《数据分析科学实习》专题
-
Firebase实时数据库-数据检索
-
实时数据的Cassandra数据建模
我目前有一个应用程序,它将事件驱动的实时流数据持久化到一个列系列,该系列建模为: 每个帐户ID每X秒发送一次数据,因此我们每次收到事件时都会覆盖现有行。此数据包含当前实时信息,我们只关心最近的事件(不使用旧数据,这就是我们插入已经存在的键的原因)。从应用程序用户端-我们通过account_id语句查询选择。 我想知道是否有更好的方法来模拟这种行为,并查看了Cassandra的最佳实践和类似的问题(
-
 Firebase实时数据库过滤数据
Firebase实时数据库过滤数据所以我正在制作约会应用程序,现在我需要为用户创建一个匹配的人员列表。 因此,我需要一个firebase查询来查看性别,并检查是否已经匹配,如果匹配,则不应将其包括在列表中。 我试着按性别过滤数据。如何编辑此查询以检查它们是否已匹配?匹配项显示在用户/{userID}/Matches/{matchedUserID}中 这是我尝试的:
-
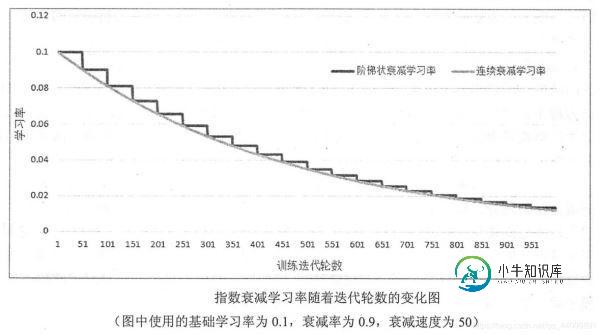 TensorFlow实现指数衰减学习率的方法
TensorFlow实现指数衰减学习率的方法本文向大家介绍TensorFlow实现指数衰减学习率的方法,包括了TensorFlow实现指数衰减学习率的方法的使用技巧和注意事项,需要的朋友参考一下 在TensorFlow中,tf.train.exponential_decay函数实现了指数衰减学习率,通过这个函数,可以先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减小学习率,使得模型在训练后期更加稳定。 tf.train.
-
数据库设计一个功能学校的简单数据库
因此,我在为我的数据库提出实体关系时遇到了一些麻烦,但是我已经完成了一些设计过程,并且是最低口径的。将创建数据库,以便学生可以有许多课程的许多对许多关系(显然我知道)。数据库需要每天跟踪家庭作业和出勤率。但是,课程可以只是一周中的一天或许多天。 顾问- 学生- 课程- 学生课程- 这里我陷入了困境,我想创建一个日历表,但我如何将数据关联到作业表和出勤率。如有任何建议,欢迎批评指正。
-
Azure机器学习工作室:无法从AzureSQL数据库创建数据存储
我正在尝试从 Azure 机器学习工作室内部连接到 Azure SQL 数据库。根据 https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.datastore.datastore?view=azure-ml-py,建议的模式似乎是使用Datastore.register_azure_sql_database方法创
-
 信也科技商业分析师(算法模型方向)笔试
信也科技商业分析师(算法模型方向)笔试时间1.5 h 题型: 💦3道单选题 是关于概率和python编程的 💦1道多选题 比较简单 💦8道问答题 有Python sql 代码可以自己选择 内容大概和算法模型相关,也有 基础概率 是完成一类型题目后才可以做下一类型题目 希望能有好运发生吧!给孩子份offer吧?
-
使用Selenium-WebDriver/RC分析图形数据内容。无法捕获MouseOver上显示的数据
你能告诉我,我可能做错了什么,以及如何处理这件事吗?
