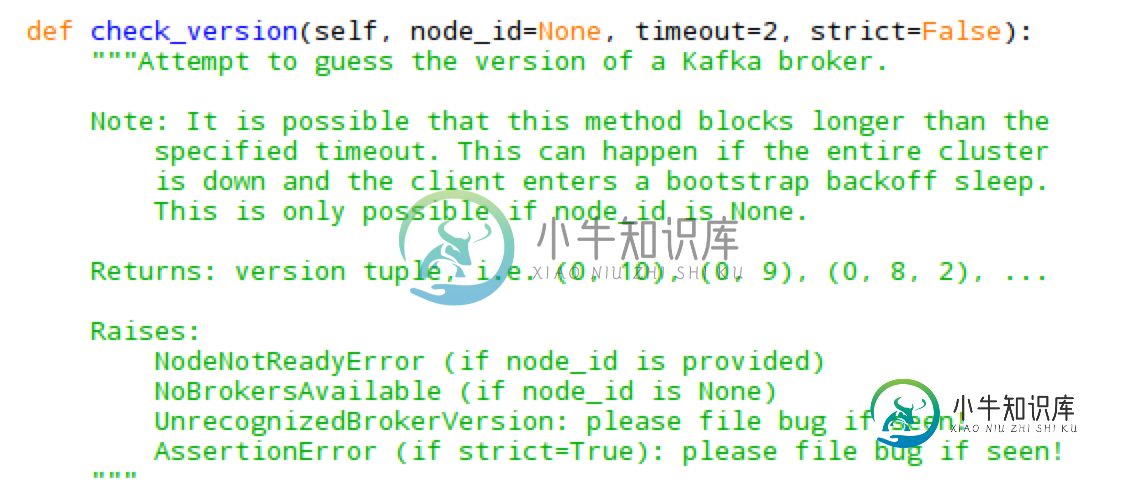 无法通过node red联系到Kafka制作人
无法通过node red联系到Kafka制作人我已经在覆盆子pi 3上安装了node-red来从传感器收集数据,然后将它们存储在kafka中,但是现在我对kafka生产者节点有一些问题。我在笔记本电脑上安装了一个kafka服务器,它可以在控制台上正确工作:如果我在kafka生产者控制台上发送消息,我可以在消费者控制台上正确接收。不幸的是,当我试图在覆盆子上的node-red中注入kafka生产者的时间戳时,服务器没有响应。 node red的
-
 深圳联通-大数据分析-一面二面
深圳联通-大数据分析-一面二面一面 10.12 10min 一个面试官,主要挖简历。 好长时间没消息我都以为g了,又收到了二面通知 二面 10.31 10min 一个面试官,挖简历+期望薪资+家是哪的,为啥来深圳等 一面面试官有点丧丧的,感觉好困好困。二面的面试官很和蔼,戴口罩也能看出来全程笑嘻嘻的。 不知道是不是KPI,有没有后续。 #广东联通##深圳联通##面试#
-
 北京联通 大数据运营支撑 面经
北京联通 大数据运营支撑 面经2.9上午面试,时间不到9min 1、自我介绍(1min) 2、英文回答平时怎么学习(措手不及-答得很烂) 3、情景题 4、投递贵公司最看重的三个因素 5、希望税前月薪 6、接受其他岗位调剂吗 7、北京户口有需求吗 疑问:这次面试是秋招补录还是春招?有同一天面试的同学了解情况的能说说吗,如果有后续消息麻烦告知下lz 更新: 2.14 下午收到签约会通知 #春招# #联通面试# #国企#
-
 小米物联网通信平台开发文档
小米物联网通信平台开发文档本教程主要围绕物联网整体概述,小米移动物联网管理平台,客户服务,API文档,品质保障,用户服务,合作案例,安全SIM卡,通信模组以及eSIM几个方面进行介绍。
-
 联通数科 后端开发工程师 笔试
联通数科 后端开发工程师 笔试投递岗位:后端开发工程师(西安) 投递base:西安 投递时间线:9.19投递,10.20收到笔试邀请链接,10.23笔试 考试内容:固定时间19:00-20:10,4部分,使用国考平台,除了编程其它都部分提交完不可修改。 1.行测数学:10道,类似行测里的数学计算,感觉更简单一点,排列组合更多更难一点。 2.单选:45道,涉及数据库,计算机网络,操作系统,java语言基础,数据结构等等,有难度,
-
 山东联通省产互-数据挖掘面经
山东联通省产互-数据挖掘面经1.自我介绍 2.深挖简历 3.询问移动实习经历 4.询问贝壳数据分析项目 面完说岗位竞争比较大,问想去市公司吗?直接拒绝
-
 浙江联通24校招数据运营面经
浙江联通24校招数据运营面经👥 面试题目 投递渠道:国聘 投递到收到一面过了一个多月,两轮面试大约间隔了一周; 一面(2v1;15min) 1. 自我介绍 2. hr:挖了一下实习,你对业务有更多了解的例子 3. 专业面试官:说了好几个块,云计算、数分...问我更擅长哪个 4.hr:看我是陕西人,为啥想来杭州 5. 反问:我们的业务场景大致是怎样 二面(3v1;15min,原本计划20min) 1. 自我介绍 2. 为什么
-
 联通数字科技二面(六个面试官)
联通数字科技二面(六个面试官)先进行自我介绍,主要问了一下的内容: 1、然后问了我研究生阶段的研究课题,对于多模态的理解、以及发表论文里面模型的架构; 2、实习阶段是测试开发工程师,那么对于测试人员,你认为什么时候介入这个流程比较好,为什么; 3、在学校阶段和实习阶段基本都是偏向软件的,为什么选择云平台运维工程师这个岗位; 4、对于Docker和虚拟机两者的一个区别是什么; 5、Docker在不同CPU上如何进行迁移;
-
 联洲 提前批线下终面 通信算法
联洲 提前批线下终面 通信算法1.自我介绍 2.本科成绩,家庭情况 3.项目介绍 4.论文 专利介绍 5.兴趣爱好 6反问 面试官挺和蔼的,一边问也会一边记录,差不多面了三十分钟,然后半小时后发心理测评,目前座谈会待安排
-
使用复杂关联表连接JPA实体,而不创建关联实体?
我正在尝试使用一个不是很简单的关联表在两个JPA实体之间进行ManyTo许多连接。我想知道是否有一种方法可以在不创建关联表实体的情况下实现这一点(类似于使用@JoinTable)。 表A-ID(PK) -名称 表b -ID(PK) -名称 TableMapping-ID(PK) -Parent\u ID(FK)-- 映射以我上面描述的方式存储,原因我不知道,也无法更改。很多地方都在这样使用它,我必
-
JPA/Hibernate左联接提取延迟异常,因为联接的实体为空
最初,我在supervisor字段上用注释了我的Employee实体,但这导致实体管理器生成大量SQL调用,从而降低了应用程序的性能。JPA/Hibernate查询速度慢,查询太多 是我的Employee实体上缺少了一些将填充空主管的构造函数,还是对我的查询进行了一些修改,将像注释那样执行,而不需要大量的单独SQL调用?