-
Elasticsearch分析百分比
问题内容: 我正在使用Elasticsearch 1.7.3累积用于分析报告的数据。 我有一个包含文档的索引,其中每个文档都有一个名为“ duration”的数字字段(请求花费了几毫秒)和一个名为“ component”的字符串字段。可能有许多具有相同组件名称的文档。 例如。 我想生成一份报告,说明每个组件: 此组件的所有“持续时间”字段的总和。 此总和在 所有 文档的总期限中所占的百分比。在我的
-
主成分分析 PCA
目录 综述 01 使用梯度上升法求解主成分 demean 梯度上升法 02 获得前n个主成分 03 从高维数据向低维数据的映射 04 scikit-learn中的PCA 05 使用PCA降噪 手写识别例子 人脸识别 06 特征脸 特征脸 综述 “明道若昧;进道若退;夷道若颣;大方无隅;大器免成;大音希声;大象无形。” 本文采用编译器:jupyter 主成分分析 是一个非监督的机器学习算法
-
在Pandas数据框中转换分类数据
问题内容: 我有一个具有此类数据的数据框(列过多): 列看起来像这样: 我想像这样将列中的所有值转换为整数: 我通过以下方法解决了这一问题: 现在,我的数据框中有两列-旧列和新列,需要删除旧列。 那是不好的做法。它是可行的,但是在我的数据框中有很多列,我不想手动进行。 pythonic如何巧妙地实现呢? 问题答案: 首先,要将“分类”列转换为其数字代码,可以使用以下命令更轻松地做到这一点。 此外,
-
Spring数据可分页breaking Spring数据JPA OrderBy
我有一个简单的JpaRepository和一个finder,它返回按名为“number”的属性降序排列的记录。“number”属性也是我的实体的@Id。这很好,但是有数千条记录,所以我想返回一个页面而不是列表。 如果我将查找器更改为以下内容,则排序不再起作用。我尝试过使用可分页参数的排序功能,但不起作用。还删除了OrderByNumberDesc,但结果相同。 EDIT-添加控制器方法 以下是我的
-
Spring数据R2DBC如何查询分层数据
我是反应式编程的新手。我必须开发一个简单的Spring启动应用程序来返回一个json响应,其中包含公司及其所有子公司和员工的详细信息 创建了一个Spring Boot应用程序(Spring Webflow Spring data r2dbc) 使用以下数据库表来表示公司和子公司以及员工关系(这是一种与公司和子公司的层次关系,其中一个公司可以有N个子公司,而这些子公司中的每个子公司可以有另N个子公司
-
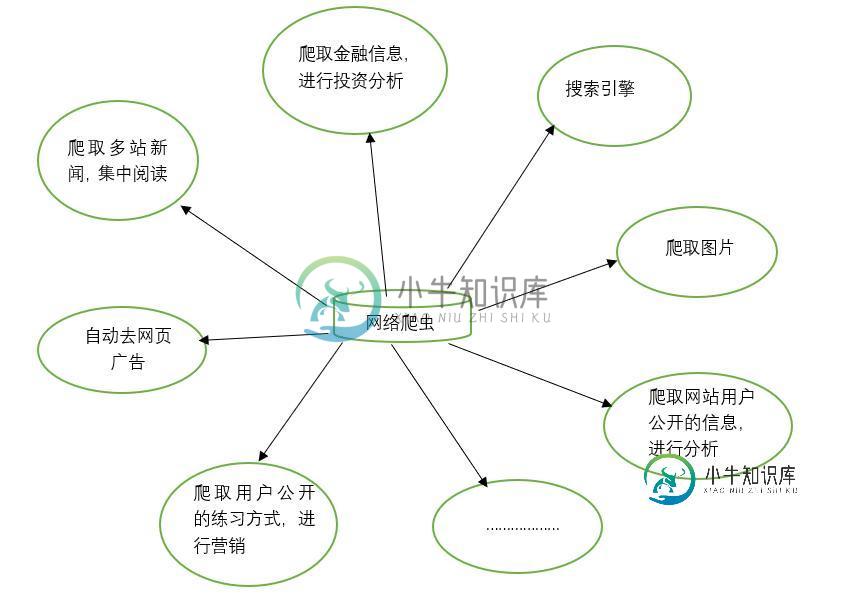 python爬虫爬取网页数据并解析数据
python爬虫爬取网页数据并解析数据本文向大家介绍python爬虫爬取网页数据并解析数据,包括了python爬虫爬取网页数据并解析数据的使用技巧和注意事项,需要的朋友参考一下 1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。 只要浏览器能够做的事情,原则上,爬虫都能够做到。 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以
-
android Refitfit无法解析数据,将数据变为空
回调类APIInterface 得到回应